论文阅读其实就是用自己的话讲一遍,然后理解其中的方法
0、论文基本信息
为什么阅读此篇论文:因为它是DMP经典论文,被引多次,学史可以明智,了解最初机理。
论文题目:Learning and Generalization of Motor Skills by Learning from Demonstration
会议名称:2009 ICRA
论文作者:Peter Pastor, Heiko Hoffmann, Tamin Asfour and Stefan Schaal
作者简介:Stefan Schaal是美国University of Southern California教授,之前也介绍过,是DMP的提出者,非常厉害的老师,在Youtube上看过他的报告,学术气质一流,主要做运能技能的学习,如模仿学习和强化学习。知乎上的大佬也表示,经过Stefan Schaal教授点拨的学生或合作的同事都走向了人生巅峰,如Auke Jan Ijspeert,Aude Billard,Sethu Vijayakumar,Jan Peters(Jens Kober是Jan Peters的学生),欧洲很多有影响力的机器人+机器学习实验室都和Stefan Schaal有着千丝万缕的联系。
题目:从示教中学习和泛化运动技能
摘要:作者提供了一种从人类演示中学习机器人运动技能的通用方法。为了表示观察到的运动,学习了一个非线性微分方程,使其可以再现这一运动。基于这种表示,作者根据任务和上下文(例如,抓握、放置和释放)标记每个记录的动作来构建动作库。作者提出的微分方程可以通过将方程中的起始和目标参数调整为运动所需位置值来简单地实现泛化。对于对象操作,作者介绍了提出的框架如何扩展到控制抓手方向和手指位置。改方法的可行性在仿真中以及在Sarcos灵巧的机械臂上得到了验证。该机器人学习了pick and place操作和倒水任务,并可以将这些任务推广到新的情况。
一、引言
这里只提炼核心内容:机器人只有易于编程,才能广泛服务于人类。易于编程可以通过示教学习实现。示教学习的三个问题需要解决,1,对应问题,即人类和机器人的关节和连杆不匹配。2,泛化,即人类无法演示机器人支持的每一个动作,所以需要进行泛化。如果演示的动作可以推广到其他环境中,比如不同的目标位置,那么通过演示进行学习是可行的。3,抵抗扰动的鲁棒性,即,在未知的动态环境中,精确复现观察到的动作是不切实际的,因此在这个环境中可能会突然出现障碍物。
为了解决这些问题,作者提出了一个基于DMP框架的模型,在这个框架下,任何记录的运动,都可以表示为一系列微分方程。用微分方程表示运动的优点是1,可以自动矫正扰动的影响(通过耦耦合项),2,仅改变目标点参数,其他不变,就可到达一个新的位置,具有泛化能力。本文提出了新的DMP公式,以解决传统DMP在更改目标位置参数时遇到的几个问题。
作者在末端执行器空间表示运动轨迹以解决问题1的对应问题,对于抓取和放置等目标操作,除了末端位置,我们还需要控制抓手的姿态和手指的位置(张开和闭合程度),DMP框架允许结合末端运动和任何附加的自由度,因此,可以直接添加四元数表示的抓手姿态和手指位置。在机器人演示中,作者使用解析的运动速率逆运动学将末端执行器位置和抓手姿态映射到适当的关节角度。
