版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Apple_hzc/article/details/83027944
一、deeplearning-assignment
在本次作业的开始,针对一个非线性可分的数据集通过sklearn的内置函数来训练数据集上的逻辑回归分类器,可以看到逻辑回归的表现并不理想,准确度只有47%。

因此建立一个神经网络模型,该模型有一个隐藏层,每个隐藏层有四个节点。
神经网络的正向传播:

神经网络的反向传播:

反向传播是深度学习中最难的(最具数学意义的)部分。为了帮助你,拿出了讲座中的幻灯片。您将要使用这张幻灯片右边的六个公式,因为您正在构建一个矢量化的实现。
其中,
为了计算dZ1,你需要计算 ,由于
是激活函数tanh,因此如果
那么
.。你就可以通过numpy的函数(1 - np.power(A1, 2))来计算
的值。
二、相关算法代码
import numpy as np
import matplotlib.pyplot as plt
import sklearn
import sklearn.datasets
import sklearn.linear_model
from week3.testCases import *
from week3.planar_utils import plot_decision_boundary, sigmoid, load_planar_dataset, load_extra_datasets
np.random.seed(1)
X, Y = load_planar_dataset() # 加载数据集
# plt.scatter(X[0, :], X[1, :], c=np.squeeze(Y), s=40, cmap=plt.cm.Spectral)
# plt.show()
# 通过sklearn内置函数对数据集进行逻辑回归
# logistic = sklearn.linear_model.LogisticRegressionCV()
# logistic.fit(X.T, Y.T.ravel())
# plot_decision_boundary(lambda x: logistic.predict(x), X, Y)
# plt.title("Logistic Regression")
# plt.show()
#
# LR_predictions = logistic.predict(X.T)
# print('Accuracy of logistic regression: %d ' % float((np.dot(Y, LR_predictions) +
# np.dot(1-Y, 1-LR_predictions)) / float(Y.size) * 100) +
# '% ' + "(percentage of correctly labelled datapoints)")
# shape_X = X.shape
# shape_Y = Y.shape
# m = shape_X[1]
# print('The shape of X is: ' + str(shape_X))
# print('The shape of Y is: ' + str(shape_Y))
# print('I have m = %d training examples!' % (m))
def layer_sizes(X, Y): # 初始化各个维度的值
n_x = X.shape[0]
n_h = 4
n_y = Y.shape[0]
return n_x, n_h, n_y
# X_assess, Y_assess = layer_sizes_test_case()
# (n_x, n_h, n_y) = layer_sizes(X_assess, Y_assess)
# print("The size of the input layer is: n_x = " + str(n_x))
# print("The size of the hidden layer is: n_h = " + str(n_h))
# print("The size of the output layer is: n_y = " + str(n_y))
def initialize_parameters(n_x, n_h, n_y): # 对W1, W2, b1, b2进行初始化
"""
Returns:
params -- python dictionary containing your parameters:
W1 -- weight matrix of shape (n_h, n_x)
b1 -- bias vector of shape (n_h, 1)
W2 -- weight matrix of shape (n_y, n_h)
b2 -- bias vector of shape (n_y, 1)
"""
np.random.seed(2)
W1 = np.random.rand(n_h, n_x) * 0.01
b1 = np.zeros((n_h, 1))
W2 = np.random.rand(n_y, n_h) * 0.01
b2 = np.zeros((n_y, 1))
# 深度学习常见的bug就是维度异常
# 吴恩达的经验:编码中嵌入assert代码,检测维度
assert (W1.shape == (n_h, n_x))
assert (b1.shape == (n_h, 1))
assert (W2.shape == (n_y, n_h))
assert (b2.shape == (n_y, 1))
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters
# n_x, n_h, n_y = initialize_parameters_test_case()
# parameters = initialize_parameters(n_x, n_h, n_y)
# print("W1 = " + str(parameters["W1"]))
# print("b1 = " + str(parameters["b1"]))
# print("W2 = " + str(parameters["W2"]))
# print("b2 = " + str(parameters["b2"]))
def forward_propagation(X, parameters): # 正向传播
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
Z1 = np.dot(W1, X) + b1
A1 = np.tanh(Z1)
Z2 = np.dot(W2, A1) + b2
A2 = sigmoid(Z2)
assert (A2.shape == (1, X.shape[1]))
cache = {"Z1": Z1,
"A1": A1,
"Z2": Z2,
"A2": A2}
return A2, cache
# X_assess, parameters = forward_propagation_test_case()
# print(X_assess)
# print(parameters)
# A2, cache = forward_propagation(X_assess, parameters)
# print(cache)
# print("mean:", np.mean(cache['Z1']), np.mean(cache['A1']), np.mean(cache['Z2']), np.mean(cache['A2']))
def compute_cost(A2, Y, parameters): # 计算cost
m = Y.shape[1] # number of example
logprobs = np.multiply(Y, np.log(A2)) + np.multiply(1 - Y, np.log(1 - A2))
cost = - 1 / m * np.sum(logprobs)
cost = np.squeeze(cost) # sqeeze从数组的形状中删除单维条目,即把shape中为1的维度去掉
