PASCAL VOC 数据集:https://blog.csdn.net/baidu_27643275/article/details/82754902
yolov1阅读笔记:https://blog.csdn.net/baidu_27643275/article/details/82789212
yolov1源码解析:https://blog.csdn.net/baidu_27643275/article/details/82794559
yolov2阅读笔记:https://blog.csdn.net/baidu_27643275/article/details/82859273
yolo9000论文提出了两个模型:yolov2和yolo9000。
yolov2是在yolov1的基础上改进得到的,yolo9000=yolov2+检测和分类联合训练算法。
一、yolov2改进策略
yolov1虽然检测速度快,但模型精度却不如基于区域的目标检测算法,与这些算法相比有如下问题:localization errors和 low recall。论文中提出了如下改进策略。

1、Batch Normalization
Batch Normalization,可以加速模型收敛,同时正则化模型,减少模型对其他正则化形式如dropout的需求。
在yolov2的所有卷积层中加入Batch Normalization,mAP提升超过2%。
2、High Resolution Classifier
目前所有先进的检测算法都会先在ImageNet中预训练一个分类器作为模型的主体(特征提取器),然后再在分类网络上微调得到检测网络,大部分分类网络的图片输入小于256×256。
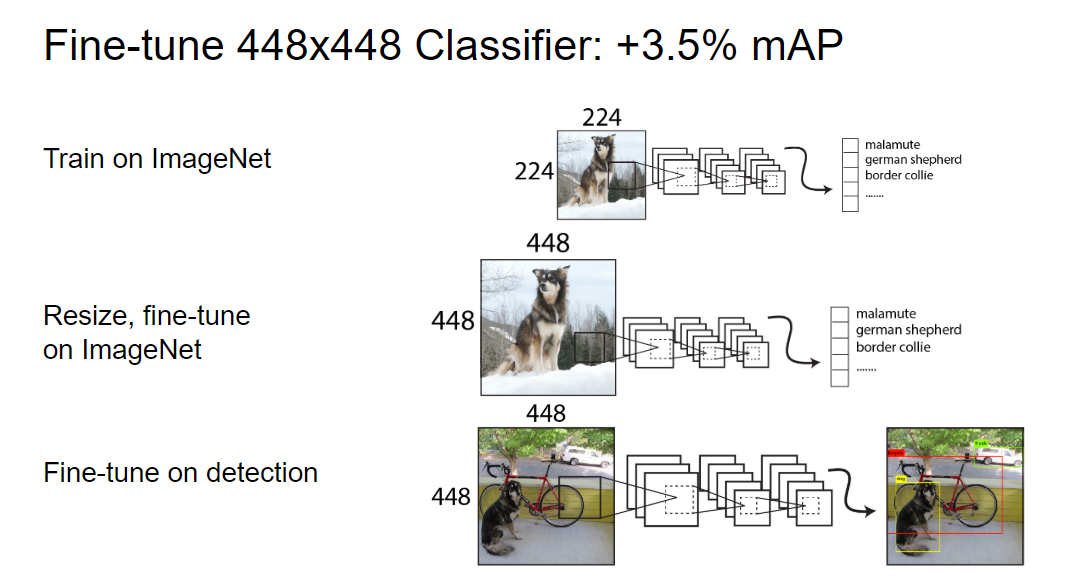
yolov1先在224×224上训练得到一个分类网络,然后再将分辨率提高至448×448在检测数据集上进行微调。分辨率突然提高,模型在学习目标检测时,还需要学习适应新的分辨率。
在yolov2中,我们首先在ImageNet上使用448×448的输入微调分类网络(10 epochs),网络有时间调整其fillters从而适应高分辨率的输入,然后再使用给高分率的分类网络在检测数据集上微调。使用高分率的分类网络可以使模型mAP提升大约4%。
3、Convolutional With Anchor Boxes
