YOLO9000是YOLO的第三个版本。前两个版本是YOLO v1,YOLO v2,在CVPR2017的文章《Better,Faster,Stronger》中的前半部分都是对前两个版本的介绍,新的内容主要在Stronger部分。YOLO9000中的9000指的是YOLO可以对超过9000种图像进行分类。
Better
使用Batch normalization有利于收敛和正则化,甚至可以从网络中移除dropout。Batch normalization实质是对数据归一化处理。使每批数据发布相同,最好是独立同分布,这样神经网络才能更好地学习。
High Resolution Classifier
大多数算法使用在ImageNet上预训练pre-trained的分类器。大多数使用AlexNet模型的分类器工作在分辨率小于256x256的图片上。初始版本的YOLO先在224x224大小的图像上训练分类器网络,然后再将分辨率提升到448x448,这意味着网络必须在检测的时候重新根据分辨率调整。在YOLOv2中,对分类网络就开始在10 epochs内使用448x448的图像对网络训练,这样滤波器就有时间调整参数。在检测阶段再在此基础上进行优化。
Convolutional with Anchor Boxes
YOLOv1是直接从全连接层中预测the coordinates of bounding boxes。而Faster R-CNN中的RPN只使用卷积层就预测了offsets 偏移and confidences置信度 for anchor boxes.再加上手动选择的先验hand-picked priors,就可以预测bounding boxes。所以作者就去掉了YOLO的全连接层,并使用anchor boxes来预测bounding boxes。去掉一层池化层,使得输出的分辨率更高。把448x448的分辨率再调整为416x416,这次分辨率降低了,为的是输出得到的特征图feature map的网格是奇数,确保目标物体只对应在单一的方格内。下采样比例是32时,输出特征图尺寸就是13x13.
对于anchor boxes,还进行了解耦decouple。
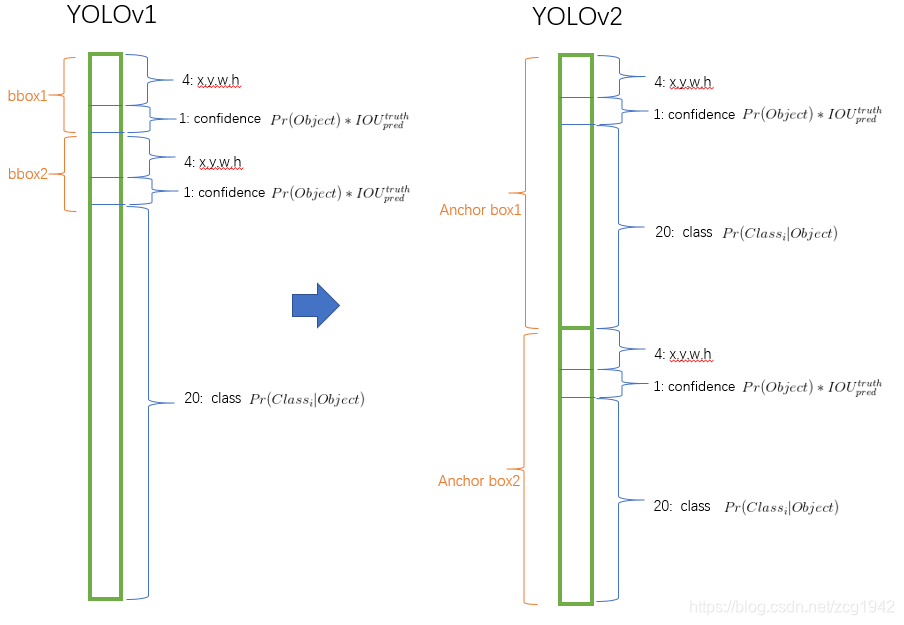
对于每一个位置预测两个box的情况,解耦后对每一个预测的box都包含了位置信息(5个参数:一个置信度,四个坐标信息),对一个box都给出了分类的条件概率(假设方框内有物体),而解耦前只给了该位置的条件概率,这就是解耦的出处,条件概率不与空间位置有关,而与box有关。
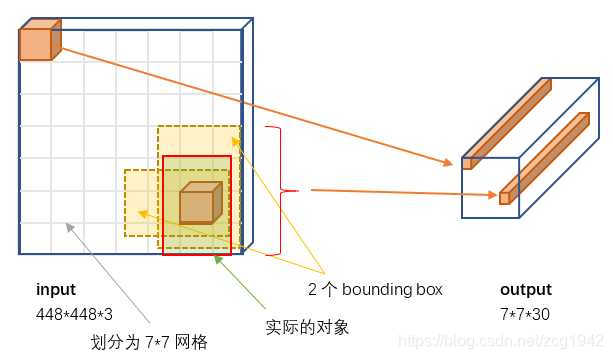
YOLOv1划分成7x7的网络,每一个网格预测两个box,所以每一幅图预测7x7x2=98个box,而使用anchor boxes之后可以预测1000多个box。
Dimension Clusters
K-means聚类方法自动选择先验的box的尺寸。K取值为5,平衡了复杂度和高recall,将欧式距离改为一个新的衡量标准,使得box的尺寸和IOU无关。
Direct location prediction
在YOLO中使用anchor boxes会在早期迭代中遇到不稳定的问题。任意box可能终止在图像的任意位置。所以不再预测offsets(又不预测偏移量了?),改而预测相对于grid cell的相对位置坐标。这就要求预测的ground truth限制在(0,1),可以通过logistic activation达到这个要求。
对于刚才的疑问,我的理解是这样的:对于box的长和宽是由相对于cluster centroids的offsets预测的,而对于box的中心坐标,是通过sigmoid函数预测相对于滤波器的坐标实现的。
