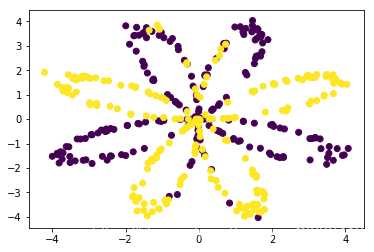
如图,要实现这种非线性的分类,逻辑回归已经不能很好的解决问题了,那么,我们试着用带有一个隐含层的神经网络来解决一下试试呢?
可能代码写的不够规范,把一些assert的部分去掉了,而且有一些测试没有做,但是,不影响输出,哈哈哈。
Let us go.
目录
1 加载、查看数据集
2 先用逻辑回归查看分类效果(基于sklearn)
3 定义神经网络结构 (每一层节点的个数)
4 初始化模型的参数 (高斯随机)
5 前向传播 (求A2)
6 代价函数 (A2与Y之间的误差)
7 反向传播 (计算每一层的梯度)
8 更新参数
9 整合模型
10 预测
11 更改隐藏层节点个数
import numpy as np
import matplotlib.pyplot as plt
import sklearn.linear_model
from planar_utils import sigmoid, load_planar_dataset
np.random.seed(1) #设置一个固定的随机种子,以保证接下来的步骤中我们的结果是一致的。
1 加载、查看数据集
X, Y = load_planar_dataset()
X.shape
(2, 400)
Y.shape
(1, 400)
plt.scatter(X[0,:],X[1,:],c=np.squeeze(Y))
plt.show()
见上图
2 先用逻辑回归查看分类效果
clf = sklearn.linear_model.LogisticRegressionCV()
clf.fit(X.T,Y.T)
D:\Anaconda\lib\site-packages\sklearn\utils\validation.py:578: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
LogisticRegressionCV(Cs=10, class_weight=None, cv=None, dual=False,
fit_intercept=True, intercept_scaling=1.0, max_iter=100,
multi_class='ovr', n_jobs=1, penalty='l2', random_state=None,
refit=True, scoring=None, solver='lbfgs', tol=0.0001, verbose=0)
Y_pred = clf.predict(X.T)
clf.score(X.T,Y.T) # 准确率
0.47
clf.coef_
array([[ 0.02626552, -0.19186924]])
3 定义神经网络结构
def layer_size(X,Y):
n_x = X.shape[0] # 输入层的特征数 2个
n_h = 4 #隐藏层的神经元个数
n_y = Y.shape[0] #输出层 1个
return (n_x,n_h,n_y)
n_x,n_h,n_y = layer_size(X,Y)
print(n_x,n_h,n_y)
2 4 1
4 初始化模型的参数
def initialize_parameters(n_x,n_h,n_y):
W1 = np.random.randn(n_h,n_x) * 0.01 # 防止随机初始化的参数太大
b1 = np.zeros((n_h, 1))
W2 = np.random.randn(n_y,n_h) * 0.01
b2 = np.zeros((n_y, 1))
parameters = {"W1" : W1,
"b1" : b1,
"W2" : W2,
"b2" : b2 }
return parameters
parameters = initialize_parameters(n_x,n_h,n_y)
parameters
{'W1': array([[ 0.00814343, 0.0078047 ],
[-0.01464054, -0.00154491],
[-0.00092432, -0.00237875],
[-0.00755663, 0.01851438]]), 'b1': array([[0.],
[0.],
[0.],
[0.]]), 'W2': array([[ 0.00209097, 0.01555016, -0.00569149, -0.01061797]]), 'b2': array([[0.]])}
5 前向传播
def forward_propagation(X,parameters):
W1 = parameters['W1']
b1 = parameters['b1']
W2 = parameters['W2']
b2 = parameters['b2']
Z1 = W1 @ X + b1
A1 = np.tanh(Z1)
Z2 = W2 @ A1 + b2
A2 = sigmoid(Z2)
cache = {"Z1": Z1,
"A1": A1,
"Z2": Z2,
"A2": A2}
return A2,cache
A2,cache = forward_propagation(X,parameters)
6 代价函数
def compute_cost(A2, Y):
m = Y.shape[1]
inner = Y * np.log(A2) + (1-Y) * np.log(1-A2)
cost = - np.sum(inner) / m
cost = float(np.squeeze(cost))
return cost
cost_init = compute_cost(A2, Y)
cost_init
0.6931125167719423
7 反向传播/计算每一层的梯度
def backward_propagation(parameters,cache,X,Y):
W1 = parameters['W1']
W2 = parameters['W2']
A1 = cache['A1']
A2 = cache['A2']
m = X.shape[1]
# 计算梯度
dZ2= A2 - Y
dW2 = (1 / m) * np.dot(dZ2, A1.T)
db2 = (1 / m) * np.sum(dZ2, axis=1, keepdims=True)
dZ1 = np.multiply(np.dot(W2.T, dZ2), 1 - np.power(A1, 2))
dW1 = (1 / m) * np.dot(dZ1, X.T)
db1 = (1 / m) * np.sum(dZ1, axis=1, keepdims=True)
grads = {"dW1": dW1,
"db1": db1,
"dW2": dW2,
"db2": db2 }
return grads
grads = backward_propagation(parameters,cache,X,Y)
grads
{'dW1': array([[-4.70690212e-05, 4.11157204e-04],
[-3.50786575e-04, 3.06388144e-03],
[ 1.29089685e-04, -1.11987590e-03],
[ 2.44225288e-04, -2.07647922e-03]]), 'db1': array([[-1.19216713e-08],
[ 1.39568414e-07],
[ 1.09077696e-08],
[-5.48251244e-07]]), 'dW2': array([[ 1.35117990e-03, 2.73782249e-05, -4.47115222e-04,
3.80800948e-03]]), 'db2': array([[-1.91436626e-06]])}
8 更新参数
def update_parameters(parameters,grads,learning_rate=1.2):
W1 = parameters['W1']
b1 = parameters['b1']
W2 = parameters['W2']
b2 = parameters['b2']
dW1,dW2 = grads["dW1"],grads["dW2"]
db1,db2 = grads["db1"],grads["db2"]
W1 = W1 - learning_rate * dW1
b1 = b1 - learning_rate * db1
W2 = W2 - learning_rate * dW2
b2 = b2 - learning_rate * db2
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters
parameters_1 = update_parameters(parameters,grads,learning_rate=1.2)
parameters_1
{'W1': array([[ 0.00819991, 0.00731131],
[-0.01421959, -0.00522157],
[-0.00107923, -0.0010349 ],
[-0.0078497 , 0.02100615]]), 'b1': array([[ 1.43060055e-08],
[-1.67482097e-07],
[-1.30893236e-08],
[ 6.57901493e-07]]), 'W2': array([[ 0.00046955, 0.01551731, -0.00515495, -0.01518758]]), 'b2': array([[2.29723952e-06]])}
9 整合模型
def nn_model(X,Y,n_h,num_iterations,print_cost=False):
# 1设置模型结构
np.random.seed(3) #指定随机种子
n_x = layer_size(X, Y)[0]
n_y = layer_size(X, Y)[2]
# 2随机初始化
parameters = initialize_parameters(n_x,n_h,n_y)
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
for i in range(num_iterations):
# 3 前向传播/求A2
A2 , cache = forward_propagation(X,parameters)
# 4 代价函数/计算A2 与真实值Y 的误差关系
cost = compute_cost(A2,Y)
# 5 反向传播求梯度
grads = backward_propagation(parameters,cache,X,Y)
# 6 更新参数
parameters = update_parameters(parameters,grads,learning_rate=1.2)
if print_cost:
if i%1000 == 0:
print("第 ",i," 次循环,成本为:"+str(cost))
return parameters
parameters_iter = nn_model(X,Y,n_h=4,num_iterations=10000,print_cost=True)
parameters_iter
第 0 次循环,成本为:0.6931621661402946
第 1000 次循环,成本为:0.2586250682869047
第 2000 次循环,成本为:0.23933351654583146
第 3000 次循环,成本为:0.23080163442975746
第 4000 次循环,成本为:0.2255280270817635
第 5000 次循环,成本为:0.22184467595022694
第 6000 次循环,成本为:0.2190943835487874
第 7000 次循环,成本为:0.22088369605864752
第 8000 次循环,成本为:0.21948287975621533
第 9000 次循环,成本为:0.21854783585583581
{'W1': array([[ 11.45753676, -3.41713075],
[ 0.1580534 , -9.70576973],
[ 11.49968112, 13.45174838],
[ 9.25498481, -10.19974607]]), 'b1': array([[ 0.39374262],
[-0.09959337],
[ 0.03547642],
[ 0.09107878]]), 'W2': array([[ -3.45826866, -11.99167371, -6.12698488, 10.56949614]]), 'b2': array([[-0.05423241]])}
10 预测
def predict(parameters,X):
A2,cache= forward_propagation(X,parameters)
predictions = np.round(A2) # 四舍五入,代替了条件判断0.5的阈值
return predictions
Y_pred = predict(parameters_iter,X)
Y_pred
array([[0., 1., 1., 1., 0., 1., 0., 1., 0., 0., 0., 1., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0.,
0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 1.,
1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0.,
1., 1., 1., 0., 1., 1., 1., 1., 0., 1., 1., 1., 0., 1., 0., 0.,
1., 1., 1., 1., 1., 1., 0., 0., 1., 1., 1., 0., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 0., 1., 1., 1., 1., 1., 1., 1., 1., 0., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 0., 1., 1., 1., 1., 1., 1., 0., 1., 0., 0., 0., 1., 0.]])
acc = np.mean(Y_pred == Y)
acc
0.905
11 更改隐藏层节点个数
hidden_layer_sizes = [1, 2, 3, 4, 5, 20, 50] #隐藏层数量
for n_h in hidden_layer_sizes:
parameters_final = nn_model(X, Y, n_h, num_iterations=5000)
Y_pred = predict(parameters_final, X)
acc = np.mean(Y == Y_pred) * 100
print ("隐藏层的节点数量: {} ,准确率: {} %".format(n_h, acc))
隐藏层的节点数量: 1 ,准确率: 67.5 %
隐藏层的节点数量: 2 ,准确率: 67.25 %
隐藏层的节点数量: 3 ,准确率: 90.75 %
隐藏层的节点数量: 4 ,准确率: 90.5 %
隐藏层的节点数量: 5 ,准确率: 91.25 %
隐藏层的节点数量: 20 ,准确率: 91.0 %
隐藏层的节点数量: 50 ,准确率: 90.5 %