yolov1使用全连接层来预测bounding box的坐标,而Faster R-CNN使用了hand-picked priors策略。Faster R-CNN中的RPN部分使用卷积层来预测anchor box的offset和confidence,RPN会预测feature map每个位置的offset,这种预测offset的方式网络更易学习。
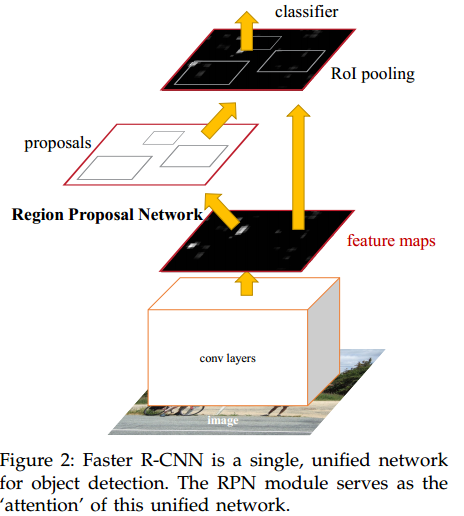
yolov2不使用全连接层而是用anchor box预测bounding box。
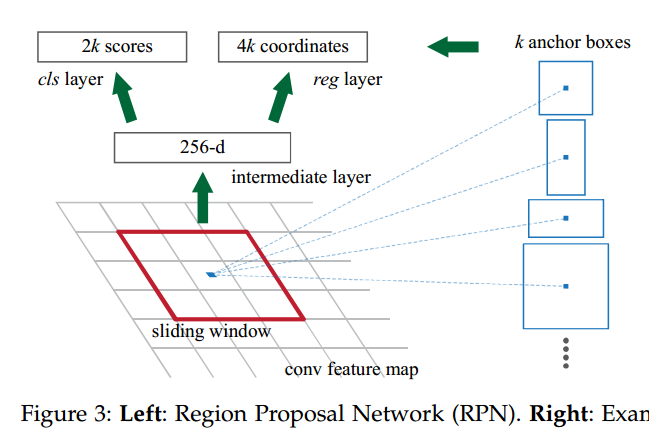
首先,去除一个pool层增加卷积层的输出分辨率。
另外,图片输入由448×448改为416×416,yolov2下采样32倍,416/32=13,这样feature map的维度为奇数(13×13)从而只有一个中心位置。因为大目标一般占据图片的中间位置,这样恰有一个中心位置来预测目标会比相邻的四个位置效果要好。
使用anchor box将类预测机制和空间位置解耦,每个anchor box都会预测class和objectness。class为条件概率,objectness为真实值和预测值的IOU。
Without anchor boxes our intermediate model gets 69:5 mAP with a recall of 81%. With anchor boxes our model gets 69:2 mAP with a recall of 88%.
使用anchor box后yolov2的mAP减小,但recall增加,这意味着模型有更大的提升空间。
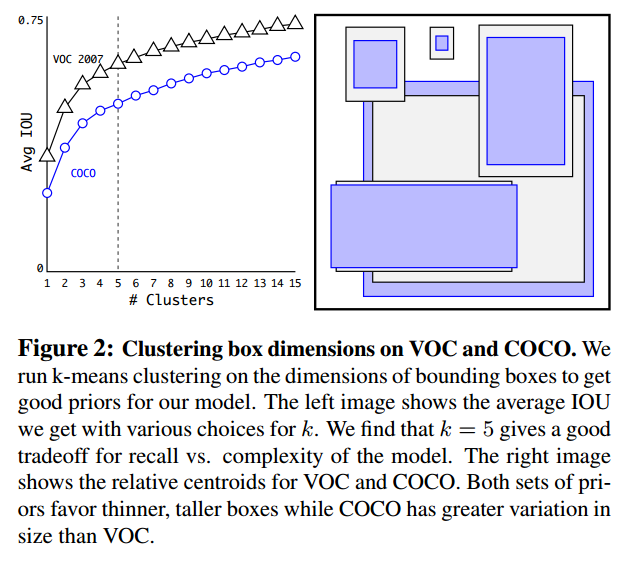
4、Dimension Clusters
使用anchor box会有两个问题,box dimension是其一。之前的box dimension都是hand picked然后网络再学习调整。但是如果我们能够找到一个好的初始priors,网络学习将更容易。
yolov2在训练集的bounding box上使用k-means自动学习好的priors。如果在k-means中使用欧式距离,大的框相对于小的会产生更多的错误。因此使用如下公式作为距离指标:
在模型复杂度和高recall中取一个折中值,我们将k-means的k值定为5。
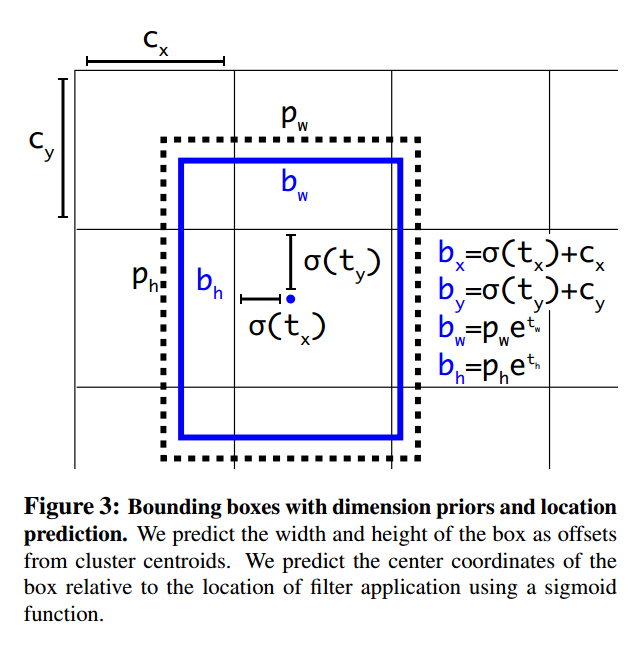
5、Direct Location prediction
在yolo中使用anchor box的另一个问题是:模型不稳定。
RPN网络预测四个值
、
、
、
,bounding box坐标
的计算如下:
若
,box向右移动