# E.g., turns [[17]] into 17
assert (isinstance(cost, float))
return cost
# A2, Y_assess, parameters = compute_cost_test_case()
# print("cost = " + str(compute_cost(A2, Y_assess, parameters)))
def backward_propagation(parameters, cache, X, Y): # 反向传播
m = X.shape[1]
W1 = parameters["W1"]
W2 = parameters["W2"]
A1 = cache["A1"]
A2 = cache["A2"]
dZ2 = A2 - Y
dW2 = 1 / m * np.dot(dZ2, A1.T)
db2 = 1 / m * np.sum(dZ2, axis=1, keepdims=True)
dZ1 = np.dot(W2.T, dZ2) * (1 - np.power(A1, 2))
dW1 = 1 / m * np.dot(dZ1, X.T)
db1 = 1 / m * np.sum(dZ1, axis=1, keepdims=True)
grads = {"dW1": dW1,
"db1": db1,
"dW2": dW2,
"db2": db2}
return grads
# parameters, cache, X_assess, Y_assess = backward_propagation_test_case()
# grads = backward_propagation(parameters, cache, X_assess, Y_assess)
# print("dW1 = " + str(grads["dW1"]))
# print("db1 = " + str(grads["db1"]))
# print("dW2 = " + str(grads["dW2"]))
# print("db2 = " + str(grads["db2"]))
def update_parameters(parameters, grads, learning_rate=1.2): # 更新W1, W2, b1, b2
W1 = parameters['W1']
b1 = parameters['b1']
W2 = parameters['W2']
b2 = parameters['b2']
dW1 = grads["dW1"]
db1 = grads["db1"]
dW2 = grads["dW2"]
db2 = grads["db2"]
W1 -= dW1 * learning_rate
b1 -= db1 * learning_rate
W2 -= dW2 * learning_rate
b2 -= db2 * learning_rate
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters
# parameters, grads = update_parameters_test_case()
# parameters = update_parameters(parameters, grads)
# print("W1 = " + str(parameters["W1"]))
# print("b1 = " + str(parameters["b1"]))
# print("W2 = " + str(parameters["W2"]))
# print("b2 = " + str(parameters["b2"]))
# The neural network model has to use the previous functions in the right order.
def nn_model(X, Y, n_h, num_iterations=10000, print_cost=False):
np.random.seed(3)
n_x = layer_sizes(X, Y)[0]
n_y = layer_sizes(X, Y)[2]
n_x, n_h, n_y = layer_sizes(X, Y)
parameters = initialize_parameters(n_x, n_h, n_y)
W1 = parameters['W1']
b1 = parameters['b1']
W2 = parameters['W2']
b2 = parameters['b2']
for i in range(0, num_iterations):
A2, cache = forward_propagation(X, parameters)
cost = compute_cost(A2, Y, parameters)
grads = backward_propagation(parameters, cache, X, Y)
parameters = update_parameters(parameters, grads)
if print_cost and i % 1000 == 0:
print("Cost after iteration %i: %f" % (i, cost))
return parameters
# X_assess, Y_assess = nn_model_test_case()
# parameters = nn_model(X_assess, Y_assess, 4, num_iterations=10, print_cost=False)
# print("W1 = " + str(parameters["W1"]))
# print("b1 = " + str(parameters["b1"]))
# print("W2 = " + str(parameters["W2"]))
# print("b2 = " + str(parameters["b2"]))
def predict(parameters, X):
A2, cache = forward_propagation(X, parameters)
predictions = np.array([1 if x > 0.5 else 0 for x in A2.reshape(-1, 1)]).reshape(A2.shape)
return predictions
# parameters, X_assess = predict_test_case()
# predictions = predict(parameters, X_assess)
# print("predictions:", predictions)
# print("predictions mean = " + str(np.mean(predictions)))
# Build a model with a n_h-dimensional hidden layer
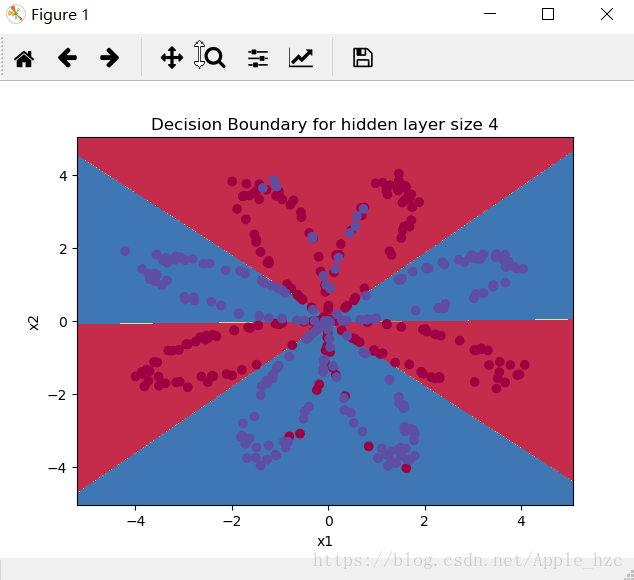
parameters = nn_model(X, Y, n_h=4, num_iterations=10000, print_cost=True)
# Plot the decision boundary
plot_decision_boundary(lambda x: predict(parameters, x.T), X, Y)
plt.title("Decision Boundary for hidden layer size " + str(4))
plt.show()
# Print accuracy
predictions = predict(parameters, X)
print('Accuracy: %d' % float((np.dot(Y, predictions.T) +
np.dot(1-Y, 1-predictions.T))/float(Y.size)*100) + '%')
通过神经网络的分类结果,准确率为90%:

三、总结
通过这次作业可以看到,对于非线性可分的数据集,前面学的逻辑回归并不能进行很好的学习,而通过神经网络,在隐藏层引入tanh这种非线性激活函数,能够很好地对数据集进行训练和拟合,期待接下来的学习!