博主在之前的博客当中介绍过利用决策树处理回归和分类的问题(基于CART的回归和分类任务),决策树解释性好但是模型方差较大,且容易过拟合。在本篇博客中,博主打算对常用的集成学习进行介绍,主要注重模型的思想和解决的问题。
1 集成学习概述
1.1 主流算法
集成学习(Ensemble Learning) 在机器学习算法中具有较高的准去率,不足之处就是模型的训练过程可能比较复杂,效率不是很高。目前集成学习主要有2种:基于 Boosting 的和基于 Bagging,前者的代表算法有 Adaboost、GBDT、XGBOOST 等、后者的代表算法主要是随机森林(Random Forest)。
1.2 主要思想
集成学习的主要思想训练多个弱分类器,然后将多个分类器进行组合预测。核心思想就是如何训练处多个弱分类器以及如何将这些弱分类器进行组合。实现的思路如下图所示:
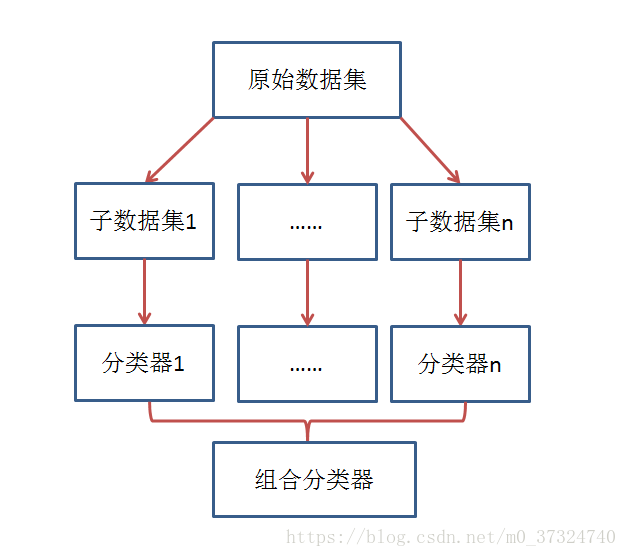
组合分类器性能通常是优于单个分类器的,但是需要满足两个条件:
- 基分类器之间应该相互独立(至少相关性不高)
- 基分类器应该好于随机猜测分类器(在二分类中应该高于0.5的准确率)
但是基分类器是为了解决同一个问题而训练出来的,显然彼此间很难独立,因此根据基分类器的生成方式集成学习又可以分为两大类:
- 基分类器之间有较强的依赖关系,串行生成序列,如 Boosting
- 基分类器之间的依赖关系不强,并行生成序列,如 Bagging
2 各类算法
2.1 Bagging 算法
Bagging(装袋)又称为自助聚集(bootstrap aggregating),它得到不同数据集的方式是均匀的概率从训练集中重复的抽样,一般来说自助样本的包含设63%的原始训练数据。
Bagging 通过降低基分类器的方差改善了泛化误差。
需要注意的是,如果基分类器实不稳定的,bagging有助于减少训练数据的随机波动导致的误差,如果基分类器实问题定的,即对训练数据集中的微小变化是鲁棒的,则组合分类器的误差主要有基分类器偏移所引起的,这种情况下,bagging可能不会对基分类器有明显的改进效果,甚至可能降低分类器的性能。
2.1.1 Random Forest
随机森林是 Bagging 的扩展,实质是专门为决策树分类器设计的一种组合方法,在分类问题中采用投票表决;在回归问题中采用的是取平均值。随机森林有两个随机过程:
- 随机有放回的采样,和 Bagging 一样
- 随机从 m 个特征中选择 n 个特征用于决策树的训练 (通常 n=
)
随机森林相比于决策树没有剪枝的过程,然而正因为两个随机的过程,对树的操作实现了去相关。其性能要高于决策树。
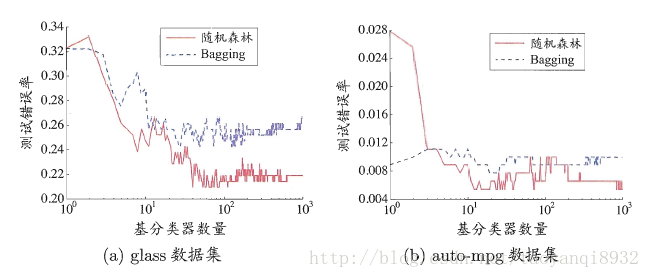
在基分类器较少的时候性能可能不如 Bagging 方法(毕竟随机森林加入了特征干扰), 然而随着树的增加,其效果会好于 Bagging,如下图:
2.2 boosting 算法
Gradient Boosting(梯度提升)是一种集成弱学习模型的机器学习方法。又叫 MART(Multiple Additive Regression Tree),是一种迭代的决策树算法,该算法由多棵决策树(确切的说是回归树)组成,所有树的结论累加起来做最终答案。
2.2.1 GBDT (Gradient Boosting Decision Tree)
GBDT,又叫 MART(Multiple Additive Regression Tree),是一种迭代的决策树算法,该算法由多棵决策树(确切的说是回归树)组成,所有树的结论累加起来做最终答案。GBDT的核心就在于,每一棵树学的是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量。
下面用个简单的例子说明。
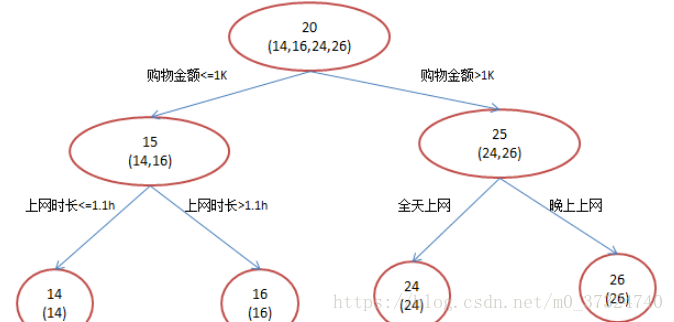
训练集是4个人,A,B,C,D年龄分别是14,16,24,26。样本中有购物金额、上网时长、经常到百度知道提问等特征。现在用决策树模型和 GBDT模型。
- 决策树模型
训练过程如下图:
- GBDT 模型
训练过程如下图:

A: 14岁高一学生,购物较少,经常问学长问题;预测年龄A = 15 – 1 = 14
B: 16岁高三学生;购物较少,经常被学弟问问题;预测年龄B = 15 + 1 = 16
C: 24岁应届毕业生;购物较多,经常问师兄问题;预测年龄C = 25 – 1 = 24
D: 26岁工作两年员工;购物较多,经常被师弟问问题;预测年龄D = 25 + 1 = 26
看到这里,你可能会有下面的问题:
- 哪里体现梯度?
以误差作为衡量标准,残差向量(-1, 1, -1, 1)都是它的全局最优方向,这就是Gradient。
- 既然最后的结果是一样的,为什么用 GBDT模型?
为了防止过拟合。决策树模型为了达到100%精度使用了3个feature(上网时长、时段、网购金额),其中分枝“上网时长>1.1h” 很显然已经过拟合了,这个数据集上A,B也许恰好A每天上网1.09h, B上网1.05小时,但用上网时间是不是>1.1小时来判断所有人的年龄很显然是有悖常识的。
- 既然用残差作为负梯度是一个特例,那么通用的算法步骤是如何的?
首先进行如下说明,当损失函数时平方损失和指数损失函数时,每一步的优化很简单,如平方损失函数学习残差回归树。

但对于一般的损失函数,往往每一步优化没那么容易,如上图中的绝对值损失函数和Huber损失函数。针对这一问题,Freidman提出了梯度提升算法:利用最速下降的近似方法,即利用损失函数的负梯度在当前模型的值,作为回归问题中提升树算法的残差的近似值,拟合一个回归树。
具体算法遵循以下的步骤:
1、初始化,估计使损失函数极小化的常数值,它是只有一个根节点的树,即ganma是一个常数值。
2、重复以下步骤:
(a)计算损失函数的负梯度在当前模型的值,将它作为残差的估计
(b)估计回归树叶节点区域,以拟合残差的近似值
(c)利用线性搜索估计叶节点区域的值,使损失函数极小化
(d)更新回归树
3、得到输出的最终模型 f(x)
2.2.2 Adaboost(Adaptive boosting )
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。其原理如下图:
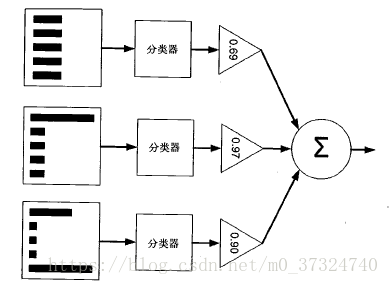
Adaboost 算法示意图(左边的是数据集,直方图的不同宽度表示每个样例上的不同权重
在经过一个分类器之后,加权的预测结果会通过三角形中的数值进行加权,在后一步的
圆形框中求和,得到最后的结果)
算法过程遵循以下的步骤(主要在于每个分类器中样本权重的更新和每个分类器中样本权重的更新):
- 对于每个分类器,赋予分类器中样本 i 的权重为 Di (初始权重等值)
- 第一次在训练的时候得到每个分类器的分类错误率:
- 第二次训练的时候,更新每个分类器的权重α,
,更新每个分类器中样本的权重Di(如果样本正确分类,则样本的权重更新为:
;如果样本错误分类,则样本的权重更新为:
),正确分裂的样本权重降低,错误分类的样本权重增大
- 重复步骤3,直到分类器的错误率为0或者达到设定值

3 各自特点
Bagging 模型降低方差, Boosting 模型降低偏差。
事实上,就机器学习算法来说,其泛化误差可以分解为两部分,偏差(bias)和方差(variance),如下公式:
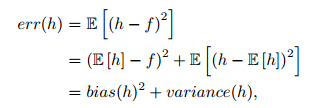
偏差指的是算法的期望预测与真实预测之间的偏差程度,反应了模型本身的拟合能力;方差度量了同等大小的训练集的变动导致学习性能的变化,刻画了数据扰动所导致的影响。
当模型越复杂时,拟合的程度就越高,模型的训练偏差就越小。但此时如果换一组数据可能模型的变化就会很大,即模型的方差很大。所以模型过于复杂的时候会导致过拟合。当模型越简单时,即使我们再换一组数据,最后得出的学习器和之前的学习器的差别就不那么大,模型的方差很小。还是因为模型简单,所以偏差会很大,如下图:

对于Bagging算法来说,由于我们会并行地训练很多不同的分类器的目的就是降低这个方差(variance) ,因为采用了相互独立的基分类器多了以后,h的值自然就会靠近
。所以对于每个基分类器来说,目标就是如何降低这个偏差(bias),所以我们会采用深度很深甚至不剪枝的决策树(随机森林模型不需要剪枝)。
对于Boosting来说,每一步我们都会在上一轮的基础上更加拟合原数据,所以可以保证偏差(bias),所以对于每个基分类器来说,问题就在于如何选择variance更小的分类器,即更简单的分类器,所以我们选择了深度很浅的决策树。
参考资料:
https://en.wikipedia.org/wiki/Gradient_boosting
https://www.jianshu.com/p/005a4e6ac775
https://www.zhihu.com/question/45487317/answer/99153174
《统计学习导论——基于R的应用》
《机器学习实战 》
《机器学习》周志华