吴恩达深度学习专项课程的所有实验均采用iPython Notebooks实现,不熟悉的朋友可以提前使用一下Notebooks。
目录
1.实验综述

2.导入必要的包
import numpy as np
from emo_utils import * #把 ./emo_utils.py中的函数全部导入
#! pip install emoji #安装emoji
import emoji
import matplotlib.pyplot as plt
%matplotlib inline3.Baseline模型:Emojifier-V1
- EMOJISET数据集

X_train,Y_train = read_csv('data/train_emoji.csv')
X_test,Y_test = read_csv('./data/tesss.csv')查看read_csv函数的实现:
def read_csv(filename = 'data/emojify_data.csv'):
phrase = [] #存储所有句子
emoji = [] #存储句子对应的标签
with open (filename) as csvDataFile: #打开指定文件 读取
csvReader = csv.reader(csvDataFile) #定义一个csv读取器
for row in csvReader: #对于csv文件的每一行
phrase.append(row[0]) #将句子添加到phrase中
emoji.append(row[1]) #将标签添加到emoji中
#转变为数组
X = np.asarray(phrase)
Y = np.asarray(emoji, dtype=int)
return X, Y
maxLen = len(max(X_train,key=len).split()) #按长度找出最长的句子 对按空格其切分 返回一个列表 计算最长句子的长度
print(maxLen) #最长句子的长度
index = 5
print(X_train[index],label_to_emoji(Y_train[index]))
查看label_to_emoji()函数的实现:
#标签(string)到表情符号编码的映射字典
emoji_dictionary = {"0": "\u2764\uFE0F",
"1": ":baseball:",
"2": ":smile:",
"3": ":disappointed:",
"4": ":fork_and_knife:"}
def label_to_emoji(label):
"""
把一个标签 (int 或 string) 转换成对应的表情符号,以供打印。
"""
return emoji.emojize(emoji_dictionary[str(label)], use_aliases=True)
- Emojifier-V1模型

#五分类
Y_oh_train = convert_to_one_hot(Y_train,C=5)
Y_oh_test = convert_to_one_hot(Y_test,C=5)查看convert_to_one_hot函数:
def convert_to_one_hot(Y, C):
#Y.reshape[-1] 把Y从(m,1)->(1,m)
#np.eye(C)声明一个C*C的单位矩阵
#np.eye(C)[Y.reshape(-1)] 从单位矩阵中选出相应的行 如,Y中第一个数是2 则选出单位矩阵中的第三行 [0,0,1,0,...,0] 从而转换为one-hot形式
Y = np.eye(C)[Y.reshape(-1)]
return Y
接下来看看 convert_to_one_hot做了什么事情。修改index,打印不同的值。
index = 20
print(Y_train[index], 'is converted into one hot', Y_oh_train[index])
- 实现Emojifier-V1

word_to_index,index_to_word,word_to_vec_map = read_glove_vecs('./data/glove.6B.50d.txt')查看read_glove_vecs()函数:
def read_glove_vecs(glove_file):
with open(glove_file, 'r') as f: #打开./data/glove.6B.50d.txt读取
words = set() #定义单词集合
word_to_vec_map = {} #单词到向量的映射字典
for line in f: #对于文件中的每一行
line = line.strip().split() #去掉首尾空格,用空格切分该行 返回一个列表
curr_word = line[0] #列表第一个元素为 单词
words.add(curr_word) #将单词加入集合
word_to_vec_map[curr_word] = np.array(line[1:], dtype=np.float64) #列表其余元素为单词的向量表示 将单词及其嵌入表示加入映射字典
i = 1
words_to_index = {} #单词到索引的映射字典
index_to_words = {} #索引到单词的映射字典
for w in sorted(words): #对于排序后 单词集合中的每个单词
#第一个单词的索引为1 ,以此类推
words_to_index[w] = i
index_to_words[i] = w
i = i + 1
return words_to_index, index_to_words, word_to_vec_map