Fine-Grained Features
简单添加一个 passthrough layer,把浅层特征图(分辨率为26*26)连接到深层特征图。
passthroughlaye把高低分辨率的特征图做连结,叠加相邻特征到不同通道(而非空间位置),类似于Resnet中的identity mappings。
Multi-ScaleTraining
为了让YOLOv2对不同尺寸图片的具有鲁棒性,每经过10批训练(10 batches)就会随机选择新的图片尺寸。网络使用的降采样参数为32,于是使用32的倍数{320,352,…,608},最小的尺寸为320*320,最大的尺寸为608*608。 调整网络到相应维度然后继续进行训练。
Faster
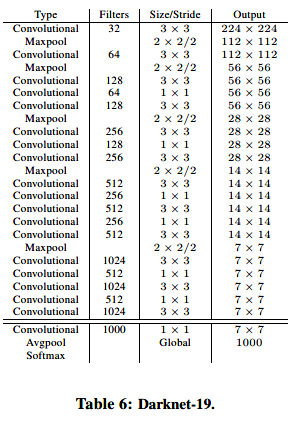
大多数检测框架使用的是VGG-16,但是计算量大,对于224x224大小的图像,传输一次需要30.69billion次浮点运算。YOLO使用了Googlenet,需要8.52billion次运算,速度更快但是准确度降低。作者提出了一种新的分类模型:Darknet-19. Darknet-19借鉴了VGG中的3x3滤波器和double池化层之后的通道数。借鉴了NIN中的全局平均池化global average pooling以坐预测,借鉴了NIN中的1x1滤波器压缩3x3卷积之间的特征表示。Darknet-19有19个卷积层和5个最大池化层maxpooling layers,模型的细节(每层的尺寸)可以可以从表6中看到。Darknet-19只进行5.58billion次运算。
有了模型,就要使用样本数据进行训练。对于分类,使用的数据集是ImageNet 1000,学习方法是随机梯度下降,训练时长是160epochs。训练过程中还使用了数据增强。正如前文提到的,初始训练在224x224的图像上,然后再在448x448的图像上作调整,调整时间为10epochs,并且学习率也做了调整。
对于训练检测,去掉原网络最后一个卷积层,增加了三个 3 *3 (1024 filters)的卷积层,并且在每一个卷积层后面跟一个1*1的卷积层,输出维度是检测所需数量。训练的数据集是VOC,预测5种boxes,每个box包含5个坐标值和20个类别,所以总共是5*(5+20)= 125个输出维度。在最终的3x3x512层到倒数第二second to last卷积层之间加了passthrough,使得模型有了细粒度特征。除了在VOC上训练,还在COCO上进行训练,具体的策略见论文。
Stronger
这个Stronger指的是YOLOv3可以检测更多的物体。将带box信息的检测数据集用来学习预测box和目标信息,利用只包含类别标签的分类数据集用来扩展分类的能力。区别在于反向传播的函数是全部包含还是只包含分类部分。
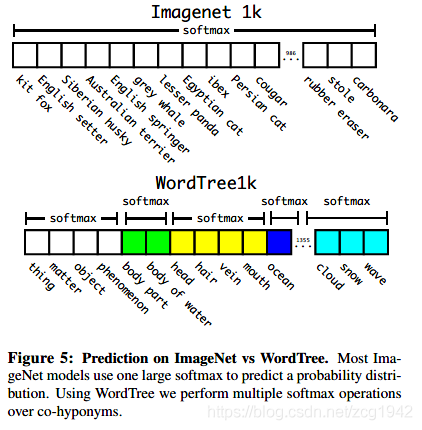
分类数据集如ImageNet的标签分类信息更详细,对dog就有不同的品种。所以为了将检测和分类数据集的类别信息融合起来,需要建立一个层次式的结构,基于图graph结构WordNet改动得到,这就是WordTree。WordTree是由WordNet而来的,先添加那些在wordNet中离根结点更近的点,这样使得WordTree增长得尽可能慢。这样,每一层之间是同义词,不同层之间的关系可以用条件概率表示。沿着的根结点的路径条件概率的相乘就可以得到绝对概率。
