摘要
卷积网络认为图像是带有规则形状的有组织的像素点,通过卷积操作对局部区域进行特征提取。ViTs 把图像认为是块的序列,通过注意力机制在全局范围内进行特征提取。我们提出了一种不同于 ConvNets 和 ViTs 的特征提取结构 Contetx clusters (CoCs)
引言
CoCs 把图片视为无组织的点的集合,通过简单的聚类算法进行特征提取。具体来说,每个点包含原始特征(比如颜色等等)和位置信息(坐标), 通过利用简单的聚类算法可以分层次地去组织和提取深层特征。不需要卷积和注意力,仅仅依靠聚类算法进行空间交互。由于设计简单,通过对聚类过程的可视化,有令人满意的可解释性。致力于为图像和视觉表现提供了一个新的视角,它可以在不同的领域得到广泛的应用,并表现出深刻的见解。尽管我们不以 SOTA 性能为目标,但在几个基准测试中,coc 仍然获得了与 ConvNets 或 ViTs 相当甚至更好的结果。
虽然卷积和视觉注意力在图像识别上取得了非常好的效果,但是为了避免陷入追求增量改进的陷阱,并且它们对于特征提取也并不是唯一的选择。以 MLP 为基础的结构证明了基于纯 MLP 的设计也可以实现差不多的性能。除此之外,将图网络作为特征提取器被证明是可行的。因此,我们期待一种新的特征提取范式,它可以提供一些新颖的见解,而不是渐进式的性能改进。
在这项工作中,我们回顾了经典算法中最基本的视觉表示、聚类方法。总体而言,我们将图像视为一组数据点,并将所有点分组为聚类。在每个聚类中,我们将这些点聚集成一个中心,然后自适应地将中心点分配给所有的点。我们称之为上下文集群设计。图1说明了该过程。

具体来说,我们将每个像素视为一个具有颜色和位置信息的5维数据点。在某种意义上,我们将图像转换为一组点云,并利用点云分析的方法用于图像视觉表示学习。 它联系了图像的表示和点云,显示出强大的泛化能力,并为轻松融合多模式提供了可能性。对于一组点,我们引入了一种简化的聚类方法,将点分组为聚类。聚类处理与SuperPixel 有相似的思想,相似的像素被分组,新设计本质上不同ConvNets或vit,但我们也继承了它们的一些积极理念,包括ConvNets的层次表示和ViTs的Metaformer框架。通过可视化每一层的聚类,我们可以明确地理解每一层的学习。尽管我们的方法不以SOTA性能为目标,但在几个基准测试中,它仍然达到了与ConvNets或ViTs相同甚至更好的性能。我们希望我们的语境集群能为视觉界带来新的突破。
相关工作
图像处理中的聚类 虽然图像处理中的聚类方法在深度学习时代已经不再流行,但它们从未从计算机视觉中消失。SuperPixel通过将一组具有共同特征的像素分组,将图像分割成区域。考虑到所需的稀疏性和简单的表示,SuperPixel已经成为图像预处理的常用实践。
SuperPixel 在整个图像上穷尽聚类 (例如,通过 K-means 算法) 像素,使得计算成本很高。为此,SLIC 将聚类操作限制在局部区域,并均匀初始化 K-means 中心,以便更好更快地收敛。近年来,聚类方法受到了极大的关注,并与深度网络紧密结合。为了为深度网络创 SuperPixel,SSN 提出了一种可微分的 SLIC 方法,该方法是端到端可训练的,并且具有良好的运行时。
最近,将聚类方法应用到特定视觉任务的网络中,如分割和细粒度识别。例如,CMT-DeepLab 将分割任务中的对象查询解释为聚类中心。分组像素被分配到每个集群的分割。然而,据我们所知,还没有通过聚类进行一般视觉表示的工作。我们的目标是弥补空缺,同时在数值和视觉上证明可行性。
ConvNets & ViTs 自深度学习时代以来,ConvNets一直主导着视觉界。最近,ViTs 向视觉界引入了纯基于注意力的Transformer,并在各种视觉任务上达到了新的SOTA性能。一种常见且貌似合理的猜想是,这些令人欣慰的成就归功于自我关注机制。然而,这个直观的猜想很快就受到了挑战。大量的实验也表明,ResNet可以实现与ViTs相同甚至更好的性能,只需适当的训练配方和最小的修改。我们强调,虽然卷积和注意力可能有独特的优点,而ViTs擅长泛化,但它们并没有表现出显著的性能差距。与卷积和注意力不同的是,本文从根本上提出了一种基于聚类算法的视觉表示的新范式。通过定量和定性分析,我们表明,我们的方法可以作为一个新的总主干,并具有令人满意的可解释性。
