Open-Set Domain Adaptation with Visual-Language Foundation Models 论文阅读笔记
写在前面
又是一周周末,在家的时间感觉过得很快呀,下周就能回学校啦~
- 论文地址:Open-Set Domain Adaptation with Visual-Language Foundation Models
- 代码地址:当前版本暂未提供代码地址
- 预计提交于:CVPR 2024
- Ps:2023 年每周一篇博文阅读笔记,主页 更多干货,欢迎关注呀,期待 5 千粉丝有你的参与呦~
一、Abstract
无监督域适应在知识迁移中很管用。由于目标域标签的缺失和一些未知类别的存在,开放域适应 open-set domain adaptation (ODA) 是个不错的解决办法。现有的 ODA 方法旨在解决源域和目标域的分布迁移问题,而大多数方法微调那些训练在 ImageNet 上的源域模型。最近的视觉语言基础模型 visual-language foundation models (VLFM),例如 CLIP 对大多数迁移分布鲁棒,直觉上应该能够提升 ODA 的性能。于是本文探索 CLIP 的更通用方式应用于 ODA。使用 CLIP 调查 zero-shot 的预测能力,然后提出一种交叉熵优化策略来辅助 ODA 模型。实验效果很好。
二、引言
为了获得大规模标签数据,无监督域适应 unsupervised domain adaptation (UDA) 将标签源域中的知识转移到无标签的目标域中。传统的域适应技术假设源域和目标域共享相同的类别,然而大多数目标域中存在源域中未知的类,这一任务即开放域适应 open-set domain adaptation (ODA)。
ODA 中主要挑战在于需要在训练阶段识别出未知类。现有的 ODA 方法通常用预训练在 ImageNet 上的模型进行权重初始化,然后在目标域上微调,因此这些方法的性能非常依赖于预训练模型的质量以及两个域的分布偏移程度。
预训练在大尺度数据集上的视觉语言基础模型 visual-language foundation models (VLFM),例如 CLIP 泛化能力很强,于是本文将 CLIP 用于 ODA。首先调研 CLIP 在 ODA 不同数据集上的鲁棒性,然后关注 CLIP 在 ODA 上的 zero-shot 能力。本文发现当目标域中目标样本被视作已知样本时,CLIP 的输出有很低的的交叉熵,而视为未知样本时,则有很高的的交叉熵。为实现 ODA,再利用源域数据训练一个其他的图像分类模型,名为 ODA 模型。对于目标域中检测到的已知样本,CLIP 的预测知识将会蒸馏到 ODA 模型,于是通过 CLIP 的知识可以帮助适应目标域中的已知样本。对于目标域中检测到的未知样本,通过最大化 ODA 模型的交叉熵,训练 ODA 模型输出低置信度的预测,这些未知样本将进一步分离出来。利用交叉熵优化策略整合 CLIP 的输出,给 ODA 模型提供丰富的区分性特征。
此外,本文的方法能够应用在源域无关的 ODA 上,即 source-free ODA (SF-ODA),其中目标域样本的适应仅需 ODA 模型即可实现,无需源域数据。
贡献如下:
- 调查发现 CLIP 在 ODA 问题上的 zero-shot 预测的性能;
- 提出一种交叉熵优化策略用于 CLIP 预测,从而提高 ODA 模型在已知样本和未知样本上的分类能力;
- 提出的方法不仅可以解决 ODA,也能用于 SF-ODA,在几个数据集上的表现很好。
下图是这些方法的概念图(老实说这个图画的不太理解,而且文章中没有引用到这张图):

三、相关工作

3.1 开放域适应
源域和目标域标签分别设为 C s C_s Cs 和 C t C_t Ct,无监督域适应 UDA 中 C s = C t C_s=C_t Cs=Ct。在未知目标类别中, C s C_s Cs 是 C t C_t Ct 的子集,于是 ODA 被提出用于解决这类类别不匹配的问题。
解决 ODA 的一个方法是利用无监督自适应网络中源域和目标域样本的权重,使用源域标签数据最小化交叉熵损失来为每个类别训练出一个一对一的分类器。
3.2 源域无关的开放域适应
