GBDT&&XGBOOST
都属于GBM(GradientBoosting Machine)方法,传统GBDT以CART(分类回归树)作为基分类器,利用损失函数的负梯度方向在当前模型的值作为残差的近似值,可以说在RF的基础上又有进一步提升,能灵活的处理各种类型的数据,在相对较小的调参时间下,预测的准确度较高。
XGBOOST基学习器除了树,还支持线性分类器;XGBOOST在代价函数中加入了正则项,用于控制模型的复杂度,防止模型过拟合,当正则项系数为0时与传统的GBDT目标函数相同;XGBOOST支持并行计算(特征排序为block结构,可以运行在MPI和YARN上,自动调用CPU多线程进行并行计算),适合处理大数据;支持列抽样,防止过拟合,减少计算;XGBOOST有shrinkage(缩减)策略,相当于学习速率;XGBOOST用到了二阶导,GBDT只用到一阶导(联想梯度下降和牛顿法);XGBOOST增加了缺失值处理方案,自动学习分裂方向,GBDT的求解不断寻找分割点,将样本集进行分割,分配到分裂开的子节点上,选择依据是减少Loss,用于加速和减小内存消耗。XGBOOS可以通过求函数极值点(求导)的方式获得最优解析解,GBDT用梯度下降法迭代求解XGBOOST实现利用了分块、预取、压缩、多线程协作的思想。
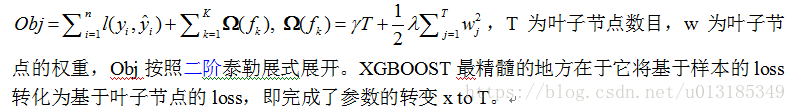
GBDT模型的参数:n_estimators:最大弱学习器的个数;learning_rate:弱学习器的权重缩减系数,步长;subsample:不放回子采样,(0,1];init:初始化时候的弱学习器;loss:GBDT模型的损失函数,分类有对数似然损失函数和指数损失函数两种选择,回归有均方差ls,绝对损失lad,huber损失,分位数损失等;alpha:做回归时才有的分位数值。max_features:划分时最大特征数;max_depth:决策树最大深度(10-100常用);min_samples_split:内部节点再划分所需最小样本数;min_samples_leaf:叶子节点最少样本数;min_weight_fraction_leaf:叶子节点最小的样本权重和;max_leaf_nides:最大叶子节点数;min_impurity_split:节点划分最小不纯度(默认1e-7)。
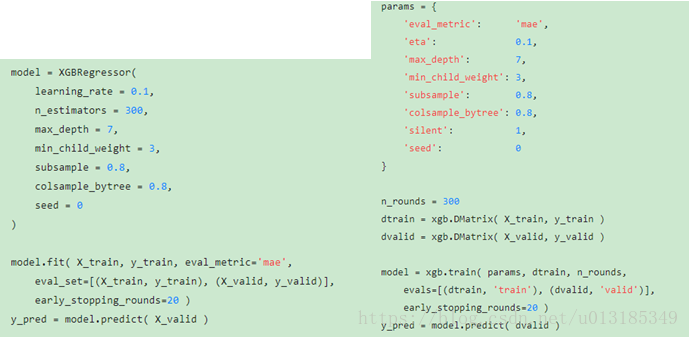
XGBOOST模型的参数:通用参数booster: gbtree和gblinear;silent:0/1,默认为0;nthread:默认为最大可能的线程数。
Booster参数:eta学习率,类似于learningrate,默认0.3;min_child_weight最小叶子节点样本权重和,用于避免过拟合,默认为1;max_depth:决策树的最大深度,用于避免过拟合,默认为6;max_leaf_nodes:树上最大的节点或叶子的数目;gamma:节点分裂所需最小损失函数下降值,默认为0;max_delta_step:每棵树权重改变的最大步长,默认为0;subsample:随机采样的比例,默认值为1;colsample_bytree:随机采样列数的占比,默认为1;colsample_bylevel:树的每一级分裂,列数采样的比例,默认为1;lambda:L2正则化项系数,默认为1;scale_pos_weight:样本类别不均衡时设置为正值可以加快算法的收敛,默认值为1。
学习目标参数:objective:损失函数类型,有binary二分类(logistic),multi多分类(softmax),默认linear;eval_metric:评价指标,有MSE,MAE,RMSE,ERROR,AUC等;seed:随机数的种子,可以复现随机数据的结果,默认为0。
RF
集成学习根据基学习器的生成方式,可分为两大类:即基学习器之间存在强依赖关系,必须串行生成的序列化方法;基学习器之间不存在强依赖关系,可同时生成的并行化方法,前者的代表是Boosting,后者的代表是Bagging和RF。
RF:Random Forest是Bagging的扩展变体,以决策树为基学习器,在决策树的训练过程中引入了随机特征选择,可概括为四部分:随机选择样本、随机选择特征(从样本集的特征集合中随机选择部分特征)、构建决策树、随机森林投票。RF每棵决策树都最大可能的进行生长而不剪枝,在对预测输出进行结合时,RF通常对分类问题使用简单投票法,回归问题使用简单平均法。RF和Bagging的对比:RF的起始性能较差,随着学习器数目增多,随机森林通常会收敛到更低的泛化误差,使用随机性选择的特征,训练效率高。噪声较大时容易产生过拟合。