word = 'cucumber'
index = 289846
print('the index of ',word,' in the vocabulary is ',word_to_index[word])
print('the ',str(index)+'th word in the vocabulary is ',index_to_word[index])
# GRADED FUNCTION: sentence_to_avg
def sentence_to_avg(sentence, word_to_vec_map):
"""
将一个句子(字符串)转换为一个单词(字符串)列表. 提取每个单词的向量表示,并把这些单词的向量求平均,
得到一个单一向量,作为整个句子含义的编码/嵌入.
Arguments:
sentence -- 字符串,训练集X中的一个样本
word_to_vec_map -- 每个单词到其50维GloVe向量表示的映射字典。
Returns:
avg -- 对句子中所有单词的嵌入求平均,得到一个单一向量,对句子的信息进行编码, 数组维度 (50,)
"""
# Step 1: 把句子切分为单词列表(小写形式)
words = sentence.lower().split()
# 初始化平均向量,应该和词向量有相同的维度
avg = np.zeros(50)
# Step 2: 计算列表中每个单词词向量的平均,可以遍历列表中的每个单词
for w in words:
avg += word_to_vec_map[w]
avg = avg/len(words)
return avgavg = sentence_to_avg("Morrocan couscous is my favorite dish", word_to_vec_map)
print("avg = ", avg)

查看softmax():
def softmax(x):
"""计算x中每个得分值的softmax值."""
e_x = np.exp(x - np.max(x)) #x-np.max(x) 对x中的值先做一个平移 使其最大值为0 避免指数爆炸
return e_x / e_x.sum()
# GRADED FUNCTION: model
def model(X, Y, word_to_vec_map, learning_rate = 0.01, num_iterations = 400):
"""
训练模型
Arguments:
X -- 输入数据,字符串/句子数组 维度(m, 1) 包含m个句子/样本
Y -- 标签, 0-7之间的整数, 维度 (m, 1) 包含m个句子/样本对应的标签
word_to_vec_map -- 每个单词到其50维GloVe向量表示的映射字典。
learning_rate -- 随机梯度下降法的学习率
num_iterations -- 迭代次数
Returns:
pred -- 预测向量, 数组维度 (m, 1)
W -- softmax层的权重矩阵, 维度 (n_y, n_h)
b -- softmax层的偏置向量,维度 (n_y,)
"""
np.random.seed(1)
# 定义训练样本数
m = Y.shape[0] # 训练样本数
n_y = 5 # 分类类别数
n_h = 50 # GloVe嵌入向量的维度 50维
# 使用 Xavier 初始化模型参数
W = np.random.randn(n_y, n_h) / np.sqrt(n_h)
b = np.zeros((n_y,))
# 把标签Y转换为one-hot表示形式Y_oh,n_y个分类类别
Y_oh = convert_to_one_hot(Y, C = n_y)
# 优化循环
for t in range(num_iterations): # 迭代次数 epoch
for i in range(m): # 遍历每个训练样本
# 平均第i个训练样本中单词的词向量
avg = sentence_to_avg(X[i],word_to_vec_map)
# softmax层的前行传播
z = W.dot(avg) + b #(5,)
a = softmax(z)
# 用第i个训练样本的one-hot表示的标签 和 a(softmax输出)计算损失 (the output of the softmax)
cost = -np.sum(np.log(a)*Y_oh[i])
# 计算梯度
dz = a - Y_oh[i]
dW = np.dot(dz.reshape(n_y,1), avg.reshape(1, n_h))
db = dz
# 使用随机梯度下降法(每次梯度下降迭代使用一个训练样本)更新参数
W = W - learning_rate * dW
b = b - learning_rate * db
if t % 100 == 0:#每100个epoch打印一次损失 进行一次预测
print("Epoch: " + str(t) + " --- cost = " + str(cost))
pred = predict(X, Y, W, b, word_to_vec_map)
return pred, W, b查看predict()函数的实现:
def predict(X, Y, W, b, word_to_vec_map):
"""
给定X (m个句子/训练样本) 和 Y (m个句子对应的标签), 预测m个样本的标签 ,在给定集合上计算模型的准确率。
Arguments:
X -- 输入数据,包含若干训练样本/句子,数组维度 (m, None)
Y -- 标签, 整数包含表情对应的索引, 数组维度 (m, 1)
Returns:
pred -- 模型的预测结果 数组维度(m, 1)
"""
m = X.shape[0] #句子数/样本数
pred = np.zeros((m, 1))
for j in range(m): # 遍历所有的训练样本/句子
# 把第j个句子小写 再按空格进行切分 返回一个单词列表
words = X[j].lower().split()
# 平均这些单词的词向量
avg = np.zeros((50,))
for w in words:
avg += word_to_vec_map[w]
avg = avg/len(words)
# 前行传播
Z = np.dot(W, avg) + b
A = softmax(Z)
pred[j] = np.argmax(A) #最大值所在的索引 得到第j个句子的预测结果
#将pred和Y进行比较 计算准确率
print("Accuracy: " + str(np.mean((pred[:] == Y.reshape(Y.shape[0],1)[:]))))
return pred
print(X_train.shape)
print(Y_train.shape)
print(np.eye(5)[Y_train.reshape(-1)].shape)
print(X_train[0])
print(type(X_train))
Y = np.asarray([5,0,0,5, 4, 4, 4, 6, 6, 4, 1, 1, 5, 6, 6, 3, 6, 3, 4, 4])
print(Y.shape)
X = np.asarray(['I am going to the bar tonight', 'I love you', 'miss you my dear',
'Lets go party and drinks','Congrats on the new job','Congratulations',
'I am so happy for you', 'Why are you feeling bad', 'What is wrong with you',
'You totally deserve this prize', 'Let us go play football',
'Are you down for football this afternoon', 'Work hard play harder',
'It is suprising how people can be dumb sometimes',
'I am very disappointed','It is the best day in my life',
'I think I will end up alone','My life is so boring','Good job',
'Great so awesome'])
print(X.shape)
print(np.eye(5)[Y_train.reshape(-1)].shape)
print(type(X_train))