在训练中,所有的 UDA 和 ODA 方法都需要源域和目标域样本的参与。然而对于无法提供源域标签的场景,或一些实时部署的场景,这样的方法显然不适用。于是有一些文献提出冻结源域的分类器模块,转而学习特定任务的特征提取器模块,例如 SHOT、USFDA、OneRing 来实现 SF-ODA。
3.3 视觉-语言基础模型 VLFM
大尺度的预训练模型采用 Transformer 进行 CV 和 NLP 任务的攻坚,早期的工作之一是 GPT,同时期的 BERT,IGPT、MAE。
最近大量的预训练技巧,包含对比学习、MLM、MRM 等都进一步推动了 VLFM 的发展。其中在大尺度图像-文本对中训练的 CLIP 模型表现出很强的泛化能力,并且能够检测到未知样本。
在 ODA 和 SF-ODA 中, 通常的做法是使用 ImageNet 上预训练的权重来初始化模型。因为这些方法主要依赖于预训练模型的质量,类似 CLIP 这类的 VLFM 方法有很大的潜力来提升 ODA 和 SF-ODA 的性能,相反的是微调 VLFM 模型的成本很大。于是采用 CLIP 的 zero-shot 预测,提出一种轻量化的方式将 CLIP 应用于 ODA。

四、方法
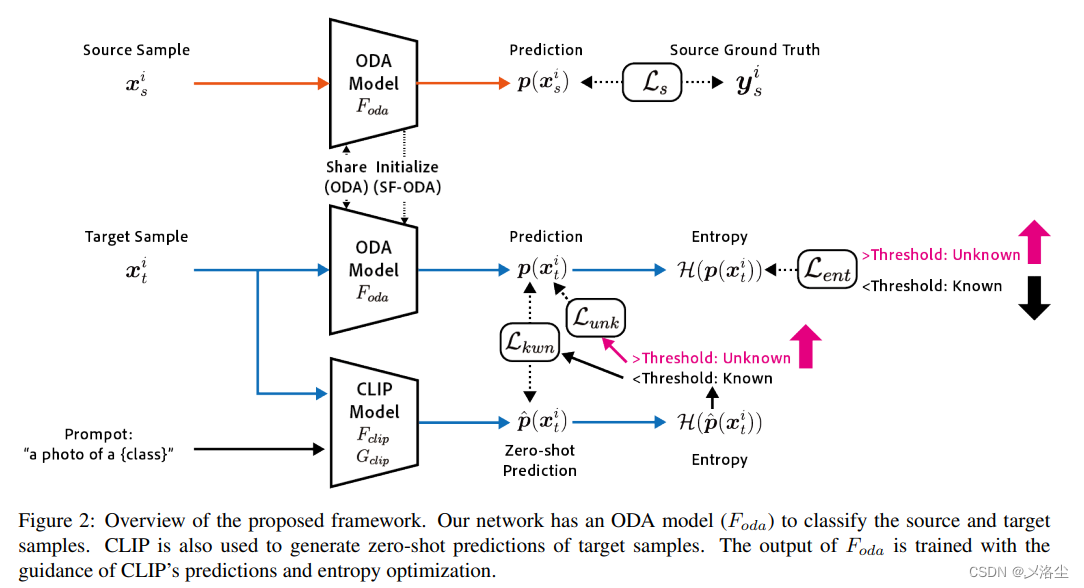
4.1 问题陈述
假设源域标签集合 { X s , Y s } \{X_s,Y_s\} {
Xs,Ys},一个源域图像-标签对 { x s , y s } \{x_s,y_s\} {
xs,ys},无标签目标图像集合 X t X_t Xt 中的一张无标签目标图像为 x t x_t xt, C s C_s Cs 和 C t C_t Ct 分别表示源域标签和样本标签图像。在 ODA 中,已知类别为源域数据,而某些未知类别存在于没有标签的源域和目标域中,即 C s ∈ C t C_s\in C_t Cs∈Ct,表示为 C t ~ = C t \ C s \widetilde{C_{t}}=C_{t}\backslash C_{s} Ct
=Ct\Cs。
给定目标样本 x t x_t xt,ODA 旨在预测预测其标签 y t y_t yt 是否属于源域类别 C s C_s Cs 中的一个还是未知类别 C t ~ \widetilde{C_{t}} Ct
中的一个样本。在 SF-ODA 中,当训练 X t X_t Xt 时,其标签并并不提供,于是需要通过训练在 { X s , Y s } \{X_s,Y_s\} {
Xs,Ys} 上的模型实现。
最小批量的训练过程涉及到两种集合的数据,其中 D s = ( x s i , y s i ) i = 1 N D_{s}=\left(x_{s}^{i},y_{s}^{i}\right)_{i=1}^{N} Ds=(xsi,ysi)i=1N 表示尺寸为 N N N 的源自源域样本的迷你批量,而 D t = ( x t i ) i = 1 N D_{t}=\left(x_{t}^{i}\right)_{i=1}^{N} Dt=(xti)i=1N 表示尺寸为 N N N 的源自目标域域样本的迷你批量。
4.2采用 CLIP 的 Zero-shot 预测
CLIP 由一个图像编码器 F c l i p F_{clip} Fclip 和一个语言模型 G c l i p G_{clip} Gclip 组成,其利用文本 prompt t t t 的 embedding 和图像特征的相似性来对图像分类。对于类别 prompt t k \boldsymbol{t}_k tk,通过计算 F c l i p ( x t i ) F_{clip}(x_t^i) Fclip(xti) 和 G c l i p ( t k ) G_{clip}(\boldsymbol{t}_k) Gclip(tk) 的输出的余弦相似度:
y ^ i = arg max k ∈ C s F c l i p ( x t i ) ⋅ G c l i p ( t k ) \hat{y}^i=\arg\max_{k\in C_s}F_{clip}(x_t^i)\cdot G_{clip}(\boldsymbol{t}_k) y^i=argk∈CsmaxFclip(xti)⋅Gclip(tk)其中 C s C_s Cs 为源域中的类别, ⋅ \cdot ⋅ 表示余弦相似度。
在 ODA 上进行 Zero-shot 评估时,同时冻结图像编码器和语言模型,然后在每个数据集中将文本 prompt t \boldsymbol{t} t 替代为 “A photo of a {label}”。
在 ODA 中, 由于目标域中存在者未知样本,于是通过预测交叉熵来检测这些样本。首先,将余弦相似度转换为概率 p ^ \hat{p} p^:
p ^ ( k ∣ x t i ) = exp ( F c l i p ( x t i ) ⋅ G c l i p ( t k ) / τ ) ∑ k = 1 K exp ( F c l i p ( x t i ) ⋅ G c l i p ( t k ) / τ ) \hat{p}(k|x_t^i)=\frac{\exp(F_{clip}(x_t^i)\cdot G_{clip}(t_k)/\tau)}{\sum_{k=1}^K\exp(F_{clip}(x_t^i)\cdot G_{clip}(t_k)/\tau)} p^(k∣xti)=∑k=1Kexp(Fclip(xti)⋅Gclip(tk)/τ)exp(Fclip(xti)⋅Gclip(tk)/τ)其中 p ^ ( k ∣ x t i ) \hat{p}(k|x_t^i) p^(k∣xti) 表示样本 x t i x_t^i xti 属于类别 k k k 的概率, τ = 0.01 \tau=0.01 τ=0.01 控制着分布的集中程度。
之后计算 p ^ \hat p p^ 的交叉熵 H ( p ^ ) \mathcal{H}(\hat p) H(p^),当一个目标样本 x t i x_t^i xti 的 H ( p ^ ) \mathcal{H}(\hat p) H(p^) 大于某一阈值 δ {\delta} δ 时,则为未知样本(在所有已知类别上的预测概率很低)。对于另一些有着很小交叉熵的已知样本,将由文中的第一个公式来预测其类别。
4.3 ODA 模型准备
首先准备一个简单模型 F o l d F_{old} Fold,来区分源域样本,包含一个特征提取器和分类器,输出一个概率向量 F o d a ( x i ) ∈ R ∣ C s ∣ F_{oda}(x^i)\in\mathbb{R}^{|C_s|} Foda(xi)∈R∣Cs∣。采用标注的交叉熵损失和有标签的源域数据来优化:
L s ( D s ) = − 1 N ∑ i = 1 N ∑ k = 1 ∣ C s ∣ y s i k log p ( k ∣ x s i ) \mathcal{L}_s(D_s)=-\frac1N\sum_{i=1}^N\sum_{k=1}^{|C_s|}y_s^{ik}\log p(k|x_s^i) Ls(Ds)=−N1i=1∑Nk=1∑∣Cs∣ysiklogp(k∣xsi)其中 p ( k ∣ x s i ) p(k|x_s^i) p(k∣xsi) 为样本 x s i x_s^i xsi 预测为类别 k k k 的概率,这是 F o d a ( x s i ) F_{oda}(x_s^i) Foda(xsi) 的第 k k k 个输出, y s i k y_s^{ik} ysik 表示样本是否属于类别 k k k 的二值化标签。
4.4 带有 CLIP 的交叉熵优化
4.4.1 交叉分离的域适应
为使得 ODA 模型 F o d a F_{oda} Foda 适应目标域,应用交叉分离损失到目标样本上:
L e n t ( D t ) = 1 N ∑ i = 1 N L ~ e n t ( D t ) \mathcal{L}_{ent}(D_t)=\frac1N\sum_{i=1}^N\tilde{\mathcal{L}}_{ent}(D_t) Lent(Dt)=N1i=1∑NL~ent(Dt)
L ~ e n t ( D t ) = { − ∣ H ( p ) − δ ∣ i f ∣ H ( p ) − δ ∣ > m 0 o t h e r w i s e \tilde{\mathcal{L}}_{ent}(D_t)=\begin{cases}-|\mathcal{H}(p)-\delta|&\mathrm{if~}|\mathcal{H}(p)-\delta|>m\\0&\mathrm{otherwise}&\end{cases} L~ent(Dt)={
