文章目录
参考
Introduction
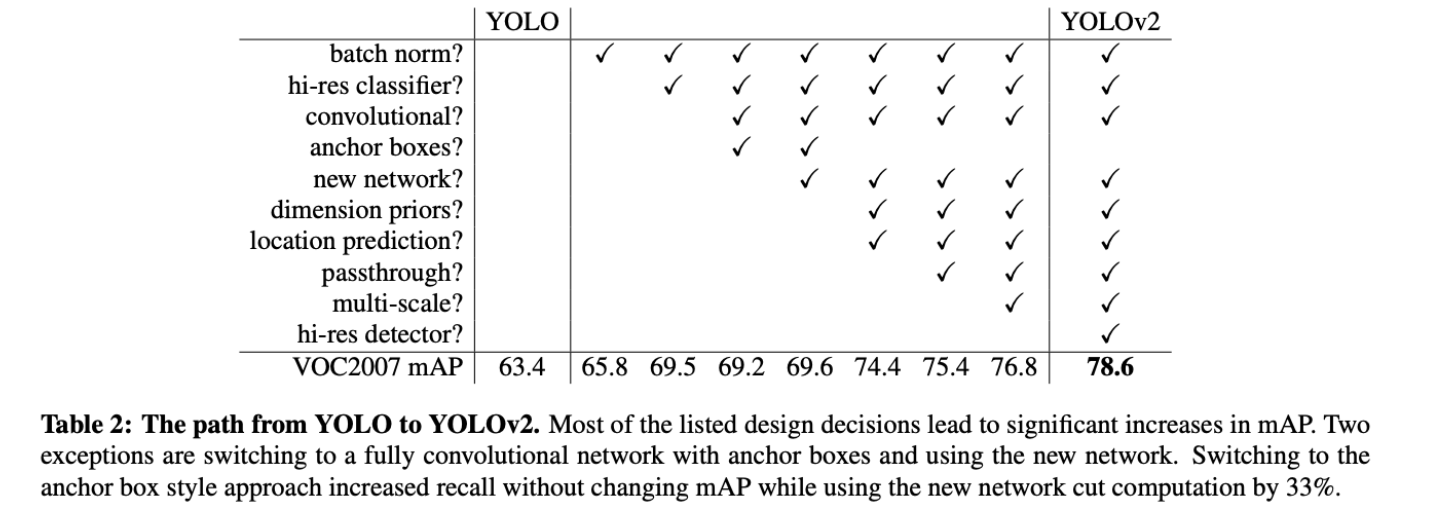
- YOLOv2基于YOLO做了一些列的修改,包括:BN;hi-res classifier;anchor boxes;Dimension Clusters;Direct location prediction;Fine-Grained features;Multi-Scale Training等trick,使得YOLOv2的点大幅提升
- 与此同时backbone采用的是darknet19
Faster
Batch Normalization
- 批量归一化可以显著提高收敛速度,同时消除对其他形式正则化的需求。在个人的认知中,BN还有个预防梯度爆炸的功能,在某次train faster rcnn的时候由于backbone用的是原始版的VGG16,没有BN,train到一半loss很容易变NAN。
- 在文中它帮助YOLOv2多mAP涨了2%
High Resolution Classifier
- 就是提高输入图片的大小,一开始是448,后来是416,416是经典的YOLO系列input的大小,他可以为classifier提供更多的特征信息(相对224和227),当然输入越大理论上mAP会越高,只不过416在当时是一个比较好的tradeoff
- 在文中它帮助YOLOv2多mAP涨了4%
Convolutional With Anchor Boxes
- 本文参考了RCNN系列加了anchor boxes,具体做法是在YOLO特征提取完毕之后的feature map的每个cell上(如:416x416的input其feature map为13x13)使用一次anchor boxes。
- 在YOLO时代,采用了anchor-free的方式(每个cell预测两个anchor,且cell是手工分出来的,因此在YOLO一文中只能预测7x7x2=98个obj),预测的obj比较少,而在YOLOv2中,由于anchor boxes的引入,同时更多的cell(13x13=169),就可以得到更多的候选框,于是顺理成章recall从81%->88%( r e c a l l = T P T P + F N recall = \frac{TP}{TP+FN} recall=TP+FNTP更多的候选框意味着TP更多,同时FN没有基本没变,recall自然会上升,剩下的就是把没用的候选框剔除)
- 但是引入anchor boxes有两个问题(其实应该算三个)
- anchor boxes的大小怎么设置(wh),个数怎么设定
- anchor boxes的引入可能导致模型在早期的训练中不稳定(loss主要来自于anchor的localization)
Dimension Clusters
-
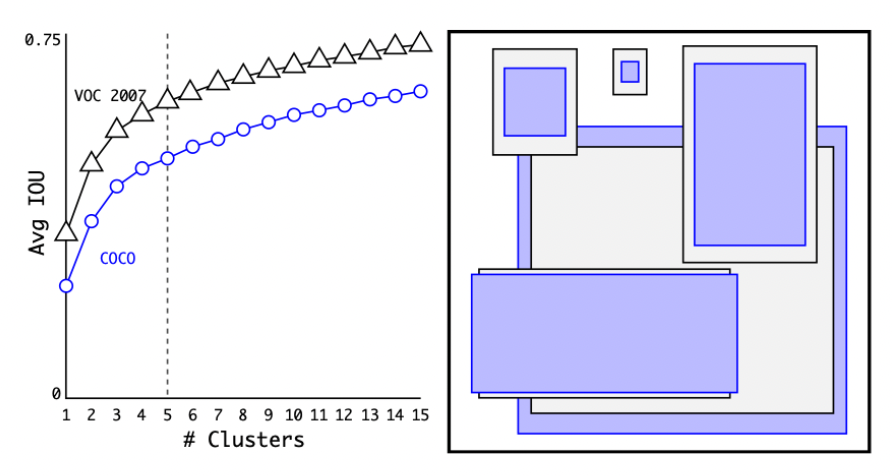
为了解决问题1(大小与个数),文章引入了kmeans算法来聚类(不了解的可以参考:【机器学习】K-means(非常详细)),对不同个数进行聚类并统计,得到如下图:
-
-
为了保持速度,最终选择5个框(a good tradeoff between model complexity and high recall)
-
(注:个人印象中kmeans会输出4个值,也就是xywh,如上右图所示,但对于YOLOv2只需要wh即可)
-
-
而且作者并没有标准的kmeans算法(欧几里得距离那版),而是用IOU当作距离,这样就可以使得先验框的IOU更高(更容易框到obj)
- d ( b o x , c e n t r o i d ) = 1 − I O U ( b o x , c e n t r o i d ) d(box, centroid) = 1 − IOU(box, centroid) d(box,centroid)=1−IOU(box,centroid)
Direct location prediction
-
为了解决问题2(不稳定),YOLOv2同时引入了RCNN里面计算边界框那段机制(只是公式变换了一下)
-
x = ( t x ∗ w a ) + x a x = (t_x∗ w_a) + x_a x=(tx∗wa)+xa
-
y = ( t y ∗ h a ) + y a y = (t_y∗ h_a) + y_a y=(ty∗ha)+ya
-
而在faster rcnn中长这样
-
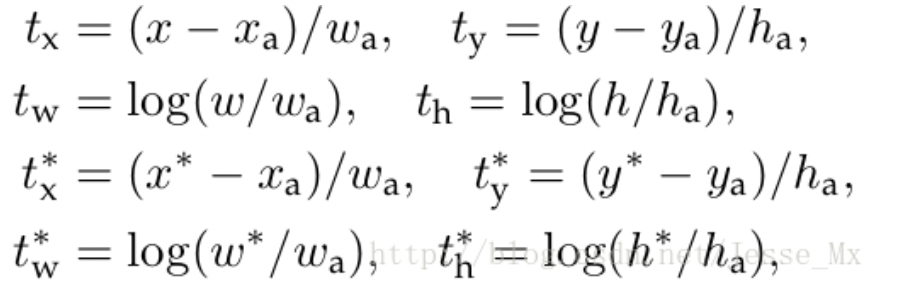
-
其中x 是坐标预测值, x a x_a xa 是anchor坐标(预设固定值), x ∗ x^∗ x∗ 是坐标真实值(标注信息),其他变量 y,w,h 以此类推,t 变量是偏移量。
-
对应上去就不难理解上面的两个式子(这个公式的理解为:当预测 t x = 1 t_x=1 tx=1,就会把box向右边移动一定距离(具体为anchor box的宽度),预测 t x = − 1 t_x=−1 tx=−1,就会把box向左边移动相同的距离。)
-
-
这个公式没有任何限制,使得无论在什么位置进行预测,任何anchor boxes可以在图像中任意一点结束(我的理解是, t x t_x tx
没有数值限定,可能会出现anchor检测很远的目标box的情况,效率比较低。正确做法应该是每一个anchor只负责检测周围正负一个单位以内的目标box)。模型随机初始化后,需要花很长一段时间才能稳定预测敏感的物体位置。 -
在此,作者就没有采用预测直接的offset的方法,而使用了预测相对于grid cell的坐标位置的办法,同时用sigmoid函数将值限制在[0,1]
-
feature map(13 *13 )的每个cell上预测5个bounding boxes(聚类得出的值),同时每一个bounding box预测5个坐值,分别为 t x , t y , t w , t h , t o t_x,t_y,t_w,t_h,t_o tx,ty,tw,th,to,其中前四个是坐标, t o t_o to是置信度。如果这个cell距离图像左上角的边距为 ( c x , c y ) (c_x,c_y) (cx,cy)以及该cell对应box(bounding box prior)的长和宽分别为 ( p w , p h ) (p_w,p_h) (pw,ph),那么预测值可以表示为:
-
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w e t w b h = p h e t h P r ( o b j e c t ) ∗ I O U ( b , o b j e c t ) = σ ( t o ) \begin{array}{cc} b_x = \sigma(t_x) + c_x \\ b_y = \sigma(t_y) + c_y \\ b_w = p_we^{t_w} \\ b_h = p_he^{t_h} \\ Pr(object)*IOU(b,object) = \sigma(t_o) \end{array} bx=σ(tx)+cxby=σ(ty)+cybw=pwetwbh=phethPr(object)∗IOU(b,object)=σ(to)
-
-
下面这张图比较直观地解释了上面公式
-

Fine-Grained Features
- 这个就是参考了ResNet的残差结构,作者认为能够学习到细粒度的特征(有待考证),但是确实让mAP涨了一个点
Faster
Darknet-19
-
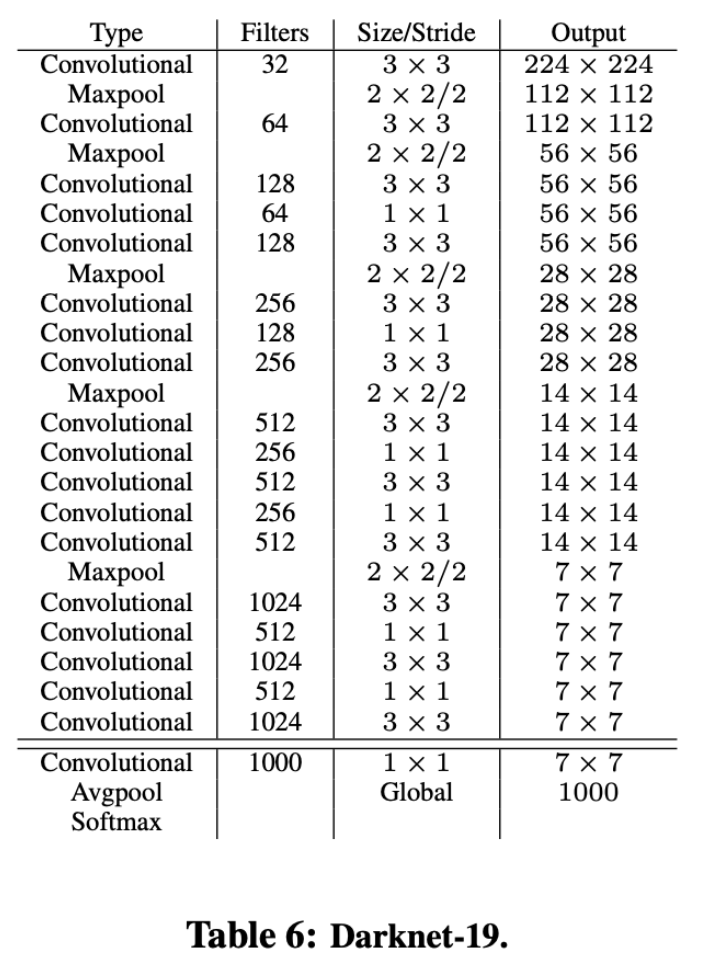
-
.Darknet-19仅需55.8亿次操作即可处理图像,但在ImageNet上可实现72.9%的top-1精度和91.2%的top-5精度