最新进展 在ConvNets和ViTs框架内,人们已经做出了广泛的努力来提高视觉任务的性能。为了同时利用卷积和注意力,一些工作以混合模式混合这两种设计,如CoAtNet 和Mobile-Former 。我们也注意到最近的一些进展探索了更多的视觉表示方法,而不仅仅是卷积和注意力。类MLP模型直接考虑空间相互作用的MLP层。此外,一些工作采用移位或池化用于局部通信。与我们将图像视为无序数据集的工作类似,Vision GNN (ViG) 为视觉任务提取图级特征。与传统的图像处理方法不同的是,我们直接应用聚类方法,具有良好的泛化能力和可解释性。
方法
聚类放弃了流行的卷积或注意力,而采用新颖的聚类算法来表示视觉学习。在本节中,我们首先描述Context Clusters流程。然后详细解释了用于特征提取的上下文聚类操作(如图2所示)。
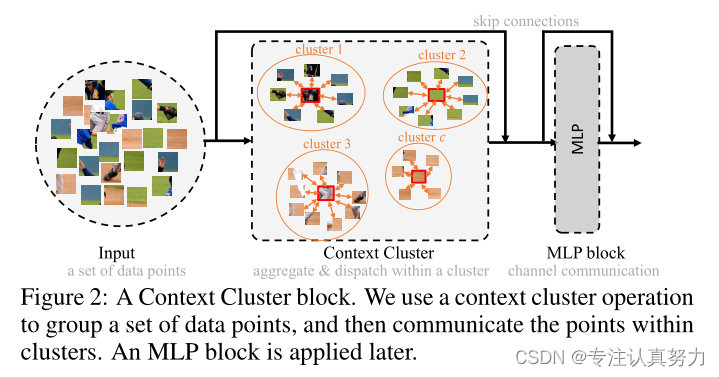
在此之后,我们建立上下文集群体系结构。最后,一些公开的讨论可能会帮助个人理解我们的工作,并在我们的上下文集群之后探索更多的方向。
1.上下文聚类流程
从图片到点集。 给出一张3通道输入图片(3,w,h),用每个像素的二维坐标增强图像,每个像素的坐标被表示为[i/w-0.5,j/h-0.5]。进一步研究位置增强技术以潜在地提高性能是可行的。这个设计是考虑到它的简单和实用。然后将增强图像转换为点的集合形状是(5,n),其n=w*h,它是点的个数。每个点都包含特征(颜色)和位置(坐标)信息;因此,点集可以是无序和无组织的。通过提供一个全新的图像视角,点集,我们获得了出色的泛化能力。点集可以被认为是通用的数据表示,因为大多数领域的数据可以作为特征和位置信息(或两者之一)的组合给出。这启发我们将图像概念化为点集。
图像点的特征提取。 遵循ConvNets方法,利用上下文聚类块(参考图2)分层提取深度特征。图3显示了我们的上下文集群架构。给定一组点P∈R(5,n),我们首先减少点的数量以提高计算效率,然后应用一系列上下文聚类块来提取特征。
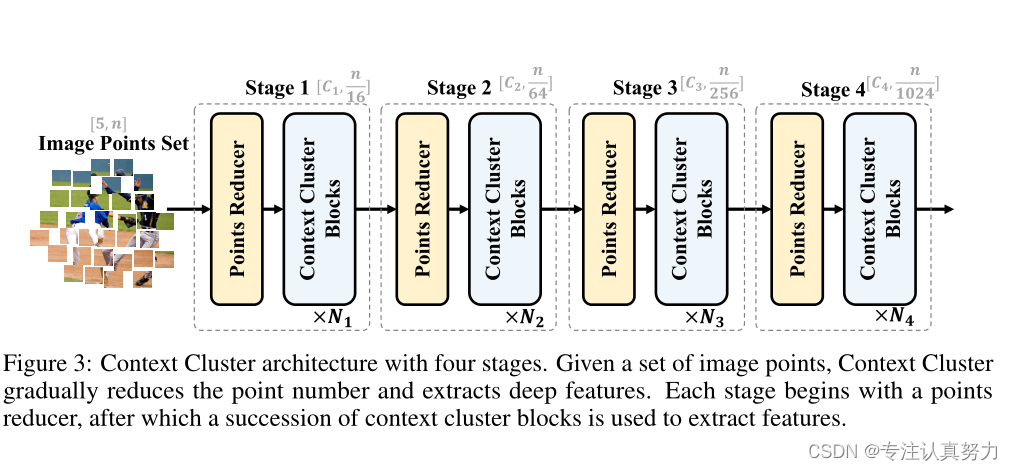 为了减少点的数量,我们在空间中均匀地选择一些锚点,并将最近的k个点通过线性投影进行拼接和融合。请注意,如果所有点都按顺序排列,并且k设置得当(即4和9),就可以通过卷积运算实现这种约简,就像ViT。为了清楚地了解前面所述的中心和锚点,我们强烈建议读者查看附录B。
为了减少点的数量,我们在空间中均匀地选择一些锚点,并将最近的k个点通过线性投影进行拼接和融合。请注意,如果所有点都按顺序排列,并且k设置得当(即4和9),就可以通过卷积运算实现这种约简,就像ViT。为了清楚地了解前面所述的中心和锚点,我们强烈建议读者查看附录B。
特定任务应用。 为了分类,我们平均最后一个块输出的所有点,并使用FC层进行分类。对于下游密集的预测任务,如检测和分割,我们需要在每一阶段后按位置重新排列输出点,以满足大多数检测和分割头部的需求。换句话说,上下文聚类在分类任务中提供了显著的灵活性,但仅限于密集预测任务的需求和我们的模型配置之间的妥协。我们希望创新的检测和分割头与我们的方法无缝集成。
2.上下文聚类操作
在本小节中,我们将介绍我们工作中的关键贡献,上下文集群操作。总体上,我们首先将特征点分组成簇;然后对每个聚类中的特征点进行聚合,再进行回调,如图1所示。
上下文聚类。 给定一个特征点集P(n,d),将它基于相似度进行分组,每个点被单独分配到一个集群中。我们首先线性投影P到Ps进行相似度计算。遵循传统的超像素方法SLIC。我们在空间中均匀地提出c个中心,并通过平均它的k个最近点来计算中心特征。然后我们计算Ps和得到的中心点集之间的成对余弦相似矩S∈R(c,n)。由于每个点都包含特征和位置信息,在计算相似度时,我们隐式地突出显示点的距离(局部性)以及特征相似度。在此之后,我们将每个点分配到最相似的中心,产生c个聚类。值得注意的是,每个集群可能有不同数量的点。在极端情况下,一些集群可能有0点,在这种情况下,它们是多余的。
特征聚集。 我们根据与中心点的相似性动态聚集聚类中的所有点。假设一个聚类包含m个点(P中的一个子集),m个点与中心的相似度为s∈R(m) (S中的子集),我们将这些点映射到一个值空间,得到Pv∈R(m,d’),其中d ‘是值维。我们还在值空间中提出了一个中心vc集群中心提案。聚合特征g∈R(d’)由:
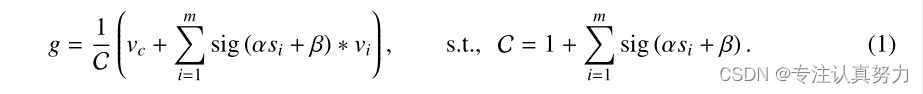