−∣H(p)−δ∣0if ∣H(p)−δ∣>motherwise其中 H ( p ) \mathcal{H}(p) H(p) 为 p ( x t i ) p(x_t^i) p(xti) 的交叉熵, δ \delta δ 表示阈值, m m m 为分离的边界。 δ \delta δ 设为 log ( ∣ C s ∣ ) 2 \frac{\log(|C_s|)}2 2log(∣Cs∣) ,因为 log ( ∣ C s ∣ ) \log(|C_s|) log(∣Cs∣) 为 H \mathcal{H} H 的最大值。当交叉熵大于阈值,且不在边界区域内,即 H ( p ) > δ + m ( o r H ( p ) − δ > m ) \mathcal{H}(p)>\delta+m\mathrm{~(or~}\mathcal{H}(p)-\delta>m) H(p)>δ+m (or H(p)−δ>m) 时,此样本视为一个未知样本且交叉熵会通过最小化损失来增加。反之,当 H ( p ) < δ − m (or H ( p ) − δ < − m ) \mathcal{H}(p)<\delta-m\text{ (or }\mathcal{H}(p)-\delta<-m) H(p)<δ−m (or H(p)−δ<−m) 时,交叉熵足够小,此样本视为已知样本,其交叉熵将会减小。
4.4.2 CLIP 引导的域适应
为提高 ODA 的性能,额外使用 CLIP 的 zert-shot 预测来训练 F o d a F_{oda} Foda,根据 CLIP 的预测 H ( p ^ ) \mathcal{H}(\hat p) H(p^) 检测出未知样本。将检测出的目标位置样本表示为 D ^ t u n k \hat{D}_{t}^{unk} D^tunk,在 D t D_t Dt 中, H ( p ^ ) > δ \mathcal{H}(\hat p)>\delta H(p^)>δ;剩下的已知样本为 D ^ t k w n \hat{D}_{t}^{kwn} D^tkwn,其中 H ( p ^ ) < = δ \mathcal{H}(\hat p)<=\delta H(p^)<=δ。
对于目标已知样本 D ^ t k w n \hat{D}_{t}^{kwn} D^tkwn,直接使用 CLIP 的 zero-shot 预测作为伪标签来训练 F o d a F_{oda} Foda :
L k w n ( D ^ t k w n ) = − 1 ∣ D ^ t k w n ∣ ∑ i = 1 ∣ D ^ t k w n ∣ ∑ k = 1 ∣ C s ∣ p ^ ( k ∣ x t i ) log p ( k ∣ x t i ) \mathcal{L}_{kwn}(\hat{D}_{t}^{kwn})=-\frac1{|\hat{D}_{t}^{kwn}|}\sum_{i=1}^{|\hat{D}_{t}^{kwn}|}\sum_{k=1}^{|C_{s}|}\hat{p}(k|x_{t}^{i})\log p(k|x_{t}^{i}) Lkwn(D^tkwn)=−∣D^tkwn∣1i=1∑∣D^tkwn∣k=1∑∣Cs∣p^(k∣xti)logp(k∣xti)
对于目标未知样本 D ^ t u n k \hat{D}_{t}^{unk} D^tunk,增加其输出的交叉熵:
L u n k ( D ^ t u n k ) = 1 ∣ D ^ t u n k ∣ ∑ i = 1 ∣ D ^ t u n k ∣ − H ( p ^ ) \mathcal{L}_{unk}(\hat{D}_t^{unk})=\frac1{|\hat{D}_t^{unk}|}\sum_{i=1}^{|\hat{D}_t^{unk}|}-\mathcal{H}(\hat{p}) Lunk(D^tunk)=∣D^tunk∣1i=1∑∣D^tunk∣−H(p^)
4.5 整体目标函数
总结:交叉熵优化框架执行的是源域样本监督训练,目标样本的交叉分离,CLIP 引导的域适应,ODA 的整体学习目标为:
min F o d a L t o t a l = L s ( D s ) + L e n t ( D t ) + L k w n ( D ^ t k w n ) + L u n k ( D ^ t u n k ) \operatorname*{min}_{F_{oda}}\mathcal{L}_{total}=\mathcal{L}_s(D_s)+\mathcal{L}_{ent}(D_t) +\mathcal{L}_{kwn}(\hat{D}_{t}^{kwn})+\mathcal{L}_{unk}(\hat{D}_{t}^{unk}) FodaminLtotal=Ls(Ds)+Lent(Dt)+Lkwn(D^tkwn)+Lunk(D^tunk)