pred, W, b = model(X_train, Y_train, word_to_vec_map)
print(pred)
我们的模型已经在训练集上有一个相当高的准确率了。接下来看看他在测试集上的表现。
- 检查测试集表现
print("Training set:")
pred_train = predict(X_train, Y_train, W, b, word_to_vec_map)
print('Test set:')
pred_test = predict(X_test, Y_test, W, b, word_to_vec_map)
X_my_sentences = np.array(["i adore you", "i love you", "funny lol", "lets play with a ball", "food is ready", "not feeling happy"])
Y_my_labels = np.array([[0], [0], [2], [1], [4],[3]])
pred = predict(X_my_sentences, Y_my_labels , W, b, word_to_vec_map)
print_predictions(X_my_sentences, pred)
查看print_predictions()函数的实现:
def print_predictions(X, pred):
print() #换行
for i in range(X.shape[0]): #对于X中的每个样本/句子
print(X[i], label_to_emoji(int(pred[i]))) #打印句子,并将其对应的预测的整数标签转换为标签符号 打印出来
print(Y_test.shape)
print(' '+ label_to_emoji(0)+ ' ' + label_to_emoji(1) + ' ' + label_to_emoji(2)+ ' ' + label_to_emoji(3)+' ' + label_to_emoji(4))
print(pd.crosstab(Y_test, pred_test.reshape(56,), rownames=['Actual'], colnames=['Predicted'], margins=True))
plot_confusion_matrix(Y_test, pred_test)
查看plot_confusion_matrix()函数的实现:
def plot_confusion_matrix(y_actu, y_pred, title='Confusion matrix', cmap=plt.cm.gray_r):
df_confusion = pd.crosstab(y_actu, y_pred.reshape(y_pred.shape[0],), rownames=['Actual'], colnames=['Predicted'], margins=True)
df_conf_norm = df_confusion / df_confusion.sum(axis=1)
plt.matshow(df_confusion, cmap=cmap) # imshow
#plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(df_confusion.columns))
plt.xticks(tick_marks, df_confusion.columns, rotation=45)
plt.yticks(tick_marks, df_confusion.index)
#plt.tight_layout()
plt.ylabel(df_confusion.index.name)
plt.xlabel(df_confusion.columns.name)
4.Emojifier-V2:基于Keras使用LSTM