- (个人看法)加入了大量的1x1卷积来减少计算量,同时使用残差防止模型退化,因此可以达到较好的性能同时速度较快
Stronger
YOLO9000
-
YOLO9000是在YOLOv2的基础上提出的一种可以检测超过9000个类别的模型,其主要贡献点在于提出了一种分类和检测的联合训练策略。众多周知,检测数据集的标注要比分类数据集打标签繁琐的多,所以ImageNet分类数据集比VOC等检测数据集高出几个数量级。在YOLO中,边界框的预测其实并不依赖于物体的标签,所以YOLO可以实现在分类和检测数据集上的联合训练。对于检测数据集,可以用来学习预测物体的边界框、置信度以及为物体分类,而对于分类数据集可以仅用来学习分类,但是其可以大大扩充模型所能检测的物体种类。
-
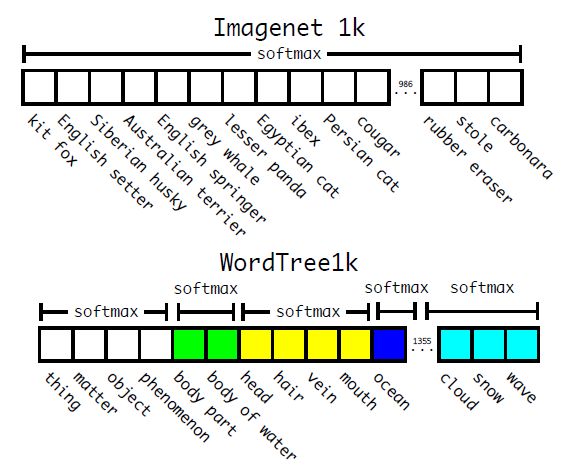
作者选择在COCO和ImageNet数据集上进行联合训练,但是遇到的第一问题是两者的类别并不是完全互斥的,比如"Norfolk terrier"明显属于"dog",所以作者提出了一种层级分类方法(Hierarchical classification),主要思路是根据各个类别之间的从属关系(根据WordNet)建立一种树结构WordTree,结合COCO和ImageNet建立的WordTree如下图所示:
-
-
WordTree中的根节点为"physical object",每个节点的子节点都属于同一子类,可以对它们进行softmax处理。在给出某个类别的预测概率时,需要找到其所在的位置,遍历这个path,然后计算path上各个节点的概率之积。
-
-
在训练时,如果是检测样本,按照YOLOv2的loss计算误差,而对于分类样本,只计算分类误差。在预测时,YOLOv2给出的置信度就是 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传 P r ( p h y s i c a l o b j e c t ) Pr(physical object) Pr(physicalobject),同时会给出边界框位置以及一个树状概率图。在这个概率图中找到概率最高的路径,当达到某一个阈值时停止,就用当前节点表示预测的类别。
-
通过联合训练策略,YOLO9000可以快速检测出超过9000个类别的物体,总体mAP值为19.7%。我觉得这是作者在这篇论文作出的最大的贡献,因为YOLOv2的改进策略亮点并不是很突出,但是YOLO9000算是开创之举。