优化目标
-
对于逻辑回归的假设函数而言,在y=1的情况下,我们希望假设函数约等于1,且z远大于0;在y=0的情况下,我们希望假设函数约等于0,且z远小于0。
-
对于支持向量机,则希望在y=1的情况下,z大于等于0,;在y=0的情况下,z取其他值(小于0)
-
对于逻辑回归的代价函数,其中的 替代为 ,这两个函数的图如下:
其中的 替代为 ,这两个函数的图如下:
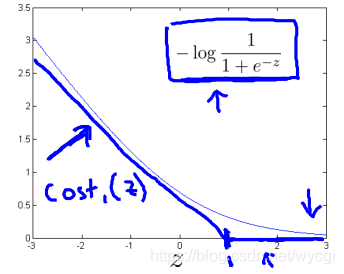
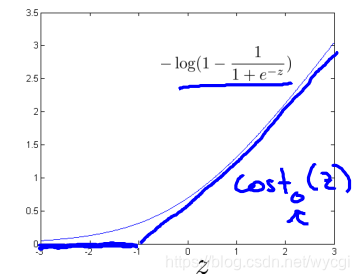
也就是说,在y=1的情况下,目标函数需要z大于等于1;在y=0的情况下,目标函数需要z小于等于-1。
- 对于支持向量机的代价函数而言,如上所述替代后,再去掉m项,将
用C代替(
),如下所示:
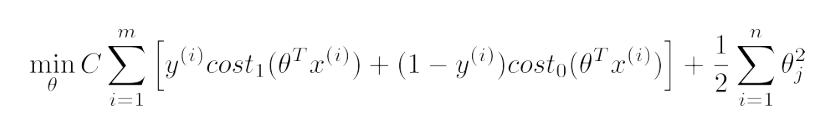
大间距分类器
如上所述,在y=1的情况下,目标函数需要z大于等于1;在y=0的情况下,目标函数需要z小于等于-1。
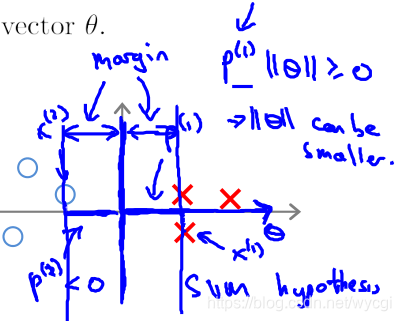
也就是说,对于决策边界(z=0)而言,与训练样本的距离尽量保持在1以上,因此会纠正过拟合的问题,取分类两组数据的中间,与双方保持一定距离的线为边界,如下方的margin(圆圈和红叉表示两种类型的样本):

但是如果C取值过大,也即
的值过小,即便采用上述算法还是会容易过拟合,如下:

数学原理
目标函数中,有该项 ,也即等同于求向量 的长度平方的二分之一: 。
因此,在决定决策边界时,如果如下图所示(
,相当于两个向量的内积):
由于上图所示,样本
投影到向量
(注意的是,向量
与决策边界垂直,因为与决策边界的内积z为0)上的值p较小,而为了与p值相乘大于等于1或小于等于-1,就会导致
的值较大,不符合目标函数的预期。
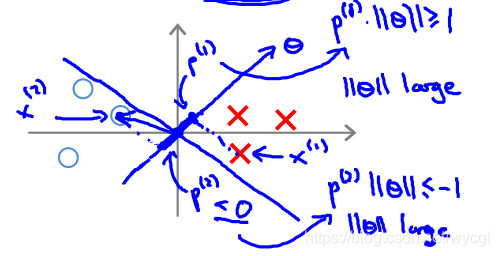
如果如下图所示:
那么,样本投影到向量 上得到的值p较大,同理,可知,能使 的值较小,符合目标函数的预期。
核函数一
对于非线性边界如下图所示的,在逻辑回归中通常采用多项式构造特征:
而如果采用支持向量机这一算法,那就要将
替代为
。
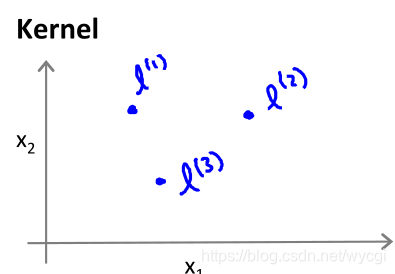
的定义如下:
其中的
为输入特征,
为下图中的点(可表示为长度为特征数目n的向量):
的性质有:如果
,则
;如果如果
与
相差过大,则
。