(width of anchor box)的距离;若
,box向左移动
的距离。这个公式没有约束条件,每个位置预测的边界框可以落在图片任何位置,这导致模型的不稳定性,在训练时需要很长时间来预测出正确的offsets。
在yolov2中不预测offset,而是借鉴yolov1中预测相对于每个网格的位置坐标的方法。使用sigmoid函数使得预测结果介于0-1之间。
网络在feature map的每个网格中预测5个bounding box,每个bounding box 预测5个值:
。
限制位置预测后,参数更易于学习,网络也更稳定。使用Dimension Clusters+Direct Location prediction,mAP提高大约5%。
6、Fine-Grained Features
yolov2在13×13的feature map预测box,对于大目标13×13已经足够,但是如果想要定位小目标,则需要更加精细的特征图。Faster R-CNN和SSD都是在多尺度特征图上来检测目标。
所以,YOLOv2使用两个feature map来预测box,YOLOv2所利用的Fine-Grained Features是 26×26 的feature map(最后一个maxpooling层的输入)
yolov2中加入passthrough层,passthrough层先将高分辨率feature map中的相邻特征堆叠到不同的通道中(26×26×512->13×13×2048),再和低分辨率的feature map(13×13)进行拼接,类似resnet中的恒等映射。
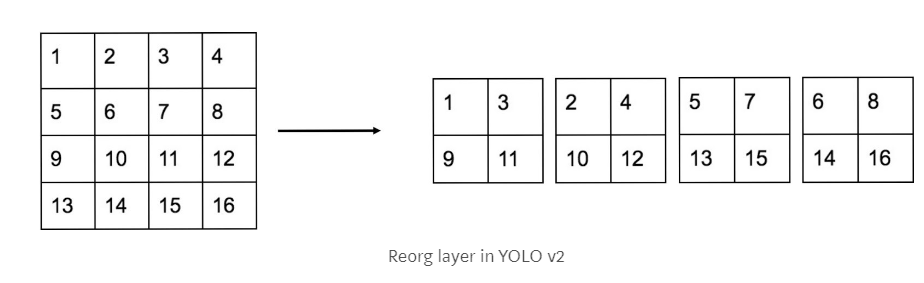
tensorflow实现:
# in为输入
out = tf.extract_image_patches(in, [1, stride, stride, 1], [1, stride, stride, 1], [1,1,1,1], padding="VALID")
# or use tf.space_to_depth
out = tf.space_to_depth(in, 2)
模型性能提升1%。
7、Multi-Scale Training
yolov2网络中只有卷积层和池化层,所以网络可以接受不同大小的图片。为了增强模型的鲁棒性,yolov2中使用了多尺度训练策略,每10个batch网络选择一个新的图片大小。yolov2模型下采样32倍,故从以下32的倍数中选择输入尺度:{320,352,…,608}。因此最小的输入尺度为320×320,最大为608×608.