对于 SF-ODA,由于 D s D_s Ds 和 D t D_t Dt 在训练过程中并不能获得,于是用预训练在源域 D s D_s Ds 上的 ODA 模型 F o d a F_{oda} Foda 代替,采用标准监督分类器的学习方式训练:
min F o d a L p r e t r a i n = L s ( D s ) \min_{F_{oda}}\mathcal{L}_{pretrain}=\mathcal{L}_{s}(D_{s}) FodaminLpretrain=Ls(Ds)接下来进一步训练交叉分离和 CLIP 引导的 D t D_t Dt 上的域适应:
min F o d a L t o t a l = L e n t ( D t ) + L k w n ( D ^ t k w n ) + L u n k ( D ^ t u n k ) \min_{F_{oda}}\mathcal{L}_{total}=\mathcal{L}_{ent}(D_t)+\mathcal{L}_{kwn}(\hat{D}_t^{kwn})+\mathcal{L}_{unk}(\hat{D}_t^{unk}) FodaminLtotal=Lent(Dt)+Lkwn(D^tkwn)+Lunk(D^tunk)
五、实验
5.1 实验步骤
5.1.1 数据集

5.1.2 与其他方法的比较
两个 baseline:CLIP 的 zero-shot 预测;仅标签源域和基于交叉熵检测到的未知类别训练的模型。两个 ODA 方法:DANCE、OVA。两个 SF-ODA 方法:SHOT、OneRing。
5.1.3 评估附件
使用 H-score 指标,当未知类别被认为是一个统一的标签时,H-score 得分为已知类别 a c c k w n \mathrm{acc}_{kwn} acckwn 和 统一的未知类别 a c c u n k \mathrm{acc}_{unk} accunk 的调和平均数:
H s c o r e = 2 a c c k w n ⋅ a c c u n k a c c k w n + a c c u n k H_{score}=\frac{2\mathrm{acc}_{kwn}\cdot\mathrm{acc}_{unk}}{\mathrm{acc}_{kwn}+\mathrm{acc}_{unk}} Hscore=acckwn+accunk2acckwn⋅accunk当且仅当 a c c k w n \mathrm{acc}_{kwn} acckwn 和 a c c u n k \mathrm{acc}_{unk} accunk 非常大时,H-score 才大。在所有实验中采用不同的随机种子进行实验。
5.1.4 实施细节
预训练在 Image-Net 上的 ResNet-50 作为 ODA 模型 F o d a F_{oda} Foda,交叉熵阈值设置为 log ( ∣ C s ∣ ) 2 \frac{\log(|C_s|)}2 2log(∣Cs∣),分离的边界值 m = 0.5 m=0.5 m=0.5。
5.2 实验结果
主要结果

CLIP 的 zero-shot 和提出方法的比较



每个数据集的细节结果


5.3 消融实验

六、局限性及将来的工作
微调 CLIP 值得考虑,但计算成本需要关注,同时需要关注微调模型会使得过拟合源域的数据。引入更加复杂模型应用于 ODA 任务留待将来的工作。
七、结论
本文提出用 CLIP 来增强 ODA 的性能。为解决知识在不同类别中的迁移,使用 CLIP 模型的 zero-shot 预测能力来增强 ODA 模型的性能。实验表明方法很有效,超出了当前的 ODA 和 SF-ODA 的 SOTA 方法。
写在后面
这篇文章还是有点看不懂的感觉,虽然公式较少,但代码没有给出,略微有点遗憾。值得称赞的是论文的写作水平比较高明,外行读者也能看懂。有些瑕疵的地方在于摘要部分衔接不够流程,还有论文的图 1 并未在原文中引用到。