中的
过小时,容易低偏差,高方差,过大时容易高偏差,低方差,当
时,
的图像如下:
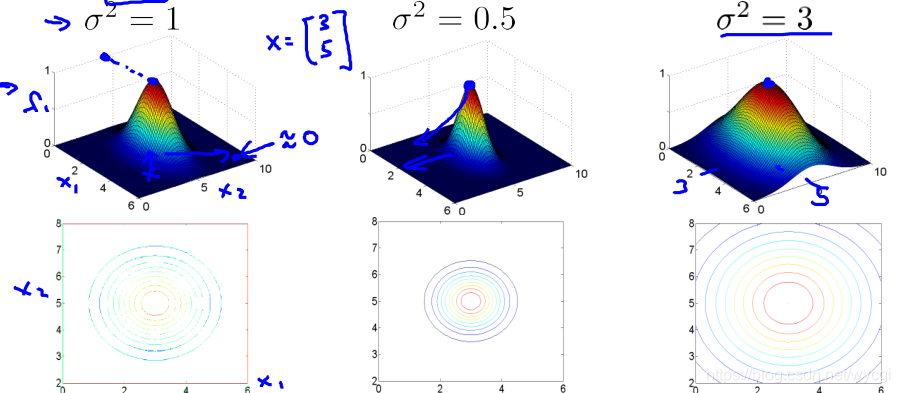
当 时,y=1。
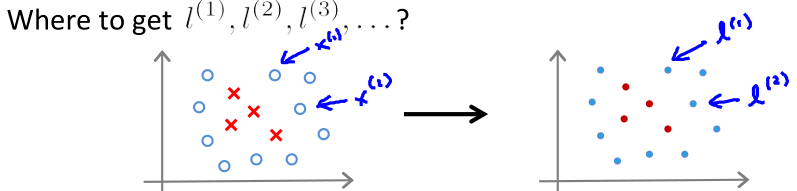
核函数二
如上图所示,将训练集
作为
,所以参数f是m+1维向量(包括
)。
代价函数:
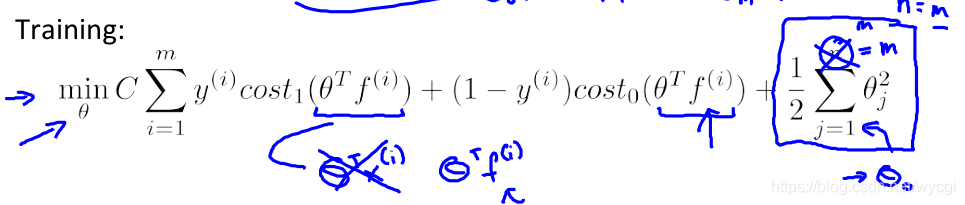
使用
-
需要制定C( )和 。但是线性核函数(大间距分类器)不用,上面的核函数一和核函数二指的是高斯核函数。
-
需要对x进行特征缩放或均值归一化,因为涉及平方,数据较大。
-
其他核函数:
-
对于多分类问题,可以像逻辑回归一样,训练多个分类器,一一分类即可。
-
如果特征数目比样本数量多(比如文本处理),则应该用线性核函数(大间距分类器)或逻辑回归,否则,应该用高斯核函数。
但是,如果样本数量特别多,比如样本数量50w以上,特征数目1k左右,则应当增加特征(多项式或额外特征),然后再用线性核函数(大间距分类器)或逻辑回归(因为在样本数量多的情况下,简单的算法反而比高级算法性能好) -
神经网络可以应用于上述大部分情况,不过运算量较大,可能处理过慢