这里α和β是可学习的标量,用于缩放和移动相似度,sig(·)是一个sigmoid函数,用于重新缩放相似度到(0,1)。vi表示Pv中的第i个点。从经验上看,这种策略比直接应用原始相似度的结果要好得多,因为不涉及负值。不考虑Softmax,因为各点之间并不矛盾。为了数值的稳定性,我们在方程1中加入了值中心vc,并进一步强调了局部性。为了控制大小,聚合特征被归一化因子C。
特征调度。 然后,聚合特征g根据相似性自适应地分配到聚类中的每个点。通过这样做,点之间可以相互通信,并共享来自集群中所有点的特征,如图1所示。对于每一点,我们更新它
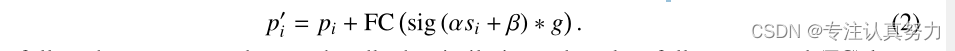
在这里,我们遵循相同的程序来处理相似性,并应用一个全连接(FC)层来匹配特征维度(从值空间维度d '到原始维度d)
多头计算。 我们承认自注意机制中的多头设计,并使用它来增强我们的上下文聚类。我们考虑h个正面,为了简单起见,将值空间Pv和相似空间Ps的维数都设为d '。多头操作的输出由FC层连接和融合。正如我们的经验所证明的那样,多头架构也有助于我们上下文集群的令人满意的改进。
3.结构初始化
虽然上下文集群从根本上不同于卷积和注意力,但 ConvNets 和 vit 的设计理念,如层次表示和 meta Transformer 架构,仍然适用于上下文集群。为了与其他网络保持一致,并使我们的方法与大多数检测和分割算法兼容,我们在每个阶段逐步减少 16、4、4 和 4 的点数。我们在第一阶段为选定的锚点考虑 16 个最近的邻居,在其余阶段选择它们的 9 个最近的邻居。
一个潜在的问题是计算效率。假设我们有n个d维点和c个聚类,计算特征相似度的时间复杂度为O (ncd),这在输入图像分辨率较高(例如224 × 224)时是不可接受的。为了避免这个问题,我们引入了区域划分,将点分成几个局部区域,如Swin Transformer ,并在局部计算相似度。因此,当局部区域的数量设置为r时,我们显著地降低了时间复杂度。注意,如果我们将点集分割为几个局部区域,就会限制上下文集群的接受域,并且局部区域之间没有可用的通信。
4.讨论
集群的固定或动态中心? 传统的聚类算法和SuperPixel技术都是迭代更新中心直到收敛。然而,当集群被用作每个构建块的关键组件时,这将导致过高的计算成本。推理时间将呈指数增长。在上下文聚类中,我们将固定中心视为推理效率的替代品,这可以被视为准确性和速度之间的妥协。
重叠还是非重叠集群? 我们仅将点分配到特定的中心,这与以前的点云分析设计理念不同。我们有意坚持使用传统的聚类方法(非重叠聚类),因为我们想证明简单而传统的算法可以作为通用的主干。尽管它可能会产生更高的性能,但重叠集群对我们的方法不是必需的,而且可能会导致额外的计算负担。
实验
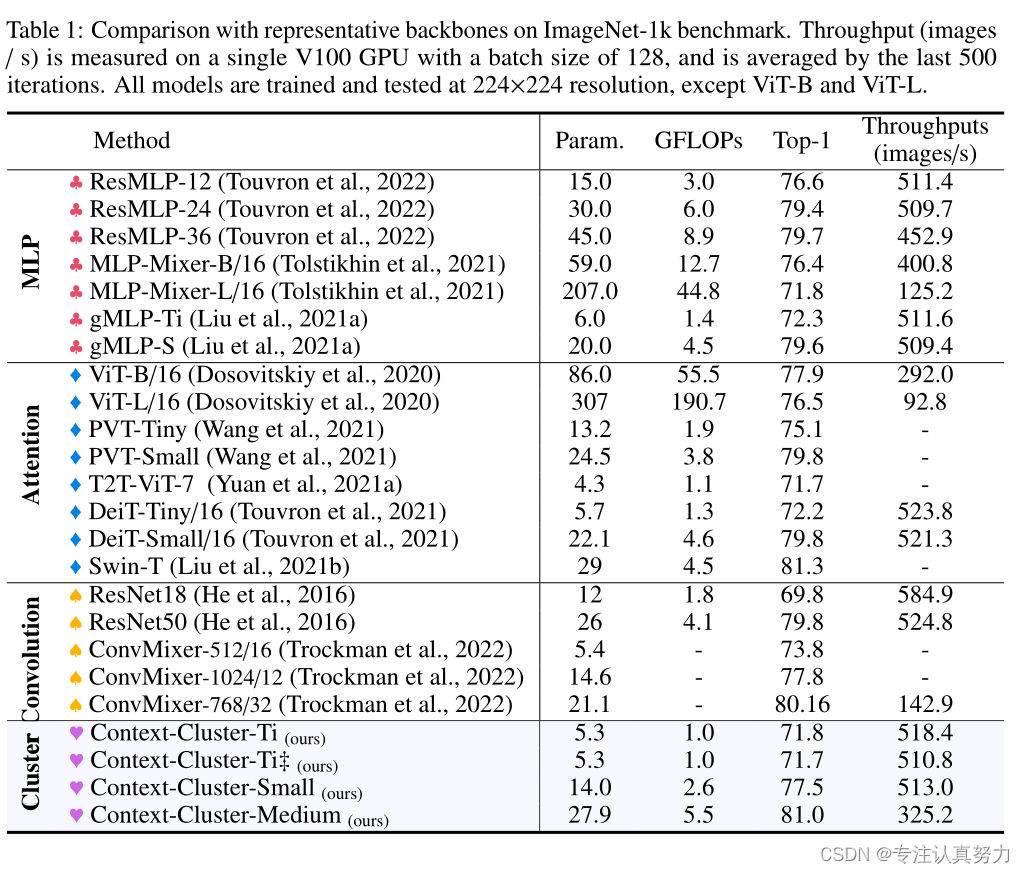
1. ImageNet-1K图像分类
我们在 ImageNet-1K 训练集 (约 1.3M 张图像) 上训练上下文集群,并在验证集上进行评估。在这项工作中,我们坚持常规的训练配方。对于数据增强,我们主要采用随机水平翻转、随机像素擦除、混合、剪切混合和标签平滑。AdamW 用于在 310 个时期训练我们的所有模型,动量为 0.9,权值衰减为 0.05。学习速率默认设置为 0.001,并使用余弦计划进行调整。默认情况下,模型在 8 个 A100 gpu 上训练,迷你批量大小为 128 (总共是 1024)。我们使用指数移动平均 (EMA) 来增强训练,类似于早期的研究。1 报告了使用的参数、FLOPs、分类精度和吞吐量。‡表示一种不同的区域划分方法,我们在四个阶段中将点划分为 [49,49,1,1]。
从经验来看,表 1 中的结果表明了我们提出的上下文集群的有效性。我们的上下文集群能够获得与使用类似数量的参数和 flop 的广泛使用的基线相当甚至更好的性能。通过大约 25M 个参数,我们的上下文集群超过了增强的 ResNet50 和 PVT-small 1.1%,达到 80.9% top-1 精度。此外,我们的上下文集群明显优于基于 mlp 的方法。这一现象表明,我们的方法的性能并不归功于 MLP 块,上下文集群块在很大程度上有助于视觉表示。Context-Cluster- ti 和 Context-Cluster- ti 之间的性能差异可以忽略不计,这证明了我们的 Context Cluster 对局部区域划分策略的鲁棒性。我们认识到,我们的结果无法与 SOTA 性能相匹配 (例如,CoAtNet-0 达到 81.6% 的精度,参数数量与 CoC-Tiny 相当),但我们强调,我们正在追求并证明一种新的特征提取范式的可行性。通过将图像概念化为一组点,并自然地应用聚类算法进行特征提取,我们成功地放弃了网络中的卷积和注意力。与卷积和注意力相比,我们的上下文聚类对其他领域数据具有良好的泛化性,并具有良好的可解释性。