import numpy as np
np.random.seed(0)
from keras.models import Model
from keras.layers import Dense, Input, Dropout, LSTM, Activation
from keras.layers.embeddings import Embedding
from keras.preprocessing import sequence
from keras.initializers import glorot_uniform
np.random.seed(1)- 模型概况

- Keras和mini-batching

- 嵌入层

# GRADED FUNCTION: sentences_to_indices
def sentences_to_indices(X, word_to_index, max_len):
"""
把一个句子(字符串)数组转换为一个索引数组,其中索引对应句子中的每个单词.
输出维度是上图描述的`Embedding()`层的输出维度。
Arguments:
X -- 句子(字符串)数组 维度 (m, 1) 包含m个句子
word_to_index -- 每个单词到其对应索引的映射字典
max_len -- X中句子的最大长度,包含的最大单词数. 可以假设X中的每个句子都不比它长。
Returns:
X_indices -- 索引数组 对应X中每个句子中的每个单词的索引, 维度 (m, max_len)
"""
m = X.shape[0] # 训练样本数
# 初始化X_indices为0 注意维度
X_indices = np.zeros((m,max_len))
for i in range(m): # 遍历训练样本/句子
# 对第i个句子转化为小写并按空格进行切分 返回一个单词列表
sentence_words = X[i].lower().split()
# 初始化j为0
j = 0
# 遍历sentence_words中的每个单词
for w in sentence_words:
# X_indices的第(i,j)项设置为该单词对应的正确索引
X_indices[i, j] = word_to_index[w]
# j递增
j = j+1
return X_indicesX1 = np.array(["funny lol", "lets play baseball", "food is ready for you"])
X1_indices = sentences_to_indices(X1,word_to_index, max_len = 5)
print("X1 =", X1)
print("X1_indices =", X1_indices)
# GRADED FUNCTION: pretrained_embedding_layer
def pretrained_embedding_layer(word_to_vec_map, word_to_index):
"""
创建 Keras Embedding() 层 加载预训练的GloVe 50维向量.
Arguments:
word_to_vec_map -- 词到其GloVe嵌入表示的映射字典
word_to_index -- 词到其在词典中对应索引的映射字典(400,001 words)
Returns:
embedding_layer -- 预训练的Keras层的实例
"""
vocab_len = len(word_to_index) + 1 # 加1以适应 Keras embedding (requirement)
emb_dim = word_to_vec_map["cucumber"].shape[0] # GloVe 词嵌入的维度 (= 50)
# 以一个正确的维度初始化嵌入矩阵(数组)为0. (vocab_len, dimensions of word vectors = emb_dim)
emb_matrix = np.zeros((vocab_len,emb_dim))