二、yolov2训练
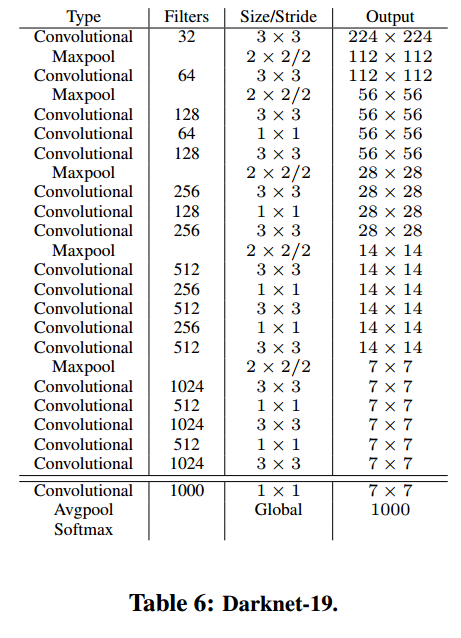
1、Darknet-19
Darknet-19有19个卷积层和5个最大池化层。
Darknet-19在3×3filter中间使用1×1的filter压缩特征;使用batch normalization加速模型收敛,正则化模型;激活函数使用leaky_Relu。
2、分类训练
先在ImageNet上预训练Darknet-19,输入为224×224,共训练160个epochs;然后改变输入为448×448,继续在ImageNet上微调模型,再训练10个epochs,得到分类网络。
3、检测训练
修改Darknet-19分类网络为检测网络:移除最后一个卷积层、global avgpooling层以及softmax层,并且新增了三个 3×3×1024卷积层,同时增加了一个passthrough层,最后使用 1×1 卷积层输出预测结果,输出的channels数为:
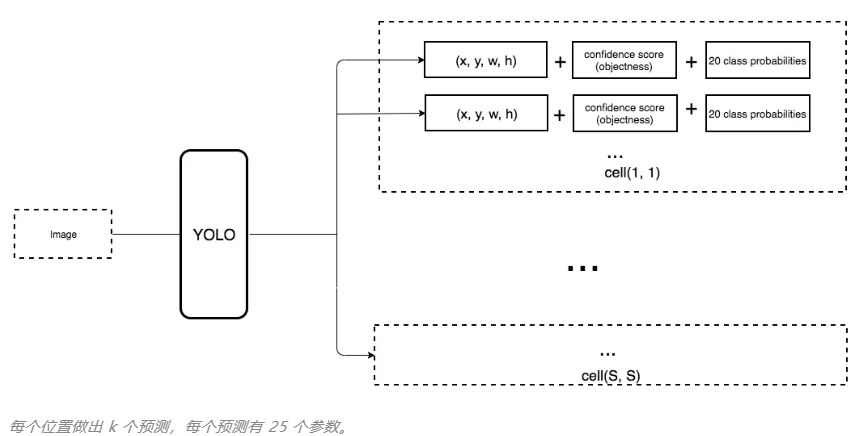
在VOC数据集上训练,每个位置预测5个box,每个box预测5个值:
,以及20个class。输出的channels数就是125;
在COCO数据集上训练,则有80个class,输出的channels数就是425

loss函数
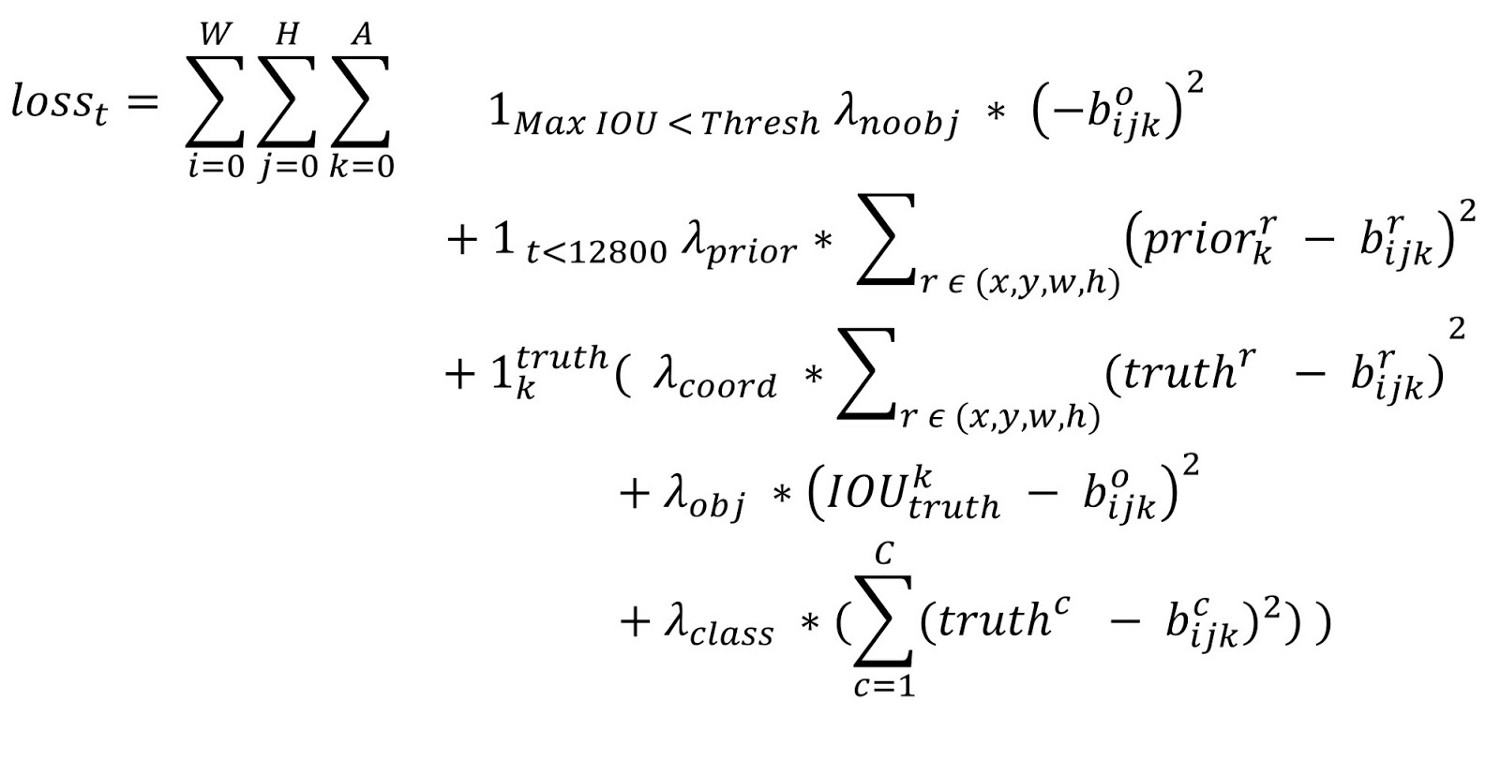
第一项loss是计算background的置信度误差
第二项是计算先验框与预测宽的坐标误差
第三大项计算与某个ground truth匹配的预测框各部分loss值,包括坐标误差、置信度误差以及分类误差。
三、yolov2网络部分的tensorflow实现:
yolov2除最后一层外其他conv层结构为:conv+batch_normalize+leaky_relu
最后一层不实用batch_normalize+leaky_relu
def leaky_relu(x):
return tf.nn.leaky_relu(x, alpha=0.1, name="leaky_relu")
# Conv2d
def conv2d(x, filters, size, pad=0, stride=1, batch_normalize=1,
activation=leaky_relu, use_bias=False, name="conv2d"):
if pad > 0:
x = tf.pad(x, [[0, 0], [pad, pad], [pad, pad], [0, 0]])
out = tf.layers.conv2d(x, filters, size, stride, use_bias=use_bias, name=name)
if batch_normalize == 1:
out = tf.layers.batch_normalization(out, name=name + "_bn")
if activation:
out = activation(out)
return out
# maxpool2d
def maxpool(x, size=2, stride=2, name="maxpool"):
return tf.layers.max_pooling2d(x, size, stride, name=name)
# reorg layer
def reorg(x, stride):
return tf.extract_image_patches(x, [1, stride, stride, 1],
[1, stride, stride, 1], [1, 1, 1, 1], padding="VALID")
# return tf.space_to_depth(x,stride)
def darknet(images, n_last_channels=425):
"""Darknet19 for YOLOv2"""
net = conv2d(images, 32, 3, 1, name="conv1")
net = maxpool(net, name="pool1")
net = conv2d(net, 64, 3, 1, name="conv2")
net = maxpool(net, name="pool2")
net = conv2d(net, 128, 3, 1, name="conv3_1")
net = conv2d(net, 64, 1, name="conv3_2")
net = conv2d(net, 128, 3, 1, name="conv3_3")
net = maxpool(net, name="pool3")
net = conv2d(net, 256, 3, 1, name="conv4_1")
net = conv2d(net, 128, 1, name="conv4_2")
net = conv2d(net, 256, 3, 1, name="conv4_3")