组件消融。 表2报告了在ImageNet-1K上消除Context-Cluster-Small变体中每个单独组件的结果。为了消除多头设计,我们为每个块使用一个头部,并在四个阶段中分别将头部尺寸设置为[16,32,96,128]。当位置信息被删除时,由于点是无序的,模型变得不可训练。类似的现象也可以从cifar的数据集中看到。在没有上下文集群操作的情况下,性能下降了3.3%。此外,多头设计可使结果提高0.9%。综合所有组件,我们达到了77.5%的top-1精度。

聚类可视化
为了更好地理解Context Cluster,我们绘制了图4中的聚类图,并展示了vit的注意力图和ConvNets的类激活图(即CAM) 。
请注意,这三种映射在概念上是不同的,不能直接进行比较。我们列出了其他两个(注意力和类激活)映射供参考,并演示了vit、ConvNets和我们的上下文集群中的内部操作。详细的设置可以在图4的标题中找到。

随着点数量的减少,细节被合并以形成上下文集群。三个观察结果证明了我们的上下文聚类的正确性和有效性。首先,我们的方法清楚地在最后一个阶段聚类鹅作为一个对象上下文,并将背景草分组在一起。从前面的阶段也可以观察到类似的现象,但在更详细和局部的区域。其次,我们的上下文聚类甚至可以在非常早期的阶段(例如,第一阶段和第二阶段)聚类相似的上下文。放大红色框中的细节,我们可以看到,属于鹅脖子的点明显聚在一起,说明我们的方法聚类能力很强。最后,我们注意到大多数聚类强调局部性,而一些(亮绿色部分)则表现出大量的全局性,如上一阶段的聚类图所示。这进一步证明了设计理念;我们鼓励将相似的点分组,但不限制接受野。可视化的聚类图和详细的分析表明,我们的上下文聚类是有效的,具有良好的可解释性。值得注意的是,当去除区域划分操作时,我们的方法在superpixel风格中展示了有希望的聚类结果。更多示例见附录。
基于MS-COCO的目标检测与实例分割
接下来,我们研究上下文集群对下游任务的泛化性,包括对象检测和实例分割。我们在 MS COCO 2017 基准上进行实验 (Lin et al, 2014),该基准有 118k 张图像用于训练,5k 张图像用于验证。在之前的工作之后,我们训练并测试了与 Mask RCNN (He 等人,2017) 集成的模型,用于对象检测和实例分割任务。所有模型使用 1× 调度器 (12 epoch) 进行训练,并使用 ImageNet 预训练权重进行初始化。为了进行比较,我们将 ResNet 作为 ConvNets 的代表,PVT 作为 ViTs 的代表。我们在表 4 中报告评价指标的平均平均精度 (mAP)。
我们注意到,由于图像分辨率的差异,直接采用 ImageNet 的上下文集群配置可能不适用于下游任务。对于分类任务,我们在一个局部区域中有 49 个点和 4 个中心。检测和分割任务对于图像大小 (1280,800) 的相同配置,将有 1000 个点。很明显,将 1000 个点分成 4 个簇会产生较差的结果。为此,我们调查了一个局部区域的 4、25 和 49 个中心,我们将得到的模型分别称为 Small/4、Small/25 和 Small/49。表 4 中的结果表明,我们的上下文集群对下游任务具有很好的泛化能力。我们的 CoC-Small/25 在正确配置 (一个本地区域有 25 个中心) 时,在检测和实例分割任务上都优于 ConvNet 和 ViT 基线。符合我们的预期,只有 4 个中心不能准确地对大的局部区域进行建模,多余的中心不能进一步提高性能。

结论
我们引入了上下文聚类,这是一种新的用于视觉表示的特征提取范式。受点云分析和 SuperPixel 算法的启发,我们将图像视为一组无组织的点,并采用简化的聚类方法提取特征。在图像解译和特征提取操作方面,Context Cluster 与 ConvNets 和 ViTs 有本质区别,在我们的架构中不涉及卷积和注意力。我们没有追求 SOTA 性能,而是展示了我们的上下文集群可以在多个任务和领域上实现与 ConvNet 和 ViT 基线相当甚至更好的结果。最值得注意的是,我们的方法显示出有希望的可解释性和泛化性。我们希望我们的上下文聚类可以被认为是卷积和注意力之外的一种新的视觉表示方法。
