Abstract
- 通过某种联合训练的方式,使得YOLO9000可以对尚未进行标记过得类别数据上对该类别进行预测。
1. Introduction
- 提出一种新的方式对大量已有分类数据进行管理,并且将其利用来扩大现有检测系统的类别数目
- 提出一种新的训练算法,可以使得同时在检测和分类数据上同时进行训练,利用检测数据来精确定位目标,利用分类数据来增大vocabulary和鲁棒性
2. Better
- 由于YOLO存在定位较差和recall相对于region proposal-based的方法较低的缺点,作者主要着重于这两点对其进行改进
- 为了实现更好的表现形式,一般都是选择更大的网络或者ensemble方法,但是为了保持YOLO的速度,作者选择从其他方面对其进行改进,使其保持其原有的简单性
Batch Normalization
优点:在不适用其他正则化方法的同时,可以提升网络的收敛性能。
结果:提升了超过2%的mAP
High Resolution Classifier
优点:YOLO的训练是现在224 x 224的图片上训练出一个分类器作为pretrained network,然后再将其转化为detection model, 对448 x 448的图片进行检测。这意味着网络必须同时在学习目标检测和适应新的输入精度之间进行转换。基于这一点,作者将 分类网络首先在ImageNet上对精度为448 x 448的图片训练10个epoch。然后再检测上对上述得到的网络进行fine tune。
结果:提升了接近4%的mAP
Convolutional With Anchor Boxes
YOLO是直接预测bbox的坐标,而RPN则是预测特征图上的anchor的offsets。这种做法将问题进行了简化,使得网络更容易进行 学习。
作者的具体做法如下。为了得到更高像素的输出,移除了一个池化层;将网络的输入从448x448改变为416x416,这样做可以使 得特征图中cell的个数为单数,就会在特征图的中心处得到唯一的一个cell。如下图所示:

这么做的原因是,较大的目标通常比较倾向于出现在图片的中心。
Dimension Clusters
作者认为如果为anchor boxes的dimensions选择先验,而非人工设定,网络的表现会更好。作者的方法是,在训练集的bbox上进行k-means聚类。如果用传统的k-means算法,更大的anchor boxes得到的error一般都会大于较小的那些anchor boxes。因此作者选择了自己的距离标准:
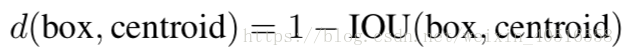
K-means的结果如下图所示:
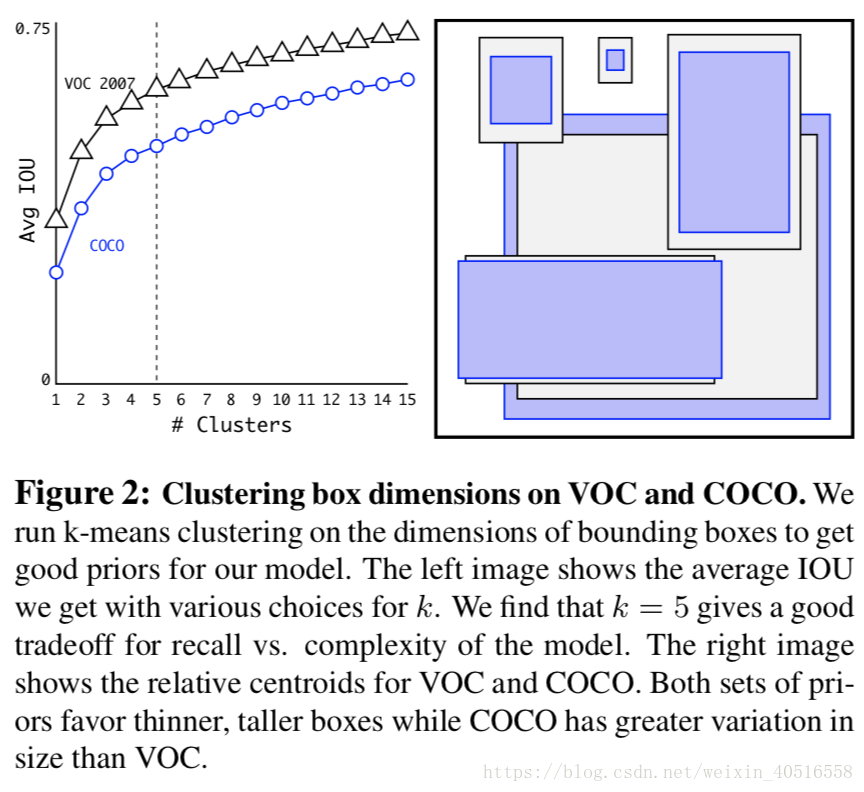
作者在基于模型复杂度和召回率之间选择了k=5作为最后的anchor boxes dimensions的类别墅。
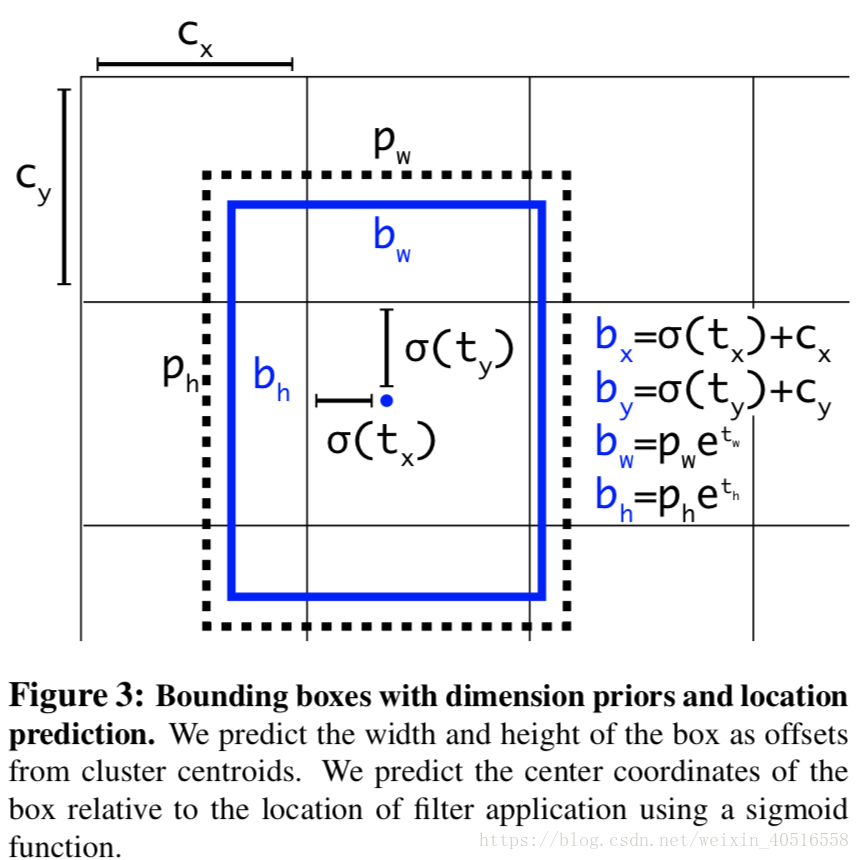
Direct Location Prediction
YOLO中还有一个问题就是模型的不稳定性,这个问题主要来自于对box位置的预测。在RPN中用offsets替代了直接预测坐标。由RPN中的公式可以得到,
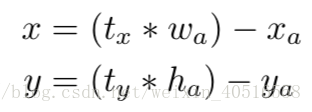
上面这个公式有点问题,-号应该改为+号。上面的公式意味着当tx为-1时,预测结果将把anchor的位置沿着x轴方向向负方向移动anchor的w那么远,当tx为+1时,预测结果将把anchor的位置沿着x轴方向向正方向移动anchor的w那么远。
这么做的结果是,最后的预测结果将会出现在图片的任意位置处。因此造成结果不稳定。
因此作者依旧按照YOLO中的方法,最终预测得到的位置是相对于grid cell的位置。网络对最后输出的特征图中的每一个cell预测5个bbox。每个bbox预测5个参数。具体公式如下:
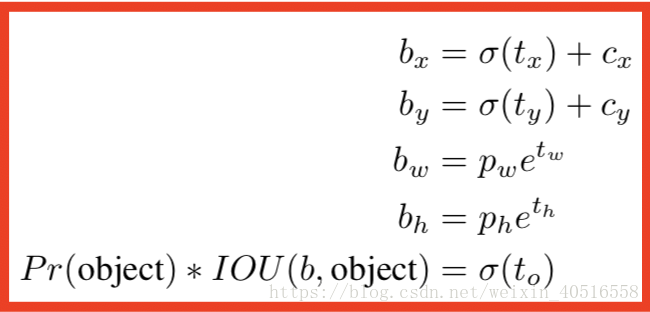
具体示意图如下:
3. Faster
4. Stronger
5. Conclusion
to be continued ...