我们ImageNet中的1000个类别按照这种方法构建成WordTree,因为还有一些中间结点,所以最终的类别数是1369.训练时,会将当前标签及其直至根结点的所有标签都传播。这样会预测出一个1369长度的向量,在判决时,对同一组语义下的互斥关系的词条使用softmax,而不是对所有词语使用softmax。
这仅仅是验证说明这种联合数据集的方法是可行的,于是作者将ImageNet中的前9000个类别和COCO检测数据集联合起来,为了评估我们使用的方法,也从ImageNet detection challenge 中向整合数据集添加一些还没有存在于整合数据集的类别。相应的WordTree有9418个类别。由于ImageNet是一个非常大的数据集,所以通过oversampling COCO数据集来保持平衡,使ImageNet:COCO = 4:1。使用COCO来学习检测,使用ImageNet学习到更多的类别。
学习好之后在ImageNet detection task上评估。ImageNet detection task与COCO有44个类别是相同的,说明测试数据大部分只有分类数据,没有检测数据。
翻译参考:
https://blog.csdn.net/shadow_guo/article/details/54598458
https://blog.csdn.net/yudiemiaomiao/article/details/72636776
Demo
第一步是安装网络模型Darknet,为了支持更多的图片类型,可以安装OpenCV,为了使用GPU,可以安装CUDA。但是作者网站给出的是Mac上的Linux版本。这是同时支持windows的版本https://github.com/AlexeyAB/darknet 这个repository forked from pjreddie/darknet,新支持了Windows,提升了各种性能,针对GPU等做了许多优化。
解压后的路径build\darknet\x64\ 文件夹下面是一些cmd文件,用于初始化模型和展示一些检测后的样例。这些cmd文件的运行需要darknet.exe文件,所以第一步还是重新编译文件。
如果有GPU,要安装CUDA,CUDNN并注意路径问题就行了。我的电脑不支持CUDA,所以直接编译sln文件:build\darknet\darknet_no_gpu.sln, set x64 and Release, and do the: Build -> Build darknet_no_gpu。但是我的vs版本也不是官方要求的vs2015,报错:error MSB8020: The build tools for v140 (Platform Toolset = 'v140') cannot be found,这是因为原来的程序运行在vs2015上而现在我们需要运行在vs2013上,解决办法是把项目的属性中的平台工具集改为vs2013

即便这样,因为官方首先推荐的OpenCV版本是3.0版本,而自己使用的是OpenCV2.4.13,其实即便是OpenCV3.0,路径也不会和工程文件一样,所以依然要更改工程属性,添加附加包含目录,修改附加库目录。
4.1 (right click on project) -> properties -> C/C++ -> General -> Additional Include Directories: C:\opencv_2.4.13\opencv\build\include
4.2 (right click on project) -> properties -> Linker -> General -> Additional Library Directories: C:\opencv_2.4.13\opencv\build\x64\vc14\lib