正如 §3 最后所讨论的,我们的新视角和视觉表现的设计也带来了新的挑战,主要是在准确性和速度之间的妥协。更好的策略值得探索。脱离当前的检测和分割框架,将我们的上下文聚类理念应用于其他任务也是一个值得追求的方向。
附录
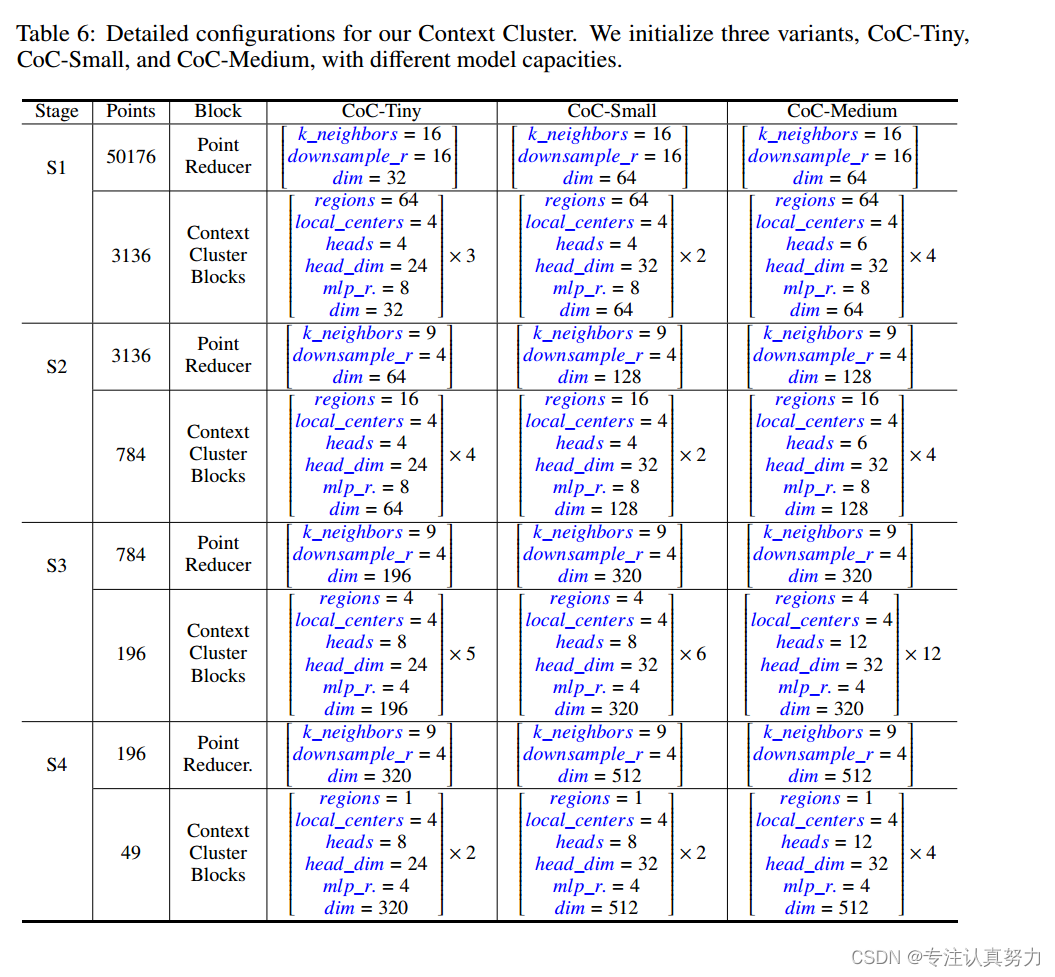
A 模型配置
我们首先在表 6 中介绍 Context 集群的详细配置。点减小块与图像缩小块一致,如 PVT 和 ConvNeXt。在点的上下文中,我们选择最近点的 k_neighbour 作为建议的锚点,并使用 FC 层融合所有点。
我们以downsample_r的倍数减少点数。我们工作中的关键贡献是上下文集群块。我们首先将整个点集均匀地划分为空间中的局部区域。在每个局部区域中,我们建议使用local_centers进行集群。在我们的上下文集群操作中,我们将每个头的头数和尺寸分别设置为heads和head_dim。信道数以mlp_r的倍数扩展(即mlp_r × dim),然后在MLP块中减小为dim。Context Cluster块将在每个阶段重复几次。为了便于理解,我们用蓝色标记所有变量。对于Context-Cluster-Ti变体,它与Context-Cluster-Ti共享相同的网络结构,不同的是我们配置了不同的区域分区和本地中心编号。其中,四个阶段的区域分区数量设置为[49,49,1,1],每个局部区域的中心数量设置为[16,4,49,16]。
B 具体例子
人们可能会对如何在点下采样块和上下文集群块中指定锚点感到困惑。在本节中,我们将对它们进行说明性的详细解释。
对于锚点和中心,它们都是在空间中均匀生成的。为了更好地说明这一点,我们在图 5 中绘制了有组织的图像点。
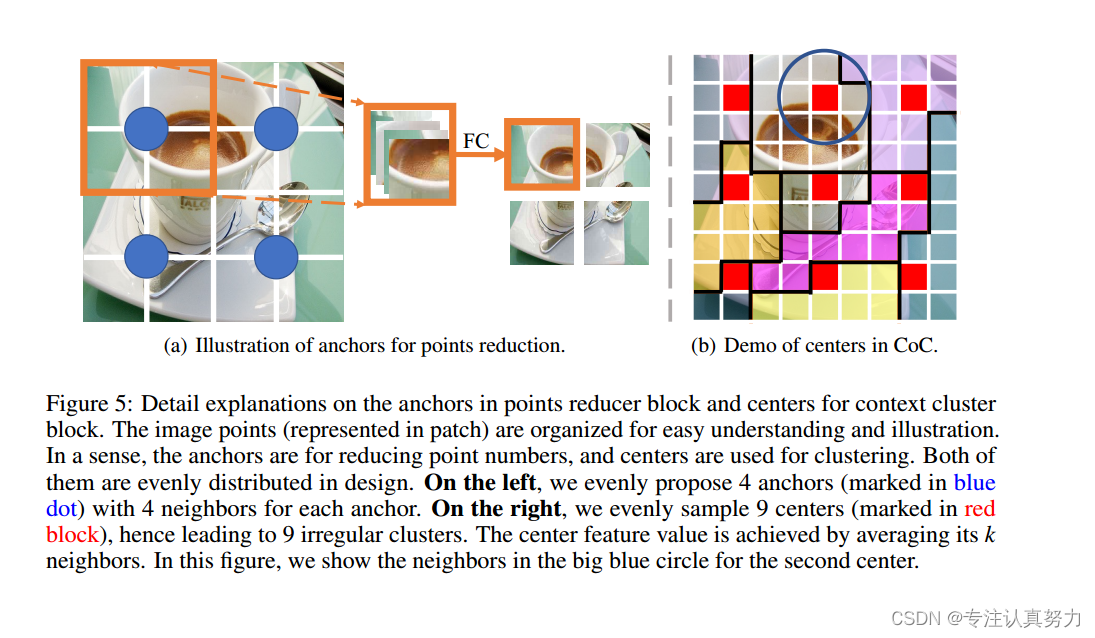
在左侧,我们显示了16个点和4个减少点的建议锚点,每个锚点都考虑了它最近的4个邻居。所有邻居都沿着通道维度进行连接,并且使用FC层来降低维度数并融合信息。在减少点的数量后,我们会得到一组具有相同数量的建议锚点的新点。
在右侧,我们显示了由图像点集和相应的 9 个聚类生成的 9 个中心 (红色块)。生成的中心的特征将通过平均 k 个邻居来给出 (对于第二个中心,我们平均蓝色大圆中的 9 个点)。
邻居的数目可以是任何值。我们将其设置为 4 或 9 有三个原因。首先,我们遵循 ConvNets 和 pyramid vit 的设计,以确保点集可以被重组为矩形特征图。其次,该策略通过使用卷积或池化操作 (相当于我们的描述) 简化了编码,并避免了繁重的索引搜索工作。最后,大多数检测和分割方法都需要矩形特征图。
D 推广前景
聚类算法是一种不局限于特定输入格式的通用方法。之前,我们分别在图像和点云上验证了 Context Cluster 的泛化能力。在这里,我们进一步展望对不同图像格式的泛化能力,如图 10 所示。我们从离散像素的讨论开始。由于聚类算法,我们的上下文聚类在处理离散图像方面实际上比 ConvNets 和 vit 具有显著的优势。换句话说,我们的上下文集群不需要图像像素在一个连续的空间中。
具体来说,给定一个由离散像素组成的图像,我们像提取常规图像一样提取特征,但改变了中心提议方法。在我们的论文中,我们通过在空间中均匀地提出 c 个中心来描述中心建议方法,并且通过平均它的 k 个最近点来计算中心特征 (这可以通过池化很容易实现)。对于离散像素点,我们可以考虑点云处理中的最远点采样 (FPS) 方法 (Qi et al, 2017b)。请注意,我们的方法受到点云方法的启发,具有离散像素的图像自然是具有 RGB 信息的点云集。除了 FPS 之外,还可以研究其他离散采样技术,为离散像素点提出中心,包括随机采样、网格采样等。
除了离散像素,我们的上下文集群还可以用于各种其他图像格式。对于掩码图像和不规则图像,传统的 ConvNets 或 vit 要求图像填充白色像素。不同的是,通过将图像概念化为一组点,我们可以跳过这一步。我们将掩码图像或不规则图像解释为离散点,并按照前面描述的那样处理它们。由于采用了聚类算法,我们的上下文聚类对各种图像格式具有很强的泛化能力。
代码理解
