搜索微信公众号:‘AI-ming3526’或者’计算机视觉这件小事’ 获取更多人工智能、机器学习干货
csdn:https://blog.csdn.net/qq_36645271
论文报告PPT下载方式:可以在我上传的资源中找到
报告题目:SketchML: Accelerating Distributed Machine Learning with Data Sketches
中文翻译:SketchML:使用数据草图加速分布式机器学习
论文来源:2018 ACM SIGMOD International Conference on Management of Data
一、 摘要
- 背景:由于许多由随机梯度下降(SGD)训练的分布式ML算法都涉及到通过网络传输梯度,因此压缩传输梯度非常重要。
- 遇到的问题:现有的低精度方法不适用于梯度稀疏和非均匀分布的情况。
- 提出的问题:是否有一种压缩方法能否有效地处理由键值对组成的稀疏非均匀梯度?
- 提出的解决方法:
- 用Quantile-Bucket Quantification来压缩梯度值。
- 用MinMaxSketch来压缩桶索引值,解决哈希冲突。
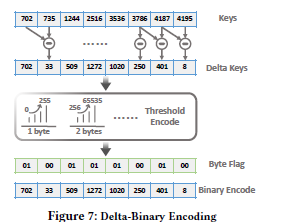
- 用Delta-Binary Encoding来通多一种增量的方式压缩梯度建。
- 先进性:第一次将data sketch与ML相结合,并通过实验表明我们的方法比现有方法快10倍。
二、 介绍
- 背景与动机
随着数据量的空前增长,集中式系统无法有效地运行ML任务。因此,在分布式环境中部署ML是不可避免的。在这样的背景下,一个主要的问题是如何有效的交换节点之间的梯度,因为沟通往往占总成本。
- 案例1:大型模型
- 案例2:云计算环境
- 案例3:地理分布的机器学习
- 案例4:物联网
在上述机器学习情况中,在保证算法正确性的同时,减少通过网络传输的梯度具有重要意义。通常,使用压缩技术来解决这个问题。现有的压缩方法可归纳为两类:无损压缩方法和有损压缩方法。重复整数数据的无损方法,不能用于非重复梯度键和浮点梯度值。提出了一种基于阈值截断或量化策略来压缩浮点梯度的有损方法,但基于阈值的截断过于激进,无法使ML算法收敛。
从以上分析可以看出,现有的压缩方法对于大规模梯度优化算法还不够强大。在这个挑战的激励下,我们研究了一个问题:
我们应该用那种数据结构来压缩系数梯度向量?
- 技术贡献综述
- 数据模型
我们主要研究一类用随机梯度下降(SGD)训练的机器学习算法,如逻辑回归和支持向量机。在分布式设置中,我们选择数据并行策略,将数据集划分到W个工作站之上。 - 如何压缩梯度值
第一个目标是压缩键值对中的梯度值。由于均匀量化不适用于非均匀分布梯度,一种替代的概率数据结构是Sketch算法,它被广泛用于分析数据流。现有的草图算法包括Quantile Sketch和Frequency Sketch。 Quantile Sketch用于估计项目的分布,而Frequency Sketch用于估计项目的发生频率。 - 如何压缩梯度键
第二个目标是压缩键值对中的梯度键。与能够承受低精度路径的梯度值不同,梯度键容易产生误差。因此,我们需要一种无损压缩梯度键的方法,否则无法保证优化算法的正确收敛。由于键值对是按键排序的,这意味着键是按升序排列的,所以我们建议使用delta格式存储键。 - 评估