为了处理复杂的运动,可以使用上述DMP框架来构建运动基元库,随后可以通过排序来组成更加复杂的运动。例如,运动基元库可能包含抓取、放置和释放动作。这些动作中的每一个都是从人类演示中记录下来的,随后由一个微分方程表示,并相应地标记。对于在桌子上移动对象,需要一个抓取-放置-释放序列,并从库中调用相应的基元。由于每个动态运动基元的泛化能力,可以仅基于所演示的三个运动,将物体放置在桌子上任意位置。
二、动态运动基元及其改进
A. 传统DMP
一维运动表示为受外力项扰动的线性弹簧系统:
公式1和公式2
τ v ˙ = K ( g − x ) − D v + ( g − x 0 ) f ( s ) τ x ˙ = v \begin{aligned} \tau \dot{v} &=K(g-x)-D v+\left(g-x_{0}\right)f(s) \\ \tau \dot{x} &=v \end{aligned} τv˙τx˙=K(g−x)−Dv+(g−x0)f(s)=v
这里的DMP公式和平常看到的可能不一样,这里只是强调了弹簧特性,并不影响。 x x x和 v v v分别是系统的位置和经过时间因子 τ \tau τ缩放后的速度, x 0 x_{0} x0和 g g g分别为运动的起点和终点。 K K K是弹性常数 D D D是阻尼常数,选择合适的 K K K和 D D D以保证系统达到临界阻尼状态。 f f f是非线性函数,可以通过LWR(Locally Weighted Regression,局部加权回归)学习其参数,以生成任意复杂的运动。非线性函数 f f f定义如下:
f ( s ) = ∑ i w i ψ i ( s ) s ∑ i ψ i ( s ) \begin{aligned} f(s)=\frac{\sum_{i} w_{i} \psi_{i}(s) s}{\sum_{i} \psi_{i}(s)} \end{aligned} f(s)=∑iψi(s)∑iwiψi(s)s
其中, ψ i = e x p ( − h i ( s − c i ) 2 ) \psi_{i}=exp(-h_{i}(s-c_{i})^2) ψi=exp(−hi(s−ci)2)为高斯基函数, c i c_{i} ci为高斯基函数中心, h i h_{i} hi为高斯基函数宽度, w i w_{i} wi为可调权重。函数 f f f不直接依赖时间 t t t,而是相变量 s s s的函数, s s s随着运动的进行,从1到到0单调递减,相变量 s s s满足公式:
公式4:
τ s ˙ = − α s \begin{aligned} \tau \dot{s} =-\alpha s \end{aligned} τs˙=−αs
其中 α \alpha α是一个预定义常数,上述公式通常被称为正则系统(canonical system)
使用这些方程表示运动的优势:
a.保证收敛到目标点 g g g,因为 f ( s ) f(s) f(s)会在运动的末端消失;
b.可以学习权重参数 w i w_{i} wi以生成任意期望的光滑轨迹;
c.方程是空间和时间不变的,即,对于起点、重点和时间缩放的变化,运动是自相似的,而不需要改变权重 w i w_{i} wi
解释:这里意思应该是泛化能力,给定任意起始点,运动轨迹总是和示教轨迹相似,不需要对微分方程做任何改变。
d.由于方程的固有吸引子动力学,该公式产生的运动对扰动是鲁棒的。
为了从示教中学习运动,首先,需要记录示教轨迹 x ( t ) x(t) x(t),以及他的导数 v ( t ) v(t) v(t)和 v ˙ ( t ) \dot v(t) v˙(t),第二,对正则系统进行合并,即,为适当的时间缩放因子 τ \tau τ计算 s ( t ) s(t) s(t)。因此:
f t a r g e t ( s ) = − K ( g − x ) + d v + τ v ˙ g − x 0 \begin{aligned} f_{target}(s)=\frac{-K(g-x)+dv+\tau \dot v}{g-x_{0}} \end{aligned} ftarget(s)=g−x0−K(g−x)+dv+τv˙
这里 f t a r g e t f_{target} ftarget只是通过公式得到的,另外 f f f还可以表示为多个高斯基函数的组合。因此为了求权重 w i w_{i} wi,可以转化为求解一个线性回归问题 J = ∑ s ( f t a r g e t ( s ) − f ( s ) ) 2 J=\sum _{s}(f_{target}(s)-f(s))^2 J=∑s(ftarget(s)−f(s))2。有了权重 w i w_{i} wi,给定不同起始点,便可生成与示教轨迹相同趋势的运动。
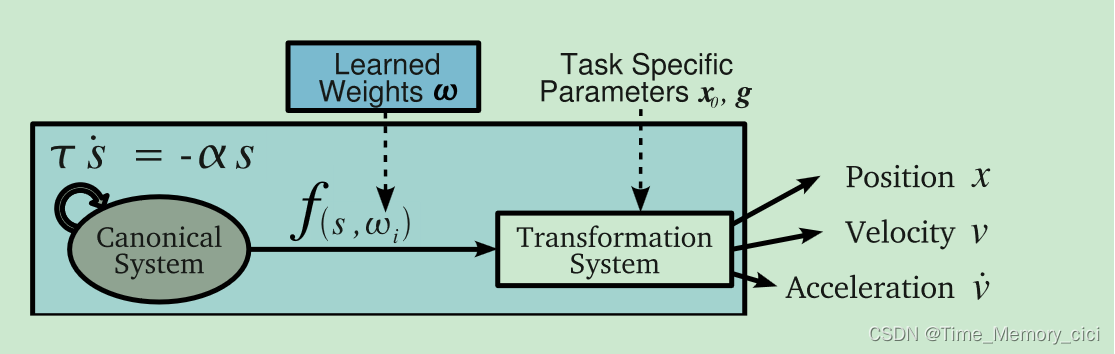
图1.一维DMP的原理图:正则系统驱动非线性函数f,该函数扰动变换系统以计算期望的运动。
B. 泛化到新的目标
经典DMP方法泛化到新的目标点时有三个缺点:1,如果运动的起点 x 0 x_{0} x0和终点 g g g一样,则公式1中的非线性项不能驱动系统离开起点 x 0 x_{0} x0,这将导致系统停留在初始点 x 0 x_{0} x0。2、如果 g − x 0 g-x_{0} g−x0接近零,函数 f f f的缩放 g − x 0 g-x_{0} g−x0是有问题的。在这里, g g g的微小变化可能会导致巨大的加速度,这可以打破机器人的极限。3、每当一个动作适应一个新的目标 g n e w g_{new} gnew,使得 ( g n e w − x 0 ) (g_{new}-x_{0}) (gnew−x0)与 ( g o r i g i n a l − x 0 ) (g_{original}-x_{0}) (goriginal−x0)相比改变了它的符号时,所产生的泛化就会被镜像(想象一下sin曲线)。因此,作为本论文实验中的一个例子,在桌子上放置动作的起点和终点位置大致相同;因此,最初的DMP公式不适合将这种运动适应新的目标位置。
C. 改进的DMP
本文提出改进的DMP以解决上述问题,而且保留DMP的有优点,改进后的DMP如下:
τ v ˙ = K ( g − x ) − D v − K ( g − x 0 ) s + K f ( s ) τ x ˙ = v \begin{aligned} \tau \dot{v} &=K(g-x)-Dv-K(g-x_{0})s+Kf(s) \\ \tau \dot{x} &=v \end{aligned} τv˙τx˙=K(g−x)−Dv−K(g−x0)s+Kf(s)=v
其中 f ( s ) f(s) f(s)和经典DMP中的定义一致,正则系统有和前面公式4一致。与经典DMP的重要不同是非线性函数 f ( s ) f(s) f(s)不再乘 ( g − x 0 ) (g-x_{0}) (g−x0),改进DMP的第三项 K ( g − x 0 ) s K(g-x_{0})s K(g−x0)s用于避免运动开始时的跳跃,学习和传播DMP和之前步骤是一样的,只是目标函数 f t a r g e t f_{target} ftarget是根据以下公式计算:
f t a r g e t ( s ) = τ v ˙ + D v K − ( g − x ) + ( g − x 0 ) s \begin{aligned} f_{target}(s)=\frac{\tau \dot v+Dv}{K}-(g-x)+(g-x_{0})s \end{aligned} ftarget(s)=Kτv˙+Dv−(g−x)+(g−x0)s
D. 避障
用动态系统表示运动的一个主要原因是对抗扰动的鲁棒性,本文利用这个性质,添加一个耦合项 p ( x , v ) \mathbf{p}(\mathbf{x}, \mathbf{v}) p(x,v)到微分方程,以达到避障的目的。
τ v ˙ = K ( g − x ) − D v − K ( g − x 0 ) s + K f ( s ) + p ( x , v ) \begin{aligned} \tau \dot{\mathbf{v}}=\mathbf{K}(\mathbf{g}-\mathbf{x})-\mathbf{D} \mathbf{v}-\mathbf{K}\left(\mathbf{g}-\mathbf{x}_{0}\right) s+\mathbf{K} \mathbf{f}(s)+\mathbf{p}(\mathbf{x}, \mathbf{v}) \end{aligned} τv˙=K(g−x)−Dv−K(g−x0)s+Kf(s)+p(x,v)
作者在三维末端执行器空间描述障碍物,因此改进DMP公式中的标量 x , v , v ˙ x,v,\dot v x,v,v˙调整为向量 x , v , v ˙ \mathbf{x},\mathbf{v},\mathbf{\dot v} x,v,v˙,以及标量 K , D K,D K,D变为正定矩阵 K , D \mathbf{K},\mathbf{D} K,D。具体的,耦合项为:
p ( x , v ) = γ R v φ exp ( − β φ ) \begin{aligned} \mathbf{p}(\mathbf{x}, \mathbf{v})=\gamma \mathbf{R} \mathbf{v} \varphi \exp (-\beta \varphi) \end{aligned} p(x,v)=γRvφexp(−βφ)
其中, R \mathbf{R} R是绕轴 r = ( x − o ) × v \mathbf{r}=(\mathbf{x}-\mathbf{o})\times \mathbf{v} r=(x−o)×v旋转 π / 2 \pi/2 π/2的旋转矩阵, γ \gamma γ和 β \beta β是常数, φ \varphi φ末端执行器朝向障碍物方向和末端执行器相对于障碍物的速度矢量 v \mathbf{v} v之间的角度。本文的实验中, γ = 1000 \gamma=1000 γ=1000和 β = 20 \beta=20 β=20
三、构建运动库
这一部分简要介绍了运动库的概念及其在物体操作任务中的应用。
A. 运动库生成
学习DMP只需要用户演示特征动作。这些DMP形成了一组基本的动作单元。对于运动再现,只需要一个简单的高级命令来选择基元(或它们的序列)并设置其任务特定的参数。更重要的是,通过调整起点 x 0 x_{0} x0、目标点 g g g和运动持续时间 τ \tau τ来实现对新情况的适应。因此,被称为运动库的基元集合使系统能够生成大范围的运动。另一方面,这样的运动库可以用来促进运动识别,因为观察到的运动可以与预先学习到的运动进行比较。如果没有现有的基元与所演示的行为很好地匹配,则会创建(学习)一个新的基元,并将其添加到系统的动作库中(图2)。这使得所提出的公式适合于模仿学习。
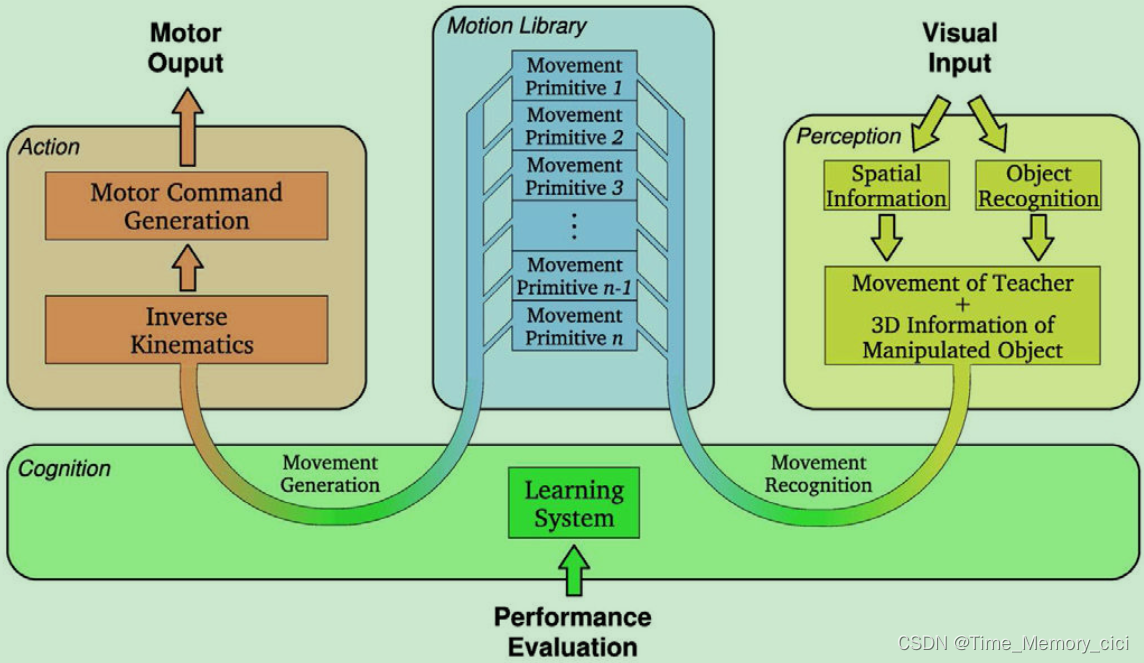
图2、模仿学习系统的概念示意图。感知的组成部分(黄色)将视觉信息转换为空间和对象信息。动作部件(红色)产生电机输出。它们之间的交互是使用公共运动库(蓝色)实现的。学习(绿色)改进了包含在运动库中的感知和基元之间的映射,用于运动识别和选择用于运动生成的最合适的基元。
B. 附加语义
对于DMPs的模仿学习,作者选择了一种低级的方法,即轨迹的模仿。然而,系统需要额外的信息来成功执行物体操作任务。例如,对于拾取和放置操作,系统必须选择适当的移动基元序列,即,首先是抓取,然后是放置,最后是释放基元。因此,有必要将附加信息添加到每个运动基元,以便于进行此选择。此外,一旦有了运动基元库,就希望系统能够找到完成进一步任务的基元运动序列。传统的人工智能规划算法通过将领域场景形式化来解决这个问题。特别是,他们定义了一组具有前置和后置条件的操作符,并搜索其中的一个序列,该序列将世界从初始状态转移到目标状态。后条件提供了有关世界变化的信息,而先决条件确保了计划的可执行性。因此,这样的算法基于对象和动作的离散符号表示,而不是动作执行的低级连续细节。