注意,这里4.2中的vc14是和vs2015对应的。当我们vs是2013的时候这里选择vc12,实际上,OpenCV2.4.13默认只有vc12,要想支持其他编译器一般要使用cmake重新构建。
这时候会出现很多错误,需要一个个排查。错误信息淹没在大量的warning信息中,可以在视图view中直接查看错误列表error list。

这是我的错误,不知道到底哪里出错了。在整个solution中搜索这个函数,好像没有被使用到,直接注释掉就编译通过了。
但最好还是研究一下代码。前缀0B(Binary)或者0b表示 二进制;
双目运算符按位与,保留某些位,同时对某些位清零。A&000111100,对1对应的部分保留,0对应的部分会被清0.这里的代码中n与二进制的1111作按位与,不清楚目的是什么,而且会报错,将0b1111改为0xf即编译通过。
参考overflow的解答,这段代码的目的是将一个字节的比特倒序输出。大致思想是将8bit分成高低高部分,每部分4bit,借助looup表,将高低4bit倒序后再交换。
这样,编译通过。darknet\build\darknet\x64文件夹下出现了darknet_no_gpu.exe,这是因为我选择的是无GPU的版本,如果是标准版本应该是darknet.exe。这只是表明我们已经得到了这个模型,但是还没有开始训练。YOLOv3和v2其实模型没有改变,区别只是v3使用了联合数据集进行了训练。所以接下来如何训练才是v2和v3的区别。
有了exe文件,同时有了config file for YOLO in the cfg,我们可以直接使用作者训练好的网络权重:下载yolov3.weights
链接1(百度云):链接:https://pan.baidu.com/s/1OsuaURd2jjA9_fX50w651g 密码:chmq
连接2(官网):https://pjreddie.com/media/files/yolov3.weights
注:在Linux上,安装网络模型,安装训练好的参数,运行检测器,都可以分别通过一行命令实现。而在Windows中,需要借助exe文件和cmd命令。
使用命令行可以一次监测一张图像,也可以不断输入图像路径监测多张图像,还可以检测来自网页的视频webcam如YouTube,需要compile Darknet with CUDA and OpenCV。YOLo默认显示置信度高于0.25的目标,当然可以自己更改这个阈值。对于一些有限制的环境,YOLO提供了Tiny YOLOv3,需要重新下载weights,将下载的weights放到x64文件夹下。
打开cmd,切换到E:\vscode\darknet-master(1)\darknet-master\build\darknet\x64路径,
输入cmd命令:darknet_no_gpu.exe detector test data\coco.data yolov3.cfg yolov3.weights
输入测试图像路径:E:\vscode\darknet-master(1)\darknet-master\build\darknet\x64\data\horses.jpg

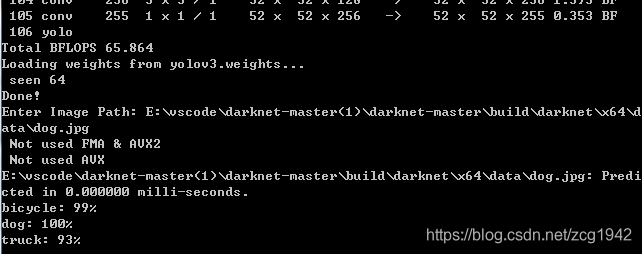

终于得到了这幅经典的分类检测结果图。但是这是使用了作者预先训练好的网络简单做了一个test。到自己训练,自己建立模型还有很长的路要走。
つづく
Reference:
https://blog.csdn.net/amusi1994/article/details/80261735?from=singlemessage