# 设置嵌入矩阵的每一行/index为词典中第index个单词的嵌入表示
for word, index in word_to_index.items():
emb_matrix[index, :] = word_to_vec_map[word]
# 使用正确的输入输出维度来定义Embedding层, 使其 trainable. 使用 Embedding(...)时. 确保设置 trainable=False.
embedding_layer = Embedding(vocab_len,emb_dim,trainable=False)
# 构建 embedding 层, 需要在设置embedding 层权重之前. 不要修改 "None".
embedding_layer.build((None,))
# 设置嵌入层的权重为嵌入矩阵. 该层现在为预训练.
embedding_layer.set_weights([emb_matrix])
return embedding_layerembedding_layer = pretrained_embedding_layer(word_to_vec_map, word_to_index)
print("weights[0][1][3] =", embedding_layer.get_weights()[0][1][3])
- 构建Emojifier-V2
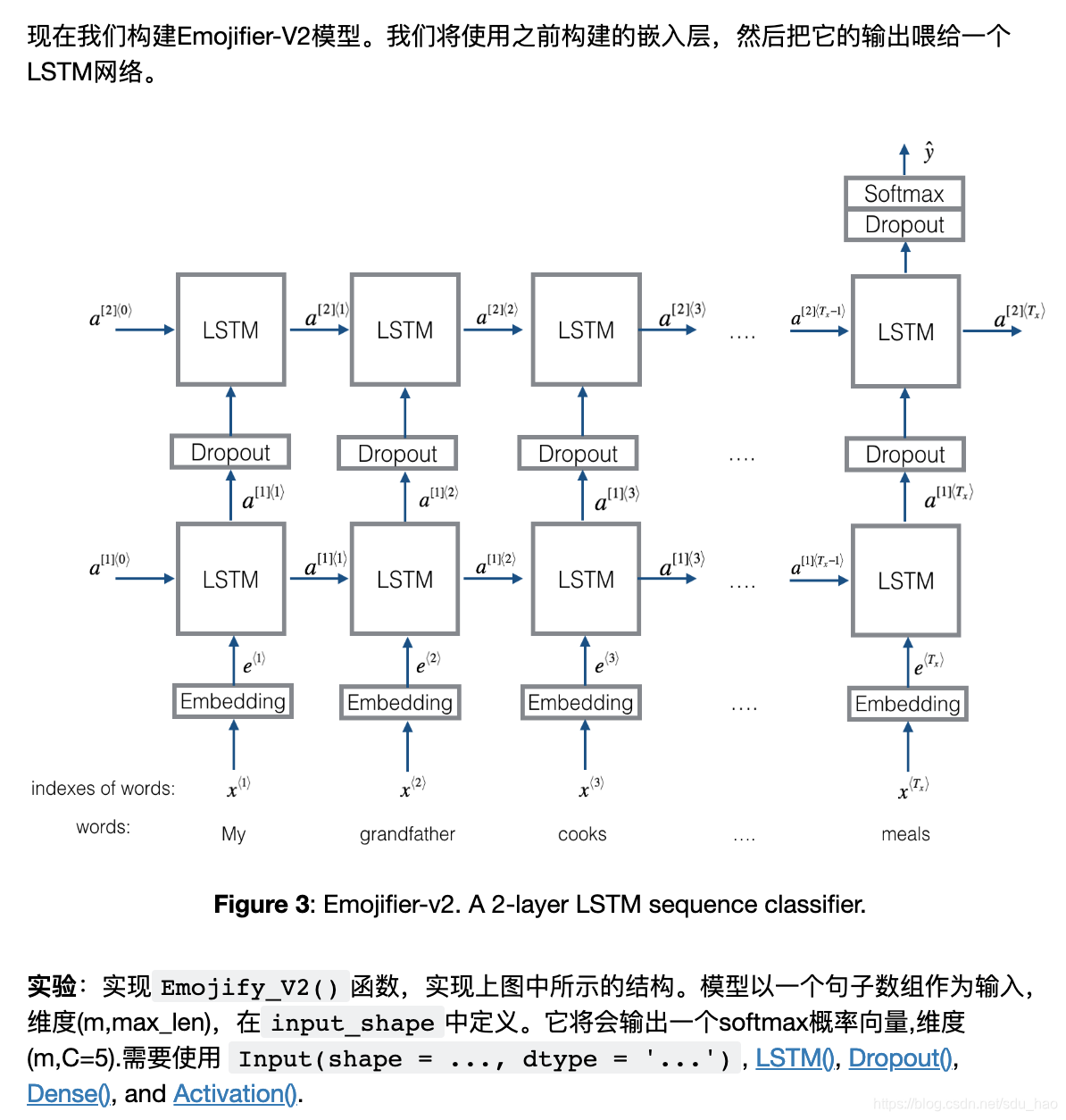
# GRADED FUNCTION: Emojify_V2
def Emojify_V2(input_shape, word_to_vec_map, word_to_index):
"""
构建 Emojify-v2 model的计算图.
Arguments:
input_shape -- 输入维度 一般为(max_len,)
word_to_vec_map -- 词到其GloVe嵌入表示的映射字典
word_to_index -- 词到其在词典中对应索引的映射字典(400,001 words)
Returns:
model -- Keras中的模型实例
"""
# 定义句子索引为图的输入, 维度是 input_shape, dtype是 'int32' (因为包含的是整数索引).
sentence_indices = Input(shape=input_shape,dtype='int32')
# 使用预训练的GloVe向量 构建嵌入层
embedding_layer = pretrained_embedding_layer(word_to_vec_map,word_to_index)
# 把句子索引通过嵌入层, 得到嵌入
embeddings = embedding_layer(sentence_indices)
# 将 embeddings 前向通过一个LSTM层,隐藏单元维度128
# 注意,返回的输出应该是一批序列
X = LSTM(128,return_sequences=True)(embeddings)
# 添加dropout 0.5
X = Dropout(0.5)(X)
# 将X前向传播经过另一个 LSTM 层, 隐藏单元维度128
# 注意,返回的输出不是一批序列,而是一个单一的隐藏状态
X = LSTM(128)(X) #return_sequences=False(默认)只在最后一个时间步骤输出
# 添加dropout 0.5
X = Dropout(0.5)(X)
# X通过一个Dense层,使用softmax激活函数, 得到一批5-维向量输出(5分类).
X = Dense(5)(X)
# 添加Softmax激活函数
X = Activation('softmax')(X)
# 创建模型实例
model = Model(inputs = sentence_indices,output=X)
return model