github
利用卷积减少点集的大小,增加点集的维度。
class PointRecuder(nn.Module):
"""
Point Reducer is implemented by a layer of conv since it is mathmatically equal.
Input: tensor in shape [B, C, H, W]
Output: tensor in shape [B, C, H/stride, W/stride]
"""
def __init__(self, patch_size=16, stride=16, padding=0,
in_chans=3, embed_dim=768, norm_layer=None):
super().__init__()
patch_size = to_2tuple(patch_size)
stride = to_2tuple(stride)
padding = to_2tuple(padding)
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size,
stride=stride, padding=padding)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
x = self.proj(x)
x = self.norm(x)
return x
class GroupNorm(nn.GroupNorm):
"""
Group Normalization with 1 group.
Input: tensor in shape [B, C, H, W]
"""
def __init__(self, num_channels, **kwargs):
super().__init__(1, num_channels, **kwargs)
# 计算两个张量的余弦相似度
def pairwise_cos_sim(x1: torch.Tensor, x2: torch.Tensor):
"""
return pair-wise similarity matrix between two tensors
:param x1: [B,...,M,D]
:param x2: [B,...,N,D]
:return: similarity matrix [B,...,M,N]
"""
x1 = F.normalize(x1, dim=-1)
x2 = F.normalize(x2, dim=-1)
sim = torch.matmul(x1, x2.transpose(-2, -1))
return sim
class Cluster(nn.Module):
def __init__(self, dim, out_dim, proposal_w=2, proposal_h=2, fold_w=2, fold_h=2, heads=4, head_dim=24,
return_center=False):
"""
:param dim: channel nubmer
:param out_dim: channel nubmer
:param proposal_w: the sqrt(proposals) value, we can also set a different value
:param proposal_h: the sqrt(proposals) value, we can also set a different value
:param fold_w: the sqrt(number of regions) value, we can also set a different value
:param fold_h: the sqrt(number of regions) value, we can also set a different value
:param heads: heads number in context cluster
:param head_dim: dimension of each head in context cluster
:param return_center: if just return centers instead of dispatching back (deprecated).
