(YOLO)You Only Look Once:Unified, Real-Time Object Detection
过程:
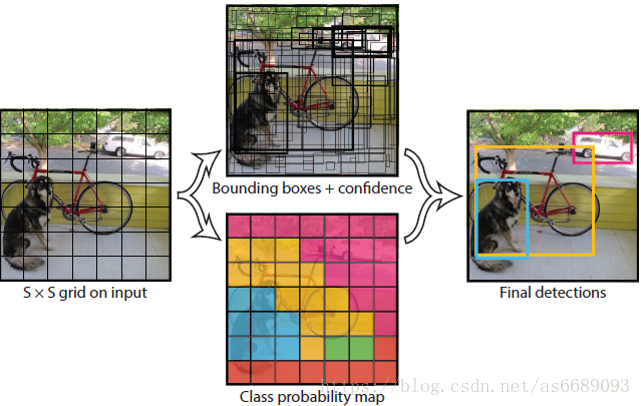
①将图像固定为448×448大小,送入卷积神经网络。
②划分成7×7 的网格,对于每个网格,我们都预测2个边框
(每个边框(x,y,w,h)是目标的置信度以及每个边框区域在多个类别上的概率)
③根据上一步可以预测出7×7×2个目标窗口,然后根据阈值去除可能性比较低的目标窗口,并用NMS去除冗余窗口,最后得到目标的边框信息和类别。
LOSS:
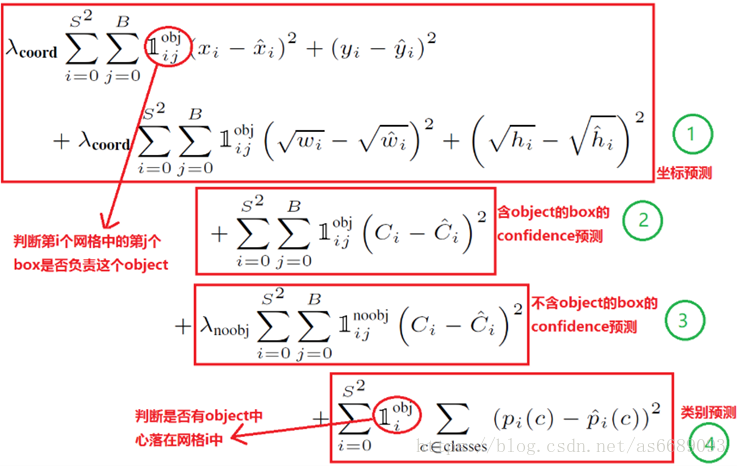
Loss = 位置相关误差(坐标、IOU)+分类误差
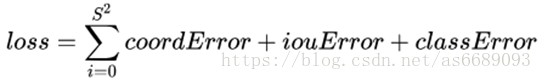
优点:
YOLO将目标检测任务转换成一个回归问题,大大加快了检测的速度,使得YOLO可以每秒处理45张图像(Faster RCNN每秒处理5张图像)
缺点:
没有了region proposal机制,只使用7×7的网格会使得目标不能非常精准的定位,这也导致了YOLO的检测精度并不是很高。
YOLO 9000: better, faster, stronger
改进:
(1)Batch Normalization(批标准化)【使用BN加速收敛】
在所有的卷积层上加入BN,让网络提高了收敛性,同时还消除了对其他形式的正则化(regularization)的依赖。
(2)High resolution classifier(高分辨率分类器)【提高图像分辨率】
分类网络以448×448(原224×224)的分辨率先在ImageNet上进行Fine Tune(微调),让网络能更好的运行在新分辨率上,再用高分辨率图像进行训练。
(3)Convolution with anchor boxes 【修改网络层、加入新结构】
去掉网络的全连接层,并使用Anchor Boxes来预测 Bounding Boxes。(该方法类似于SSD)
(4)Dimension clusters(尺寸聚类)
