文章目录
概述
基本推导和理论还是以看李航老师的《统计学习方法》为主。
各种算法的原理,推荐理解到可以手撕的程度。
以下为通过网络资源搜集整理的一些问题及答案,准备的有些仓促,没能记录所有资料的来源(侵删)
SVM原理及推导
https://download.csdn.net/download/yolohohohoho/10966848
SVM与随机森林比较
随机森林优点
1、在当前的很多数据集上,相对其他算法有着很大的优势,表现良好
2、它能够处理很高维度(feature很多)的数据,并且不用做特征选择
3、在训练完后,它能够给出哪些feature比较重要
4、 在创建随机森林的时候,对generlization error使用的是无偏估计,模型泛化能力强
5、训练速度快,容易做成并行化方法,训练时树与树之间是相互独立的
6、 在训练过程中,能够检测到feature间的互相影响
7、 实现比较简单
8、 对于不平衡的数据集来说,它可以平衡误差。
1)每棵树都选择部分样本及部分特征,一定程度避免过拟合;
2)每棵树随机选择样本并随机选择特征,使得具有很好的抗噪能力,性能稳定;
对缺失值不敏感,如果有很大一部分的特征遗失,仍可以维持准确度
随机森林有out of bag,不需要单独换分交叉验证集
。
随机森林缺点:
1) 参数较复杂;
2) 模型训练和预测都比较慢。
SVM的优点:
• 能够处理大型特征空间
• 能够处理非线性特征之间的相互作用
• 无需依赖整个数据
SVM的缺点:
• 当观测样本很多时,效率并不是很高
• 有时候很难找到一个合适的核函数
为此,我试着编写一个简单的工作流,决定应该何时选择这三种算法,流程如下:
• 首当其冲应该选择的就是逻辑回归,如果它的效果不怎么样,那么可以将它的结果作为基准来参考;
• 然后试试决策树(随机森林)是否可以大幅度提升模型性能。即使你并没有把它当做最终模型,你也可以使用随机森林来移除噪声变量;
• 如果特征的数量和观测样本特别多,那么当资源和时间充足时,使用SVM不失为一种选择。
SVM为什么要引入拉格朗日的优化方法。
化为对偶问题
对于SVM而言,原问题minwθp(w)=minwmaxα,β,αi≥0L(w,α,β)minwθp(w)=minwmaxα,β,αi≥0L(w,α,β)
不易求解,但由于原问题为二次规划问题,满足“strong duality”关系,故可解其对偶问题
SVM原问题和对偶问题关系?
- 目标函数对原始问题是极大化,对对偶问题则是极小化
- 原始问题目标函数中的收益系数(优化函数中变量前面的系数)是对偶问题约束不等式中的右端常数,而原始问题约束不等式中的右端常数则是对偶问题中目标函数的收益系数
- 原始问题和对偶问题的约束不等式的符号方向相反
- 原始问题约束不等式系数矩阵转置后即为对偶问题的约束不等式的系数矩阵
- 原始问题的约束方程数对应于对偶问题的变量数,而原始问题的变量数对应于对偶问题的约束方程数
- 对偶问题的对偶问题是原始问题
SVM从原始问题变为对偶问题来求解 的原因
1. 对偶问题将原始问题中的约束转为了对偶问题中的等式约束
2. 方便核函数的引入
3. 改变了问题的复杂度。由求特征向量w转化为求比例系数a,在原始问题下,求解的复杂度与样本的维度有关,即w的维度。在对偶问题下,只与样本数量有关。
SVM在哪个地方引入的核函数, 如果用高斯核可以升到多少维?
线性不可分时可以引入核函数
“如果映射后空间是k维的话,那内积矩阵的秩最大是k。而任给n个互不重合的样本,
Gaussian kernel的内积矩阵都是满秩的。所以你无论假设k是多少,都能找到n>k,矛
盾,所以必须是无限维的。 ”
SVM怎么防止过拟合 ?
如果支持向量中碰巧存在异常点,那么我们傻傻地让SVM去拟合这样的数据,最后的超平面就不是最优。
解决过拟合的办法是为SVM引入了松弛变量ξ(slack variable)。
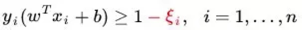
因此SVM公示中的目标函数也需要相应修改,我们加上松弛变量的平方和,并求最小值。这样就达到一个平衡:既希望松弛变量存在以解决异常点问题,又不希望松弛变量太大导致分类解决太差。
SVM的目标函数。
[TO-DO]
常用的核函数。
(1) 线性核函数
(2) 多项式核
(3) 径向基核(RBF)Gauss径向基函数则是局部性强的核函数,其外推能力随着参数的增大而减弱。多项式形式的核函数具有良好的全局性质。局部性较差。
(4) 傅里叶核
(5) 样条核
(6) Sigmoid核函数
核函数的选取标准:
• 如果如果特征数远远大于样本数的情况下,使用线性核就可以了.
• 如果特征数和样本数都很大,例如文档分类,一般使用线性核, LIBLINEAR比LIBSVM速度要快很多.
• 如果特征数远小于样本数,这种情况一般使用RBF.但是如果一定要用线性核,则选择LIBLINEAR较好,而且使用-s 2选项。
SVM硬软间隔对偶的推导
[TO-DO]