"""
super().__init__()
self.heads = heads
self.head_dim = head_dim
self.f = nn.Conv2d(dim, heads * head_dim, kernel_size=1) # for similarity
self.proj = nn.Conv2d(heads * head_dim, out_dim, kernel_size=1) # for projecting channel number
self.v = nn.Conv2d(dim, heads * head_dim, kernel_size=1) # for value
self.sim_alpha = nn.Parameter(torch.ones(1))
self.sim_beta = nn.Parameter(torch.zeros(1))
self.centers_proposal = nn.AdaptiveAvgPool2d((proposal_w, proposal_h))
self.fold_w = fold_w
self.fold_h = fold_h
self.return_center = return_center
def forward(self, x): # [b,c,w,h]
value = self.v(x)
x = self.f(x)
x = rearrange(x, "b (e c) w h -> (b e) c w h", e=self.heads)
value = rearrange(value, "b (e c) w h -> (b e) c w h", e=self.heads)
if self.fold_w > 1 and self.fold_h > 1:
# split the big feature maps to small local regions to reduce computations.
b0, c0, w0, h0 = x.shape
assert w0 % self.fold_w == 0 and h0 % self.fold_h == 0, \
f"Ensure the feature map size ({
w0}*{
h0}) can be divided by fold {
self.fold_w}*{
self.fold_h}"
x = rearrange(x, "b c (f1 w) (f2 h) -> (b f1 f2) c w h", f1=self.fold_w,
f2=self.fold_h) # [bs*blocks,c,ks[0],ks[1]]
value = rearrange(value, "b c (f1 w) (f2 h) -> (b f1 f2) c w h", f1=self.fold_w, f2=self.fold_h)
b, c, w, h = x.shape
centers = self.centers_proposal(x) # [b,c,C_W,C_H], we set M = C_W*C_H and N = w*h
value_centers = rearrange(self.centers_proposal(value), 'b c w h -> b (w h) c') # [b,C_W,C_H,c]
b, c, ww, hh = centers.shape
sim = torch.sigmoid(
self.sim_beta +
self.sim_alpha * pairwise_cos_sim(
centers.reshape(b, c, -1).permute(0, 2, 1),
x.reshape(b, c, -1).permute(0, 2, 1)
)
) # [B,M,N]
# we use mask to sololy assign each point to one center
sim_max, sim_max_idx = sim.max(dim=1, keepdim=True)
mask = torch.zeros_like(sim) # binary #[B,M,N]
mask.scatter_(1, sim_max_idx, 1.)
sim = sim * mask
value2 = rearrange(value, 'b c w h -> b (w h) c') # [B,N,D]
# aggregate step, out shape [B,M,D]
out = ((value2.unsqueeze(dim=1) * sim.unsqueeze(dim=-1)).sum(dim=2) + value_centers) / (
mask.sum(dim=-1, keepdim=True) + 1.0) # [B,M,D]
if self.return_center:
out = rearrange(out, "b (w h) c -> b c w h", w=ww)
else:
# dispatch step, return to each point in a cluster
out = (out.unsqueeze(dim=2) * sim.unsqueeze(dim=-1)).sum(dim=1) # [B,N,D]
out = rearrange(out, "b (w h) c -> b c w h", w=w)
if self.fold_w > 1 and self.fold_h > 1:
# recover the splited regions back to big feature maps if use the region partition.
out = rearrange(out, "(b f1 f2) c w h -> b c (f1 w) (f2 h)", f1=self.fold_w, f2=self.fold_h)
out = rearrange(out, "(b e) c w h -> b (e c) w h", e=self.heads)
out = self.proj(out)
return out
class Mlp(nn.Module):
"""
Implementation of MLP with nn.Linear (would be slightly faster in both training and inference).
Input: tensor with shape [B, C, H, W]
"""
def __init__(self, in_features, hidden_features=None,
out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.fc1(x.permute(0, 2, 3, 1))
x = self.act(x)
x = self.drop(x)
x = self.fc2(x).permute(0, 3, 1, 2)
x = self.drop(x)
return x
class ClusterBlock(nn.Module):
"""
Implementation of one block.
--dim: embedding dim
--mlp_ratio: mlp expansion ratio
--act_layer: activation
--norm_layer: normalization
--drop: dropout rate
--drop path: Stochastic Depth,
refer to https://arxiv.org/abs/1603.09382
--use_layer_scale, --layer_scale_init_value: LayerScale,
refer to https://arxiv.org/abs/2103.17239
"""
def __init__(self, dim, mlp_ratio=4.,
act_layer=nn.GELU, norm_layer=GroupNorm,
drop=0., drop_path=0.,
use_layer_scale=True, layer_scale_init_value=1e-5,
# for context-cluster
proposal_w=2, proposal_h=2, fold_w=2, fold_h=2, heads=4, head_dim=24, return_center=False):
super().__init__()
self.norm1 = norm_layer(dim)
# dim, out_dim, proposal_w=2,proposal_h=2, fold_w=2, fold_h=2, heads=4, head_dim=24, return_center=False
self.token_mixer = Cluster(dim=dim, out_dim=dim, proposal_w=proposal_w, proposal_h=proposal_h,
fold_w=fold_w, fold_h=fold_h, heads=heads, head_dim=head_dim, return_center=False)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop)
# The following two techniques are useful to train deep ContextClusters.
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.use_layer_scale = use_layer_scale
if use_layer_scale:
self.layer_scale_1 = nn.Parameter(layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(layer_scale_init_value * torch.ones((dim)), requires_grad=True)
def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(
self.layer_scale_1.unsqueeze(-1).unsqueeze(-1)
* self.token_mixer(self.norm1(x)))
x = x + self.drop_path(
self.layer_scale_2.unsqueeze(-1).unsqueeze(-1)
* self.mlp(self.norm2(x)))
else:
x = x + self.drop_path(self.token_mixer(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
def basic_blocks(dim, index, layers,
mlp_ratio=4.,
act_layer=nn.GELU, norm_layer=GroupNorm,
drop_rate=.0, drop_path_rate=0.,
use_layer_scale=True, layer_scale_init_value=1e-5,
# for context-cluster
proposal_w=2, proposal_h=2, fold_w=2, fold_h=2, heads=4, head_dim=24, return_center=False):
blocks = []
for block_idx in range(layers[index]):
block_dpr = drop_path_rate * ( block_idx + sum(layers[:index])) / (sum(layers) - 1)
blocks.append(ClusterBlock(
dim, mlp_ratio=mlp_ratio,
act_layer=act_layer, norm_layer=norm_layer,
drop=drop_rate, drop_path=block_dpr,
use_layer_scale=use_layer_scale,
layer_scale_init_value=layer_scale_init_value,
proposal_w=proposal_w, proposal_h=proposal_h, fold_w=fold_w, fold_h=fold_h,
heads=heads, head_dim=head_dim, return_center=False
))
blocks = nn.Sequential(*blocks)
return blocks
class ContextCluster(nn.Module):
"""
ContextCluster, the main class of our model
--layers: [x,x,x,x], number of blocks for the 4 stages
--embed_dims, --mlp_ratios, the embedding dims, mlp ratios
--downsamples: flags to apply downsampling or not
--norm_layer, --act_layer: define the types of normalization and activation
--num_classes: number of classes for the image classification
--in_patch_size, --in_stride, --in_pad: specify the patch embedding
for the input image
--down_patch_size --down_stride --down_pad:
specify the downsample (patch embed.)