net = maxpool(net, name="pool4")
net = conv2d(net, 512, 3, 1, name="conv5_1")
net = conv2d(net, 256, 1, name="conv5_2")
net = conv2d(net, 512, 3, 1, name="conv5_3")
net = conv2d(net, 256, 1, name="conv5_4")
net = conv2d(net, 512, 3, 1, name="conv5_5")
shortcut = net
net = maxpool(net, name="pool5")
net = conv2d(net, 1024, 3, 1, name="conv6_1")
net = conv2d(net, 512, 1, name="conv6_2")
net = conv2d(net, 1024, 3, 1, name="conv6_3")
net = conv2d(net, 512, 1, name="conv6_4")
net = conv2d(net, 1024, 3, 1, name="conv6_5")
# ---------
net = conv2d(net, 1024, 3, 1, name="conv7_1")
net = conv2d(net, 1024, 3, 1, name="conv7_2")
# shortcut
shortcut = conv2d(shortcut, 64, 1, name="conv_shortcut")
shortcut = reorg(shortcut, 2)
net = tf.concat([shortcut, net], axis=-1)
net = conv2d(net, 1024, 3, 1, name="conv8")
# detection layer
net = conv2d(net, n_last_channels, 1, batch_normalize=0,
activation=None,use_bias=True, name="conv_dec")
return net
源码来自:https://github.com/xiaohu2015/DeepLearning_tutorials/tree/master/ObjectDetections/yolo2
参考:
YOLO9000: Better, Faster, Stronger
目标检测|YOLOv2原理与实现(附YOLOv3)