低级连续控制表示(在机器人应用中是典型的)和动作及其对物体的影响的高级形式化描述(在规划中是必要的)之间的联系已经通过对象动作复合体的概念形式化。这个概念提出物体和动作是不可分割地交织在一起的。如图3
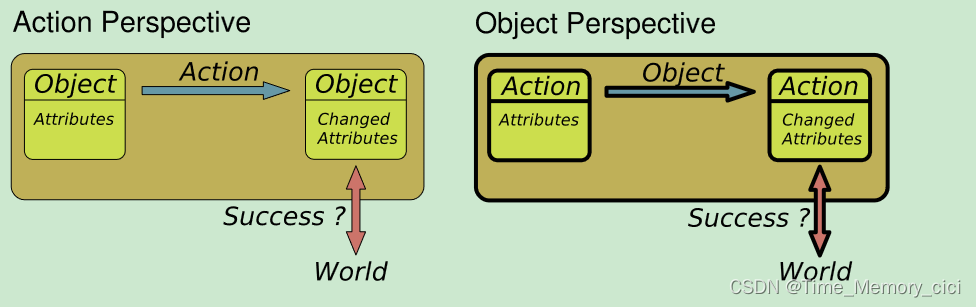
图3、物体是通过可以对其执行的动作来定义的(左),例如,杯子被表示为可以用来喝水的东西。另一方面,动作是通过物体来定义的(右),例如抓握物体的方式取决于物体——罐子需要不同于钢笔的抓握方式。
C. 运动基元的组合
组合运动基元以生成更复杂的运动的能力是运动库概念的先决条件。在这里,作者展示了所提出的框架是如何提供这种能力的。
在前一个DMP完全执行之后,开始执行下一个DMP,因为任何DMP的边界条件(boundary conditions)都是零速度和加速度。然而,也可以对DMP进行排序,以避免移动系统完全停止(图4)。这是通过在前一个DMP完成之前开始执行连续的DMP来实现的。在这种情况下,两个连续DMP之间的运动系统的速度和加速度不为零。加速度信号的跳跃是可以避免的,通过使用前一个DMP的速度和位置来正确的初始化下一个DMP( v p r e d → v s u c c \mathbf v_{pred}\rightarrow\mathbf v_{succ} vpred→vsucc和 x p r e d → x s u c c \mathbf x_{pred}\rightarrow\mathbf x_{succ} xpred→xsucc)。

图4、四个直的最小急动运动基元的链接,其端点由黑点标记。(a)由DMP生成的移动被绘制为交替的蓝色实线和红色虚线,以表示两个连续DMP之间的转换。移动方向由箭头指示。剩余的移动(b)是使用不同的切换时间产生的(较浅的颜色表示切换时间较早)。
四、实验
实验部分描述了如何将提出的DMP框架应用于机械臂,以完成物体操作任务,如抓取和放置。本文使用了一个配有三自由度末端执行器的7自由度仿人机械臂作为实验平台。
A. 从演示中学习DMP
从演示中学习DMP是通过分别考虑每个DOF并为每个DOF使用单独的转换系统来实现的。因此,每个DMP都设置有总共十个转换系统来对每个运动学变量进行编码。特别地,所涉及的变量是末端执行器在笛卡尔空间中的位置 ( x , y , z ) (x,y,z) (x,y,z),末端执行器在四元数空间中的姿态 ( q 0 , q 1 , q 2 , q 3 , ) (q_{0},q_{1},q_{2},q_{3},) (q0,q1,q2,q3,),以及在关节空间中的手指位置 ( θ T L , θ T V , θ F A A ) (\theta_{TL},\theta_{TV},\theta_{FAA}) (θTL,θTV,θFAA)。它们中的每一个都作为一个单独的学习信号,而不考虑潜在的物理解释。然而,为了确保四元数 q q q的单位长度,引入了后归一化步骤(post-normalization)。该步骤如图7所示,注意,单个DMP同时对三个不同坐标系中的运动进行编码。
