支持向量机可用于分类、回归和异常检测,比如垃圾邮件检测等应用。
SVM的优势:1)在高维空间中非常有效
2)在数据维度比样本数量大的情况下仍然有效
3)高效利用内存
4)通用性:不同的核函数与特定的决策函数一一对应
SVM的缺点:1)在特征数量远大于样本数量时,选择核函数要避免过拟合
2)不直接提供概率估计
1、简单的SVC分类实例:
from sklearn import svm
X = [[0, 0], [1, 1]]
y = [0, 1]
# 获取SVM
clf = svm.SVC()
# 拟合数据
clf.fit(X, y)
# 预测新值
clf.predict([[2., 2.]])
# 获得支持向量
clf.support_vectors_
# 获得支持向量的索引
clf.support_
# 为每一个类别获得支持向量的数量
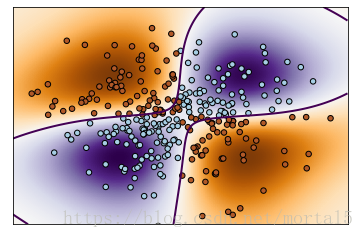
clf.n_support_非线性 SVM实例:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
xx, yy = np.meshgrid(np.linspace(-3, 3, 500),
np.linspace(-3, 3, 500))
np.random.seed(0)
X = np.random.randn(300, 2)
Y = np.logical_xor(X[:, 0] > 0, X[:, 1] > 0)
# fit the model
clf = svm.NuSVC()
clf.fit(X, Y)
# plot the decision function for each datapoint on the grid
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.imshow(Z, interpolation='nearest',
extent=(xx.min(), xx.max(), yy.min(), yy.max()), aspect='auto',
origin='lower', cmap=plt.cm.PuOr_r)
contours = plt.contour(xx, yy, Z, levels=[0], linewidths=2,
linetypes='--')
plt.scatter(X[:, 0], X[:, 1], s=30, c=Y, cmap=plt.cm.Paired,
edgecolors='k')
plt.xticks(())
plt.yticks(())
plt.axis([-3, 3, -3, 3])
plt.show()运行结果:
2、支持向量回归
支持向量分类生成的模型只依赖于训练集的子集, 因为构建模型的cost function不在乎边缘之外的训练点,类似的,支持向量回归生成的模型也只依赖于训练的子集,同样的原因,因为构建模型的cost function忽略任何接近于模型预测的训练数据。
支持向量分类有三种不同的实现形式:SVR、NuSVR和LinearSVR,在只考虑线性核的情况下,LinearSVR比SVR更快。
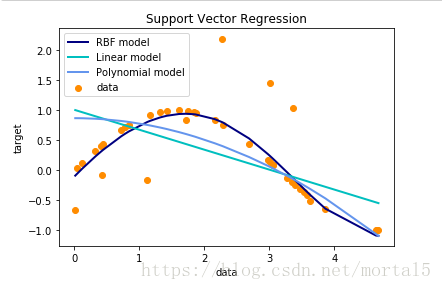
一个简单的基于线性和非线性核的支持向量回归 (SVR)实例:
import numpy as np
from sklearn.svm import SVR
import matplotlib.pyplot as plt
# Generate sample data
X = np.sort(5 * np.random.rand(40, 1), axis=0)
y = np.sin(X).ravel()
# Add noise to targets
y[::5] += 3 * (0.5 - np.random.rand(8))
# Fit regression model
svr_rbf = SVR(kernel='rbf', C=1e3, gamma=0.1)
svr_lin = SVR(kernel='linear', C=1e3)
svr_poly = SVR(kernel='poly', C=1e3, degree=2)
y_rbf = svr_rbf.fit(X, y).predict(X)
y_lin = svr_lin.fit(X, y).predict(X)
y_poly = svr_poly.fit(X, y).predict(X)
# Look at the results
lw = 2
plt.scatter(X, y, color='darkorange', label='data')
plt.plot(X, y_rbf, color='navy', lw=lw, label='RBF model')
plt.plot(X, y_lin, color='c', lw=lw, label='Linear model')
plt.plot(X, y_poly, color='cornflowerblue', lw=lw, label='Polynomial model')
plt.xlabel('data')
plt.ylabel('target')
plt.title('Support Vector Regression')
plt.legend()
plt.show()运行结果如下: