
作者:邓杨
本文约6300字,建议阅读10分钟本文根据提出GAT文章Velickovic et al.(2017)中论述的顺序,简单介绍一下GAT的工作原理。数无形时少直觉,形少数时难入微–华罗庚
1 图注意力神经网络的介绍
1.1GAT的原理与特性
图形,由点、线、面和体构成,代表了一种理解抽象概念和表达抽象思想的有效工具。图形语言的优势在于其跨越语言障碍的能力,这种能力和技术大多是人类为了理解世界而发展出来的。计算机科学和人工智能的快速进步,使得理解和学习事物之间的更深层次客观关系变得可能。图神经网络(GNN)的诞生,更加帮助人类通过图形来了解和解决问题。图注意力神经网络(GAT)是一种专为处理图结构数据而设计的特殊神经网络。不同于传统神经网络,GAT在处理输入数据时,会充分考虑数据间的关系,使其在处理图结构数据时能更准确地捕捉到数据间的关联性。GAT的主要优势在于其自动学习节点间关系的能力,无需人工预设。
GAT的核心工作原理是通过注意力机制来计算节点间的关系。在传统神经网络中,每个节点的状态更新是独立进行的。而在GAT中,每个节点的状态更新会考虑到其邻居节点的状态,GAT会计算一个节点与其邻居节点之间的注意力权重,然后根据这个权重来更新节点的状态。通过计算权重而更新 信息的方式使得GAT能更好地捕捉到图中的结构信息。在计算权重分值和捕捉信息的方面,GAT采用了类似于Transformer的掩蔽自注意力机制,由堆叠在一起的图注意力层构成,每个图注意力层获取节点嵌入作为输入,输出转换后的嵌入,节点嵌入会关注到它所连接的其他节点的嵌入(Velickovic et al.,2017)。在GAT的实际运算中,注意力分数的计算是通过一个名为“注意力头”的结构完成的。每个注意力头都会计算一组注意力分数,并且在最后的结果中,所有的注意力头的结果会被平均或者拼接起来,以得到最终的节点嵌入。这样做的好处是,每个注意力头可以关注到不同的特征或者模式,从而使得GAT能够捕捉到更多的信息。具体的数学内容将在下面的文章中解释。
此外,GAT引入了图池化的概念,这是一种选择最具信息的节点子集的方法,可以生成更具区分性的图。在图池化过程中,GAT使用一个可学习的投影向量来计算每个节点的投影分数,然后根据投 影分数来选择保留的节点。这种方式可以进一步提高GAT的性能。GAT还有一个重要特性是模型级别的融合。在处理复杂的问题时,GAT可以通过模型级别的融合来利用不同的信息源。这种能力已经使 得GAT在许多领域显示出其优越性,包括图像识别、自然语言处理和推荐系统等。在图像识别中,GAT 可以有效地处理图像中的像素之间的关系,从而提高图像识别的准确性。在自然语言处理中,GAT可以有效地处理文本中的词语之间的关系,从而提高文本理解的准确性。在推荐系统中,GAT可以有效地处理用户和商品之间的关系,从而提高推荐的准确性。
1.2GAT在生活中的例子
为了更加直观地理解图注意力神经网络(GAT),可以通过一个生活中的例子来揭示其工作原理和应用。
在中国的传统婚礼中,座位安排是一项重要的任务。主办方需要考虑所有宾客间的关系,以确保每个人在婚礼上都能享受到愉快的体验。这个过程可以被视为一个图,其中每个宾客代表一个节点,宾客间的关系代表边。主办方的目标是找到一个最优的座位安排,使得每个桌子的宾客都能和谐相处。
在GAT的框架下,这个过程被建模为一个注意力机制。每个节点(宾客)都用一个向量表示,称其为嵌入,可以被视为节点的特征或属性。在这个例子中,宾客的嵌入可能包括他们的年龄、性别、兴趣等信息。注意力机制的工作原理是通过计算每个节点(宾客)与其他节点(其他宾客)之间的相似度,来决定每个节点的重要性。这个相似度被称为注意力分数,它是通过一个叫做“点积注意力”的函数计算得出的。注意力分数越高,表示这个节点与其他节点的关系越好,他们被安排在同一个位置的可能性就越大。在这个例子中,如果两个宾客的注意力分数很高,那么他们可能会被安排在同一个桌子上。在这个过程中,GAT还会考虑到每个桌子的负责人。这个负责人需要有较高的注意力分数,因 为他需要照顾到桌子上的每一个宾客,确保他们都能享受到婚礼。这就像是在图中找出最重要的节点。
然而,就像在实际的婚礼座位安排中一样,GAT也有一些局限性。例如,如果宾客数量非常多,计算每个宾客的注意力分数可能会非常复杂。此外,GAT可能会忽略一些重要的信息,例如,一些宾客可能虽然与其他人的关系不是很好,但是他们可能是婚礼的重要人物。这就需要在计算注意力分数时,引入更多的信息,例如宾客的地位、他们对婚礼的贡献等。
总的来说,GAT是一种强大的工具,它可以帮助解决一些复杂的问题。然而,也需要理解它的局限性,并且在使用它的时候,需要考虑到问题的具体情况。通过将GAT与日常生活中的经验相联系,可以更好地理解和应用这个强大的工具。接下来本文将着重介绍GAT的工作原理以及部分算法的设计原理和数学知识。
2 GAT的工作原理
本文根据提出GAT文章Velickovic et al.(2017)中论述的顺序,简单介绍一下GAT的工作原理。如果初次接触图神经网络相关知识,推荐先移步至DGL Team (2023) and LabML Team (2023)了解基础相关工作。
GAT通常由多个单层图注意力层组成,以下为一个单层图注意力层的解释。N个点与F个特征的输入可以记为:
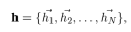 (1)
(1)
这里的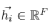 作为输入的特征。这样的输入层会对于点生成新的特征,所以输出结果可以表示为:
作为输入的特征。这样的输入层会对于点生成新的特征,所以输出结果可以表示为:
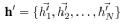 (2)
(2)
这里的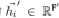 .为了将输入的特征转换为高维的特征,这里至少需要一个科学系的线性转换。在 (Velickovic et al.,2017)中,作者对于每一个点使用了一个共享的线性转换方式,同时介绍了一个权重矩阵
.为了将输入的特征转换为高维的特征,这里至少需要一个科学系的线性转换。在 (Velickovic et al.,2017)中,作者对于每一个点使用了一个共享的线性转换方式,同时介绍了一个权重矩阵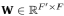 来参数化线性转换。
来参数化线性转换。
2.1自注意力机制(Self-Attention Mechanism)
区别于注意力机制,自注意力关注每一个点和自己的关系,而与每个点间重要关系不同,按照相应关系得出权重,将权重按照重要关系赋予点与点之间的连接上。结合上文提到的W, (Velickovic et al.,2017) 提出了自注意力机制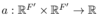 。因此,对于节点i来说,节点j的特征重要性可以用以下式子衡量:
。因此,对于节点i来说,节点j的特征重要性可以用以下式子衡量:
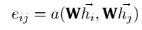 (3)
(3)
这样的机制可以让每个节点彼此之间产生联系,并且摒弃了所有的结构化新消息。
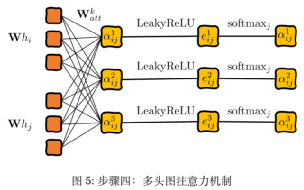
2.2多头注意力机制(Multi-head Attention)
相较于上述的单一注意力机制中对于h1的处理方法,多头注意力机制在每一个注意力头中获取一个h1k。多头注意力机制中每个头的特征值串联,串联后的特征以下方式表示:
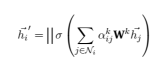 (4)
(4)
在多头注意力机制下,最终的输出值将不再是F’个特征,而是KF’ 个特征。对于重复计算得出的结果可以通过取平均值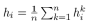 或者向量的连接(Concatenation)
或者向量的连接(Concatenation)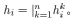
对于更细致的解释和数学推导,有兴趣的读者可以移步继续学习研究:(Graph Attention NetworksExperiment 2022;Graph Attention Networks 2022)。
2.3分步图示
本文参照(LaBonne,2022)的例子,更好地解释在节点中如何使用上文中提到的计算方法。对于节点1的embedding自注意力计算方法:
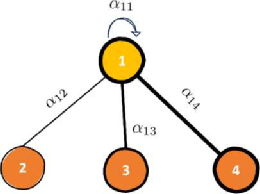
图1:例子图示
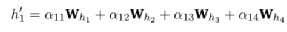 (5)
(5)
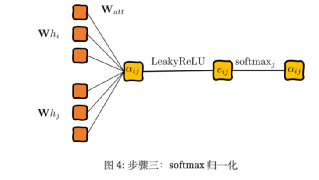
其中αij仍为节点之间特征关系的重要性,hi为每个点的属性向量。基于上面的计算方法,图注意力机制将计算出节点1的嵌入值。至于处理式子中的图注意力相关系数,要通过‘四步走’(LaBonne,2022):线性转换,激活函数,softmax归一化,以及多头的注意力机制来使用神经网络学习和节点1相关的注意力分数。
第一步,对于每个点与点之间连线的重要性计算,可以通过对于两点间的向量连接 (concatenate) 创造隐藏向量配对。为此,应用linear transformation与一个权重矩阵Watt来实现: 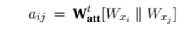
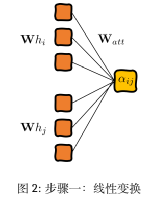 (6)
(6)
第二步,添加一个激活函数LeakyReLU:
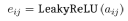
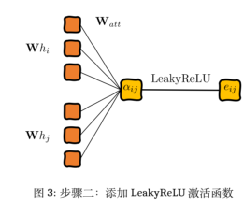 (7)
(7)
第三步,将神经网络的输出结果归一化,方便进行比较:
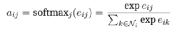
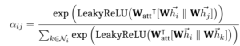
归一化后的注意力分值可以计算和比较,但同时产生了新的问题,即自注意力是非常不稳定的。Velickovic et al.,2017)对此提出了给予transformer结构的多头注意力机制。
 (8)(9)
(8)(9)
第四步,按照上文提到的多头注意力机制,这里用作处理和计算注意力繁分数:
3GAT在组合优化问题中的应用
3.1组合优化问题
组合优化问题是运筹学中的核心问题,也是学者开始学习运筹学的必经之路。组合优化问题是计算机科学和运筹学中的核心领域,涉及到许多实际应用,如物流、调度和网络设计等。组合优化问题 在许多实际应用中都起着至关重要的作用。例如,在物流领域,组合优化问题可以帮助人们在纷繁错 杂的运输条件中,找到最优的货物配送路线,从而节省运输成本和提高货运效率。在调度问题中,组合优化可以帮助人们有效地分配资源,以满足各种约束条件,同时最大化或最小化某个所需的某个目标值(通常称为目标函数)。
然而,传统的组合优化算法通常需要针对每个新问题从头开始设计,并且需要专家对问题结构进行仔细的考虑。解决组合优化问题通常需要大量的计算资源,特别是对于来源于现实的问题,通常情况下问题本身规模十分庞大,传统的优化算法可能无法在合理的时间内找到解决方案,甚至无法在可达的时间内求解。因此,如何有效地解决组合优化问题,一直是研究者们关注的焦点。近年来,使用马尔科夫链构造动态规划的方式,可以解决被表述为由状态、动作和奖励定义的单人游戏的组合优化问题,包括最小生成树、最短路径、旅行商问题(TSP)和车辆路径问题(VRP),而无需专家知识。这种方法使用强化学习训练图注意力神经网络(GNN),在未标记的图训练集上进行训练。训练后的网络可以在线性运行时间内输出新图实例的近似解。在TSP问题中,GAT可以有效地处理城市之间的距离关系,从而找到最短的旅行路径。在VRP问题中,GAT可以有效地处理车辆、客户 和仓库之间的关系,从而找到最优的配送路线。这些研究结果表明,GAT在解决组合优化问题方面,具 有巨大的潜力。
3.2GAT解决路径规划论文案例
(Kool et al.,2018)中提出了一种类似GAT的基于注意力机制的模型来解决不同的路径规划问题,包括TSP, VRP, OP等问题。本文主要是通过将路径规划问题(例如TSP)构造为基于图的问题,在TSP中 的每个顾客点位的位置以及其它信息作节点的特征。经由基于注意力机制的编码-解码器,得出路径结果即一个随机策略π(π|s), 使用此策略在给定的测试数据点中找到最有路径方法π,此方法被θ参数化并且分解为:
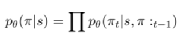 (10)
(10)
解码过程是顺序进行的。在每个时间步,解码器根据编码器的嵌入和在时间生成的输出来输出节点πt。在解码过程中,增加一个特殊的上下文节点来表示解码上下文。解码器在编码器的顶部计算一个注意力(子)层,但是只向上下文节点发送消息以提高效率。最后的概率是使用单头注意力机制计算的。在 时间t,解码器的上下文来自编码器和在时间t之前的输出。对于TSP来说包括图的嵌入,前一个(最 后一个)节点πt-1和第一个节点π1。同时为了计算输出概率,添加一个具有单个注意力头的最终解码器层。文章通过梯度下降优化损失L,使用REINFORCE梯度估计器和基线。文章使用Rollout基线,基线策略的更新是周期性的,也是较好的模型定义策略,用来确定性贪婪Rollout的解决方案。
文章还详细讨论了对于不同问题的处理策略,例如对于奖励收集旅行商问题(PCTSP),作者在编码器中使用了单独的参数来处理仓库节点,并且提供了节点奖励和惩罚作为输入特征。在解码器的上下文中,作者使用了当前/最后的位置和剩余的奖励来收集。在PCTSP中,如果剩余的奖励大于0且所有节点都没有被访问过,那么仓库节点不能被访问。只有当节点已经被访问过时,才会被屏蔽(即不 能被访问)。
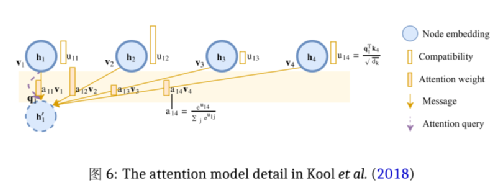
由于篇幅限制,本文只着重介绍Kool et al. (2018)是如何基于图注意力机制来构造在TSP中节点 间相互传递加权信息的算法。在文中构造的图中,节点接收到的带有权重的信息,来自于自己和周围的邻点们。而这些节点位的信息值是取决于其查询与邻居的键的兼容性,如Figure6所示。作者定义了dk, dv并设计计算了相应的ki∈ ℝdk, vi∈ ℝdv, qi∈ ℝdk。对于所有点位的对应qi ,ki,v i,通过以下方法 投影嵌入到hi来计算:
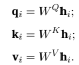
其中的WQ,WK是两组维数是dk ×dh的参数矩阵,WV的大小是(dv × dh). (推荐想深入了解Transformer中q, k, v设置与计算方法的读者,移步至WMathor (2020))
两点之间的兼容性,就是通过计算节点i的qi同j点的kj之间的值uij来实现的 (Velickovic et al.,2017):
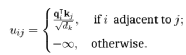 (11)
(11)
设置-∞避免了不相接的点互相传递信息,通过构建的兼容性,类似于Velickovic et al.(2017)中的eij, Khalil et al.(2017) 是这样计算注意力权重aij的:
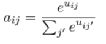 (12)
(12)
最终,节点i将接收到一个向量h’i,其中包含了向量vj的凸组合:
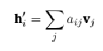 (13)
(13)
4结语
4.1GAT的未来发展和应用前景
图注意力网络(GAT)在解决组合优化问题,特别是旅行商问题(TSP)和车辆路径问题(VRP)等问题上的能力已经得到了广泛的证明。然而也需要注意到,虽然GAT在这些问题上表现出了优越性,但是它并不是万能的。对于一些特定的问题,可能需要设计特定的模型或者算法来解决。因此,在研究问题时,需要根据问题的具体情况,结合GAT解决问题的特性,选择合适的工具来解决不同的组合 优化问题。
在其它领域GAT也发挥着不同的作用,例如,Zhang et al. (2022)中提出了一种新的GAT架构,该架构可以捕获不同规模图知识之间的潜在关联。这种新的GAT架构在预测准确性和训练速度上都优于 传统的GAT模型。
此外,Shao et al.(2022)提出了一种新的动态多图注意力模型,该模型可以处理长期的时空预测问题。这种模型通过构建新的图模型来表示每个节点的上下文信息,并利用长期的时空数据依赖结构。这种方法在两个大规模数据集上的实验表明,它可以显著提高现有图神经网络模型在长期时空预测任务上的性能。
在股票市场预测方面,GAT也有着广泛的应用。Zhao et al. (2022)提出了一种基于双注意力网络的股票移动预测方法。首先构建了一个包含两种类型的实体(包括上市公司和相关的高管)和混合关系(包括显式关系和隐式关系)的市场知识图。然后,提出了一种双注意力网络,通过这个网络可以 学习到市场知识图中的动量溢出信号,从而进行股票预测。实验结果表明,该方法在股票预测方面的性能优于九种最先进的基线方法。
总的来说,图形的视角为研究提供了一种全新的方式来理解和解决问题。将已有的问题以图形的形式思考和转换,不仅可以揭示问题的新的方面和特性,而且还可能引发新的创新点。同样,将新的问题用图形方法思考,也可能带来意想不到的收获。这种方法的优点在于,它可以帮助学者更好地理解问题的结构和复杂性,从而找到更有效的解决方案。希望大家从本篇对于GAT的介绍开始,可以更多了解图神经网络的原理,更多地应用到自己的学 习和研究当中,通过使用GAT可以为解决问题提供强有力的支持。
作者简介
作者邓杨,西安交通大学管理学院-香港城市大学系统工程学院联合培养博三学生,研究方向为强化学习在城市物流中的应用。硕士毕业于南加州大学交通工程专业,荣誉毕业生。曾就职于工程咨询 企业HATCH洛杉矶办公室,加州注册EIT。曾获AACYF 2017年‘三十位三十岁以下优秀创业青年’、2019年‘全美十大华裔杰出青年’等称号。现为包头市海联会副会长、侨联、欧美同学会会员。
References
1.DGL Team. 9 Graph Attention Network (GAT) Deep Graph Library (DGL). https: //docs .dgl.ai/ en/0.8.x/tutorials/models/1_gnn/9_gat.html (2023).
2.Graph Attention Networks LabML. https://nn.labml.ai/graphs/gat/index.html (2023).
3.Graph Attention Networks Experiment LabML. https://nn.labml.ai/graphs/gat/experiment. html (2023).
4.Khalil, E., Dai, H., Zhang, Y., Dilkina, B. & Song, L. Learning combinatorial optimization algorithms over graphs. Advances in neural information processing systems 30 (2017).
5.Kool, W., Van Hoof, H. & Welling, M. Attention, learn to solve routing problems! arXiv preprint arXiv:1803.08475 (2018).
6.LabML Team. Graph Neural Networks LabML. https://nn.labml.ai/graphs/index.html (2023).
7.LaBonne, M. Graph Attention Networks: Theoretical and Practical Insights https : / / mlabonne . github.io/blog/posts/2022-03-09-graph_attention_network.html (2023).
8.Shao, W., Jin, Z., Wang, S., Kang, Y., Xiao, X., Menouar, H., Zhang, Z., Zhang, J. & Salim, F. Long-term Spatio-Temporal Forecasting via Dynamic Multiple-Graph Attention. arXiv preprint arXiv:2204.11008 (2022).
9.Velickovic, P., Cucurull, G., Casanova, A., Romero, A., Lio, P., Bengio, Y., et al. Graph attention networks. stat 1050, 10–48550 (2017).
10.WMathor. Graph Attention Networks https://wmathor.com/index.php/archives/1438/ (2023).
11.Zhang, W., Yin, Z., Sheng, Z., Li, Y., Ouyang, W., Li, X., Tao, Y., Yang, Z. & Cui, B. Graph attention multilayer perceptron in Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (2022), 4560–4570.
12.Zhao, Y., Du, H., Liu, Y., Wei, S., Chen, X., Zhuang, F., Li, Q. & Kou, G. Stock Movement Prediction Based on Bi-Typed Hybrid-Relational Market Knowledge Graph Via Dual Attention Networks. IEEE Transactions on Knowledge and Data Engineering (2022).REFERENCES
编辑:王菁
数据派研究部介绍
数据派研究部成立于2017年初,以兴趣为核心划分多个组别,各组既遵循研究部整体的知识分享和实践项目规划,又各具特色:
算法模型组:积极组队参加kaggle等比赛,原创手把手教系列文章;
调研分析组:通过专访等方式调研大数据的应用,探索数据产品之美;
系统平台组:追踪大数据&人工智能系统平台技术前沿,对话专家;
自然语言处理组:重于实践,积极参加比赛及策划各类文本分析项目;
制造业大数据组:秉工业强国之梦,产学研政结合,挖掘数据价值;
数据可视化组:将信息与艺术融合,探索数据之美,学用可视化讲故事;
网络爬虫组:爬取网络信息,配合其他各组开发创意项目。
点击文末“阅读原文”,报名数据派研究部志愿者,总有一组适合你~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派THUID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
未经许可的转载以及改编者,我们将依法追究其法律责任。
 点击“阅读原文”加入组织~
点击“阅读原文”加入组织~