--fork_feat: whether output features of the 4 stages, for dense prediction
--init_cfg, --pretrained:
for mmdetection and mmsegmentation to load pretrained weights
"""
def __init__(self, layers, embed_dims=None,
mlp_ratios=None, downsamples=None,
norm_layer=nn.BatchNorm2d, act_layer=nn.GELU,
num_classes=1000,
in_patch_size=4, in_stride=4, in_pad=0,
down_patch_size=2, down_stride=2, down_pad=0,
drop_rate=0., drop_path_rate=0.,
use_layer_scale=True, layer_scale_init_value=1e-5,
fork_feat=False,
init_cfg=None,
pretrained=None,
# the parameters for context-cluster
proposal_w=[2, 2, 2, 2], proposal_h=[2, 2, 2, 2], fold_w=[8, 4, 2, 1], fold_h=[8, 4, 2, 1],
heads=[2, 4, 6, 8], head_dim=[16, 16, 32, 32],
**kwargs):
super().__init__()
if not fork_feat:
self.num_classes = num_classes
self.fork_feat = fork_feat
self.patch_embed = PointRecuder(
patch_size=in_patch_size, stride=in_stride, padding=in_pad,
in_chans=5, embed_dim=embed_dims[0])
# set the main block in network
network = []
for i in range(len(layers)):
stage = basic_blocks(embed_dims[i], i, layers,
mlp_ratio=mlp_ratios[i],
act_layer=act_layer, norm_layer=norm_layer,
drop_rate=drop_rate,
drop_path_rate=drop_path_rate,
use_layer_scale=use_layer_scale,
layer_scale_init_value=layer_scale_init_value,
proposal_w=proposal_w[i], proposal_h=proposal_h[i],
fold_w=fold_w[i], fold_h=fold_h[i], heads=heads[i], head_dim=head_dim[i],
return_center=False
)
network.append(stage)
if i >= len(layers) - 1:
break
if downsamples[i] or embed_dims[i] != embed_dims[i + 1]:
# downsampling between two stages
network.append(
PointRecuder(
patch_size=down_patch_size, stride=down_stride,
padding=down_pad,
in_chans=embed_dims[i], embed_dim=embed_dims[i + 1]
)
)
self.network = nn.ModuleList(network)
if self.fork_feat:
# add a norm layer for each output
self.out_indices = [0, 2, 4, 6]
for i_emb, i_layer in enumerate(self.out_indices):
if i_emb == 0 and os.environ.get('FORK_LAST3', None):
# TODO: more elegant way
"""For RetinaNet, `start_level=1`. The first norm layer will not used.
cmd: `FORK_LAST3=1 python -m torch.distributed.launch ...`
"""
layer = nn.Identity()
else:
layer = norm_layer(embed_dims[i_emb])
layer_name = f'norm{
i_layer}'
self.add_module(layer_name, layer)
else:
# Classifier head
self.norm = norm_layer(embed_dims[-1])
self.head = nn.Linear(
embed_dims[-1], num_classes) if num_classes > 0 \
else nn.Identity()
self.apply(self.cls_init_weights)
self.init_cfg = copy.deepcopy(init_cfg)
# load pre-trained model
if self.fork_feat and (
self.init_cfg is not None or pretrained is not None):
self.init_weights()
# init for classification
def cls_init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
# init for mmdetection or mmsegmentation by loading
# imagenet pre-trained weights
def init_weights(self, pretrained=None):
logger = get_root_logger()
if self.init_cfg is None and pretrained is None:
logger.warn(f'No pre-trained weights for '
f'{
self.__class__.__name__}, '
f'training start from scratch')
pass
else:
assert 'checkpoint' in self.init_cfg, f'Only support ' \
f'specify `Pretrained` in ' \
f'`init_cfg` in ' \
f'{
self.__class__.__name__} '
if self.init_cfg is not None:
ckpt_path = self.init_cfg['checkpoint']
elif pretrained is not None:
ckpt_path = pretrained
ckpt = _load_checkpoint(
ckpt_path, logger=logger, map_location='cpu')
if 'state_dict' in ckpt:
_state_dict = ckpt['state_dict']
elif 'model' in ckpt:
_state_dict = ckpt['model']
else:
_state_dict = ckpt
state_dict = _state_dict
missing_keys, unexpected_keys = \
self.load_state_dict(state_dict, False)
# show for debug
# print('missing_keys: ', missing_keys)
# print('unexpected_keys: ', unexpected_keys)
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes):
self.num_classes = num_classes
self.head = nn.Linear(
self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_embeddings(self, x):
_, c, img_w, img_h = x.shape
# print(f"det img size is {img_w} * {img_h}")
# register positional information buffer.
range_w = torch.arange(0, img_w, step=1) / (img_w - 1.0)
range_h = torch.arange(0, img_h, step=1) / (img_h - 1.0)
fea_pos = torch.stack(torch.meshgrid(range_w, range_h, indexing='ij'), dim=-1).float()
fea_pos = fea_pos.to(x.device)
fea_pos = fea_pos - 0.5
pos = fea_pos.permute(2, 0, 1).unsqueeze(dim=0).expand(x.shape[0], -1, -1, -1)
x = self.patch_embed(torch.cat([x, pos], dim=1))
return x
def forward_tokens(self, x):
outs = []
for idx, block in enumerate(self.network):
x = block(x)
if self.fork_feat and idx in self.out_indices:
norm_layer = getattr(self, f'norm{
idx}')
x_out = norm_layer(x)
outs.append(x_out)
if self.fork_feat:
# output the features of four stages for dense prediction
return outs
# output only the features of last layer for image classification
return x
def forward(self, x):
# input embedding
x = self.forward_embeddings(x)
# through backbone
x = self.forward_tokens(x)
if self.fork_feat:
# otuput features of four stages for dense prediction
return x
x = self.norm(x)
cls_out = self.head(x.mean([-2, -1]))
# for image classification
return cls_out