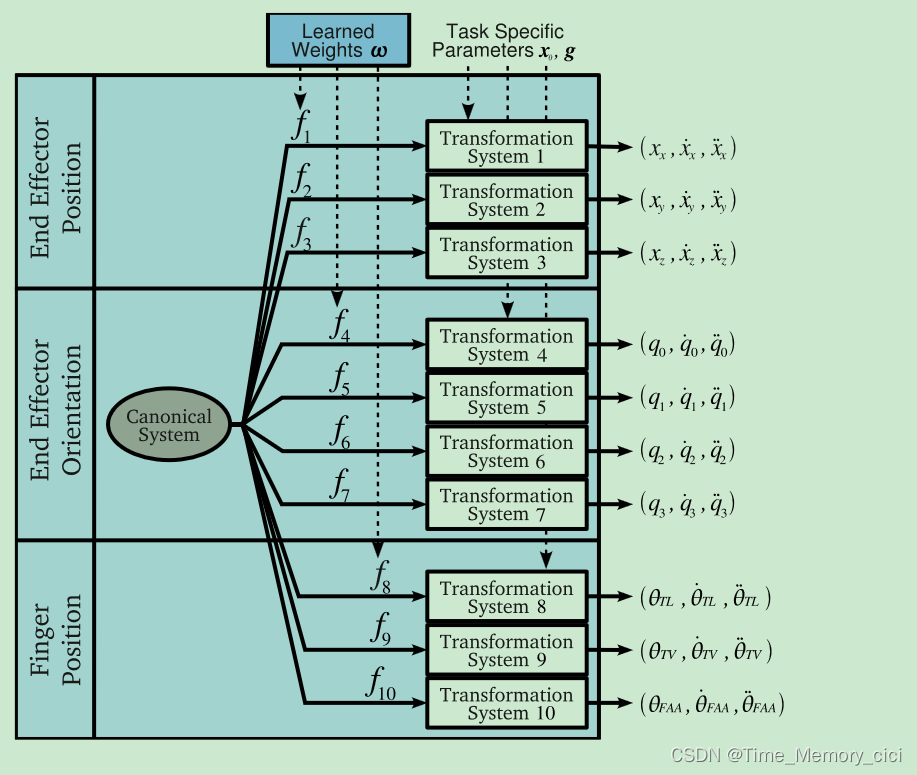
图7、用于生成Sarcos机械臂运动规划的10维DMP示意图。
为了记录一组动作,作者使用了一个10自由度的外骨骼机械臂,如图8所示。视觉观察和适当的处理来获得任务变量也是可能的,但由于这种感知成分目前不是我们研究的重点,因此被避免了。

图8、用于记录末端执行器空间中人类轨迹的Sarcos主臂。在这里,受试者展示了一个倾倒动作,在学习DMP后,机器人能够将水倒入几个杯子中(图12)。
末端执行器的位置和姿态以480Hz记录。随后相应地生成手指移动的相应轨迹:例如,对于抓取运动,轨迹由打开和关闭夹爪的两个最小急动运动组成。通过对位置信号进行微分,对所有自由度的相应速度和加速度进行了数值计算。
这些信号用作II-A中描述的监督学习过程的输入。对于每个演示的动作,学习一个单独的DMP并将其添加到动作库中。
B. 运动生成
为了生成运动规划,DMP设置特定任务的参数,即起点 x 0 x_{0} x0和目标点 g g g。在本文的DMP设置中(图7),这些是末端执行器位置、末端执行器姿态和手指关节配置。运动的开始 x 0 x_{0} x0被设置为机械臂的当前状态。目标 g g g是根据运动的背景设定的。对于抓取运动,目标位置 ( x , y , z ) (x,y,z) (x,y,z)设置为被抓物体的位置,抓取宽度根据物体的大小设置。然而,找到合适的目标姿态并不是直接的,因为末端执行器的方向需要适应运动的特征接近曲线。从正面接近物体会产生与从侧面接近物体不同的最终姿态。以抓取运动为例,本文开发了一种方法,通过传播DMP来生成笛卡尔空间轨迹,并对速度矢量进行平均来计算运动结束时的接近方向,从而自动确定最终姿态。对于其他运动,如放置和释放,我们将末端执行器的方向设置为从人类演示中记录的方向。最后,我们使用 τ \tau τ来确定每个动作的持续时间。在仿真中,我们展示了演示动作的复现和泛化。我们模拟的机器人手臂具有与Sarcos Slave手臂相同的运动学和动力学特性。抓取和放置的复现如图9所示。这些运动对新目标的泛化如图10所示。
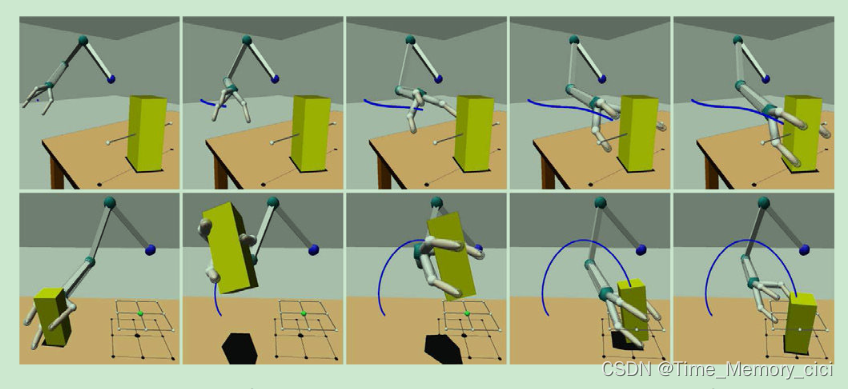
图9、SL仿真器展现了Sarcos Slave机械臂完成抓取(上图)和放置(下图)运动的快照
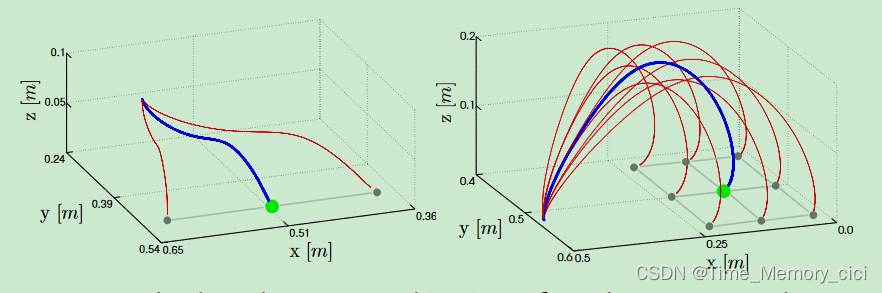
图10、—图9所示运动的预期轨迹(蓝线)泛化到新目标位置(红线)。
C. 任务空间控制
为了在机器人上执行DMP,本文使用了[13]、[8]中所述的基于速度的逆运动学控制器。因此,任务空间参考速度 x ˙ r \dot x_{r} x˙r转换为参考关节空间速度 θ ˙ r \dot \theta_{r} θ˙r(图11)。参考关节位置 θ r \theta_{r} θr和加速度 θ ¨ r \ddot \theta_{r} θ¨r是通过参考关节速度 θ ˙ r \dot \theta_{r} θ˙r的数值积分和微分获得的。DMP作为单位四元数给出的期望姿态是使用四元数反馈控制的,如[14]、[8]所述。
