1. Abstract
-
论文提出了YOLO9000,一个可以检测超过9000种类别的模型。
-
YOLO9000提出的步骤:
- 首先提出YOLOv2,更快更准
- 然后提出一种把目标检测的数据(带有类别和边框)和分类数据(仅含有标签)结合起来一起训练的方法。
本人主要注重看YOLOv2的方法,YOLO9000对我来说暂时没用,因为不需要检测那么多类别的。
2. Introduction
没啥说的…
3. Better
- YOLOv1的不足:recall值太低了,相对于基于区域提取的方法来说。因为recall的公式是:
就是召回率等于正确预测出来的值除以 全部的ground truth,recall越小的话,说明还有很多本该预测出来的值没有被预测出来。
用一个图来总结YOLOv2比YOLO增加的东西:

由上图可见:
增加了:Batch Normalization、High Resolution Classifier、Dimansion Clusters等。下面具体来说一下。
增加的模块
- Batch Normalization
Batch normal-ization also helps regularize the model. With batch normalization we can remove dropout from the model without overfitting.
Batch Normalization(批量归一化)可以正则化模型,有了batch normalization就可以不用dropout了。 - High Resolution Classifier
之前的YOLO是训练Classifier网络时是用224x224,然后在检测时候提高分辨率到448,这样的话网络得同时学习目标检测和适应新的输入图像分辨率。现在YOLOv2在ImageNet预训练的时候,前10次用448
x448的分辨率的图像进行微调,然后再微调检测网络。这个方法提高了差不多4%的mAP。 - Convolutional With Anchor Boxes
这里学习了RPN(Region proposal network)的方法,用了Anchor Boxes,Anchor Boxes预测offsets而不是坐标,这样简化了问题同时也更加容易学习。
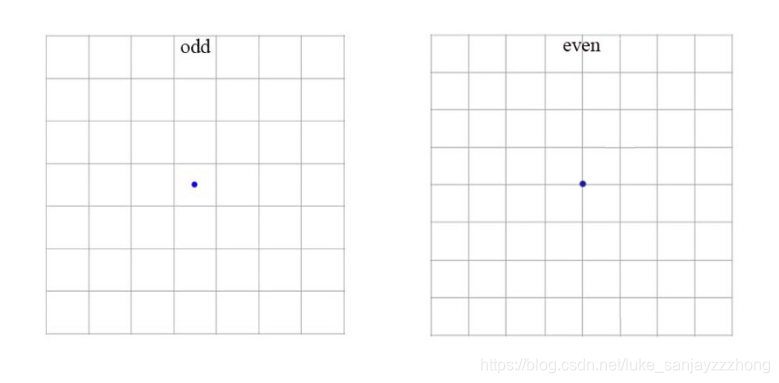
用了Anchor Boxes,为了能得到一个奇数(这样得到的中心坐标点才唯一),输入图像限制为416x416,然后通过卷积,缩放因子为32,所以最后得到的特征图为13x13(416/32).然而,用了Anchor Boxes,mAP较之不用Anchor Boxes降低了,reall增加了。下图展示了为什么要用416的大小。
- Dimension Clusters
为什么会提出这个维度簇这个东西了?因为在用Anchor boxes遇到了两个问题:- 很难选择box的x形状大小
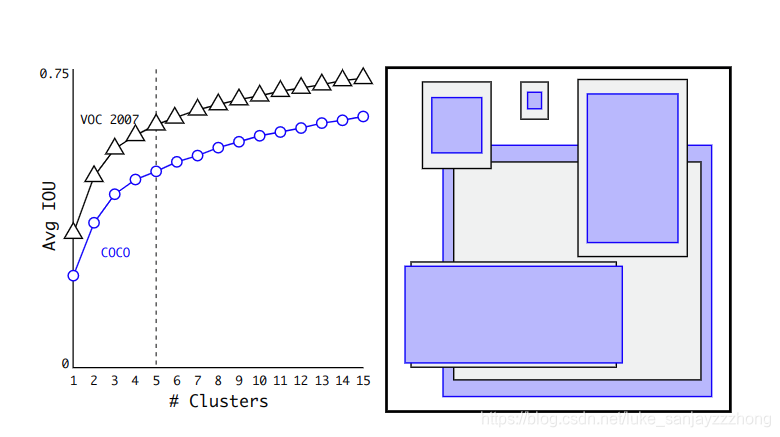
然后用k-means算法进行聚类(在ImageNet数据集上聚类),聚类的时候用欧几里得距离(也就是L2距离)进行计算。得出距离矩阵:
最后得出k=5时比较平衡。如下图:
- 很难选择box的x形状大小
- Direct location prediction
号称用新的位置预测算法来缩小参数范围,使之更容易学习,也使得网络更加稳定
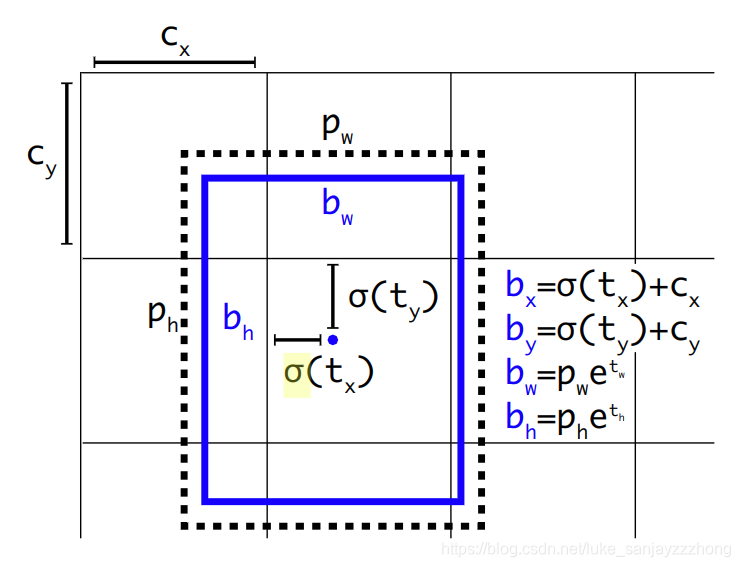