model = Emojify_V2((maxLen,), word_to_vec_map, word_to_index)
model.summary()

model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
X_train_indices = sentences_to_indices(X_train, word_to_index, maxLen)
Y_train_oh = convert_to_one_hot(Y_train, C = 5)
model.fit(X_train_indices,Y_train_oh,epochs=50,batch_size=32,shuffle=True)
模型在训练集上的准确率接近100%,接下来在测试集上评估你的模型。
X_test_indices = sentences_to_indices(X_test, word_to_index, max_len = maxLen)
Y_test_oh = convert_to_one_hot(Y_test, C = 5)
loss, acc = model.evaluate(X_test_indices, Y_test_oh)
print()
print("Test accuracy = ", acc)
# 这段代码允许你查看误分的样本
C = 5
y_test_oh = np.eye(C)[Y_test.reshape(-1)]
X_test_indices = sentences_to_indices(X_test, word_to_index, maxLen)
pred = model.predict(X_test_indices)
for i in range(len(X_test)):
x = X_test_indices
num = np.argmax(pred[i])
if(num != Y_test[i]):
print('Expected emoji:'+ label_to_emoji(Y_test[i]) + ' prediction: '+ X_test[i] + label_to_emoji(num).strip())
在你自己的样本上运行模型。写下你自己的句子。
#随意更改下面的句子 来查看模型的预测。确保所有单词在GloVe嵌入中。
x_test = np.array(['not feeling happy'])
x_test_indices = sentences_to_indices(x_test,word_to_index,maxLen)
print(x_test[0]+' '+ label_to_emoji(np.argmax(model.predict(x_test_indices))))