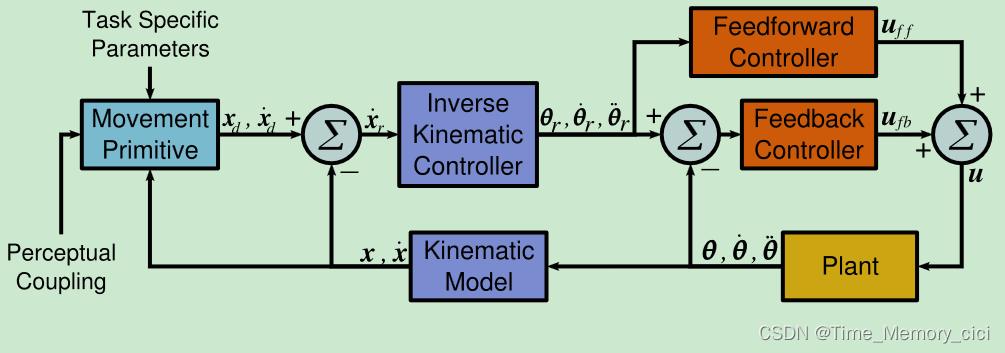
图11、DMP控制图:期望的任务空间位置和速度为 x d x_{d} xd和 x ˙ d \dot x_{d} x˙d,参考的任务空间速度命令为 x ˙ r \dot x_{r} x˙r,参考的关节位置,关节速度,关节加速度为 θ r \theta_{r} θr, θ ˙ r \dot \theta_{r} θ˙r和 θ ¨ r \ddot \theta_{r} θ¨r
参考的关节位置,关节速度,关节加速度通过前馈和反馈转换为合适的力矩命令 u u u
使用前馈和反馈分量将参考关节位置、速度和加速度转换为适当的扭矩指令 u u u。前馈部件估计相应的名义转矩,以补偿关节之间的所有相互作用,而反馈部件实现PD控制器。
D. 机器人实验
作者在倒水演示中展示了所提框架的实用性(图12)。首先,人类演示者进行了抓握、倾倒、后退和释放动作。其次,机器人学习了这些动作,并将它们添加到运动库中。第三,桌子上放了一瓶水和三个杯子。第四,手动选择适当的运动基元序列。第五,每个DMP都设置了相应的目标 g g g。最后,机器人通过简单地改变倾倒运动的目标点 g g g来执行运动序列并推广到不同的杯子位置。

图、12
为了证明所提框架能够在线适应新目标并避免障碍,我们用立体相机系统扩展了实验设置。我们使用基于颜色的视觉系统来直观地提取目标位置以及障碍物的位置(噪声:SD=0.001m每个维度)。任务是抓住一个红色的杯子,把它放在一个绿色的杯托上,托盘在运动开始后改变位置,同时避开蓝色的球状障碍物(图13)。为了完成这项任务,使用了与之前类似的程序。这次实验中,抓取动作的笛卡尔目标被设置为红色杯子的位置,而放置动作的目标则被设置为绿色托盘。抓取动作的目标姿态是如第IV-B节所述自动设置的,而放置和释放的方向是从演示中采用的。这种设置使我们能够通过将红杯放置在不同的初始位置来展示框架泛化抓取动作的能力。改方法可以根据机器人移动过程中改变目标位置而调整动作。此外,移动轨迹被自动调整以避免移动障碍物(图13)。

图13、
五、总结和未来工作
本文将动态运动原语的框架扩展到允许物体操作的动作序列。作者对原始DMP框架进行了几项改进:对新目标的鲁棒泛化、像人一样的适应和自动避障。此外,我们在DMP中添加了语义信息,这样它们就可以对动作进行编码。作者在仿真环境中证明了该方法的可行性,机器人从人类的演示中学习了倒水和取放任务,并可以将该任务推广到新的情况。
该方法并不局限于所提供的实验平台。能够提取末端执行器位置和方向的任何类型的运动捕捉系统都可以替代Sarcos主臂,并且能够在任务空间中跟踪参考轨迹的任何机械手都可以代替Sarcos从臂。
未来的工作将大大扩展动作库,以便能够代表丰富的动作。此外,未来工作将侧重于将对象与行动相关联(类似于[12]),以实现行动序列的规划。最后,作者计划把这个扩展框架应用到一个人形机器人上。