然而现在看来并没有什么影响力,大家主流用的还是Faster R-CNN中设计好的那一套encode/decode机制。
我是没怎么看懂…
6. Fine-Grained Features
这个就像ResNet的拼接,看下图:
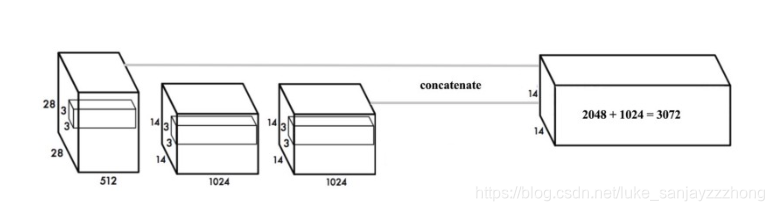
上图 最后的14x14x1024,要和前面的拼接。怎么拼接呢?本来第一个是28x28x512,把它resize成14x14x1024,然后在depth上拼接,就有了14x14x3072.
7. Multi-Scale Training
因为YOLOv2取消掉了全连接层,所以可以输入任意大小的图片。训练的时候每10个batch就换一个大小,从{320, 352,…,608},每次增加32。
Faster
YOLOV1中basemodel选择GoogleNet而非VGGNet,之后的SSD却采用了VGGNet,并大获成功。YOLOv2坐不住了,想要改basemodel
- 自己搞了个模型出来,名字叫Darknet-19。需要5.58billion次运算,相比与VGG-16的30.69billion很牛逼了。而且精度还很高。
下图是整体流程图:
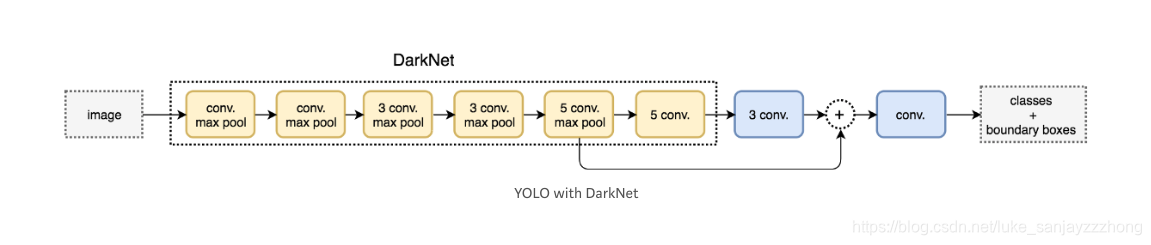
摘抄
Training
YOLO is trained with the ImageNet 1000 class classification dataset in 160 epochs: using stochastic gradient descent with a starting learning rate of 0.1, polynomial rate decay with a power of 4, weight decay of 0.0005 and momentum of 0.9. In the initial training, YOLO uses 224 × 224 images, and then retune it with 448× 448 images for 10 epochs at a 10−3 learning rate. After the training, the classifier achieves a top-1 accuracy of 76.5% and a top-5 accuracy of 93.3%.
Then the fully connected layers and the last convolution layer is removed for a detector. YOLO adds three 3 × 3 convolutional layers with 1024 filters each followed by a final 1 × 1 convolutional layer with 125 output channels. (5 box predictions each with 25 parameters) YOLO also add a passthrough layer. YOLO trains the network for 160 epochs with a starting learning rate of 10−3 , dividing it by 10 at 60 and 90 epochs. YOLO uses a weight decay of 0.0005 and momentum of 0.9.
也就是说,训练的时候先训练分类任务,训练完了然后再把全连接层去掉,用卷积层替换…