在YOLO中使用 anchor boxes 时,网络通过学习调整 boxes,为选择更好的先验知识,而非手工选择先验知识,使用 K 均值聚类方法自动找到好的先验知识。
(5)Direct location prediction(直接定位预测)
使用 anchor boxes 时,尤其在迭代初期模型会不稳定,这种不稳定性主要来自于矩形框坐标的预测。这里对位置预测加入了适当的约束参数,提高了稳定性。
(6)Fine-Grained Features(细粒度特征)【合理利用多层特征】
YOLO是在 13×13的特征图上进行预测的,这个尺寸对于大的物体是没有问题的,但是针对小目标,这里我们加入一个 a passthrough layer 引入上一层 26×26的卷积特征。将这两层特征综合起来进行预测。
(7)Multi-Scale Training 【训练集使用不同尺寸的图像】
网络只有卷积和池化,所以我们在训练时输入不同尺寸的图像,这使得我们的网络可以在不同输入尺寸图像上都有很好得检测效果。
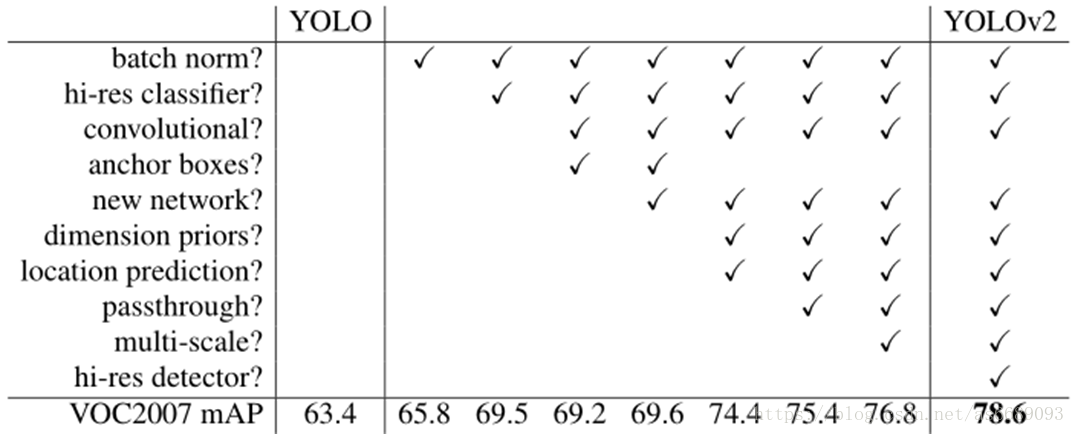
实验结果:
Detection frameworks on PASCAL VOC 2007
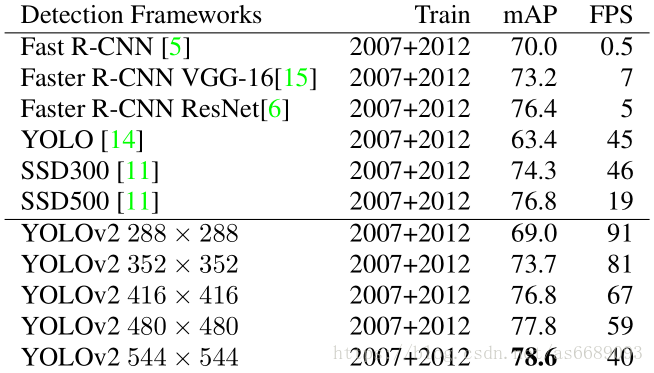
总结: better, faster, stronger
YOLO 9000 的网络结构允许实时地检测超过9000种物体分类,这归功于它能同时优化检测与分类功能。使用WordTree来混合来自不同的资源的训练数据,并使用联合优化技术同时在ImageNet和COCO数据集上进行训练,YOLO9000进一步缩小了监测数据集与识别数据集之间的大小代沟。
详细版本参考:
YOLO:
https://zhuanlan.zhihu.com/p/25236464
https://zhuanlan.zhihu.com/p/21412911
YOLO9000:
https://blog.csdn.net/hysteric314/article/details/53909408
https://blog.csdn.net/zhangjunhit/article/details/54631113