为了系统地评估我们提出的方法,我们在Spark上实现了一个原型。在腾讯的一个实际集群中,我们使用两个大型数据集来运行一系列机器学习工作。我们提出的框架草图比最先进的方法快2-10倍。
- 数据模型
三、 预备知识
- 符号定义
- W:工作站的个数。
- N:训练实例的个数。
- D:模型的维度。
- g:一个梯度向量。
- d:梯度向量中非0维度的个数。
- (kj,vj):稀疏梯度向量中第j个非0键值对。
- m:分为草图的大小。
- q:分为分割点的个数。
- s,t:最大最小草图中的行与列,s表示哈希表的个数,t表示哈希表中的格数。
- r:最大最小草图的组数。
- 分为草图
Quantile Sketch使用一个小的数据结构来近似项目值的精确分布。 Quantile Sketch的主要组成部分是分位数汇总,分位数汇总由来自原始数据的少量点组成。分位数汇总有两个主要操作——merge和prune。merge操作将两个数据合并到一个分位数中,而prune操作减少了合并数据的数量,以避免超过最大的大小。 - 频率草图
数据流中另一个常见的实际情况是项的重复出现。由于项目的值范围较大,不可能存储所有可能的项目,因此提出了Frequency Sketch来估计项目不同值的频率。
四、 SketchML框架
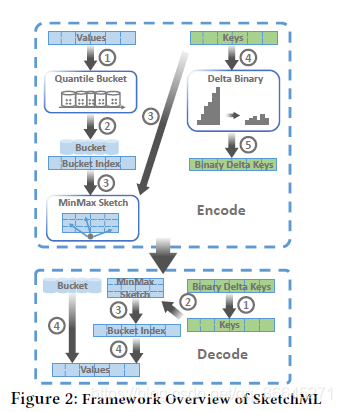
- 框架总览
该框架中有三个主要组件,即分位桶量化、MinMaxSketch和动态增量二进制编码。前两个组件一起压缩梯度值,而第三个组件压缩梯度键。
- 编码阶段。
- Quantile Sketch用于生成候选分割,我们使用桶排序来总结梯度值。
- 梯度值由桶的索引表示。
- 通过对键应用哈希函数,将桶索引插入MinMaxSketch。
- 将梯度键转换为增量,本文用增量键表示。
- 我们使用二进制编码用更少的字节来编码delta键,而不是使用四字节整数。
- 解码阶段。
- 增量键恢复到原始键。
- 使用恢复的密钥查询MinMaxSketch。
- 每个值的桶指数由示意图得到。
- 通过使用bucket索引查询bucket值来恢复该值。
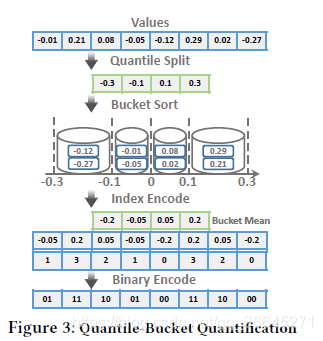
- Quantile-Bucket Quantification
- 步骤1:分位数分裂。
- 我们扫描所有的梯度值并将它们插入分位数草图。
- q分位数用于从分位数草图中提取候选分位数。具体来说,我们生成了q的平均分位数{0,1/q,2/q,…,q-1/q}。
- 我们使用分位数和最大值作为分割值,用{rank(0),rank(1/q), rank(2/q),…,rank(1)}。注意,值位于两个连续分割之间的项的数量是N/q,这意味着我们用项的数量而不是值除以项的数量。两个分割之间的每个区间都有相同数量的梯度值。
- 步骤2:桶排序。
- 我们称两次分割之间的每个间隔为一个桶。较小的分割是桶的较低阈值,较大的分割是较高的阈值。
- 根据桶的阈值,每个梯度值属于一个特定的桶。例如,图3中0.21的值被分类到第四个桶中。
- 每个桶用均值表示,即平均值。
- 将每个梯度值转换为对应的桶均值。
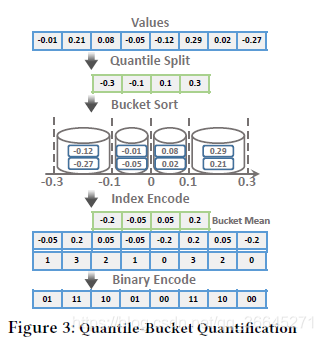
- 步骤3:索引编码。
虽然我们用桶的平均值来量化梯度值,但是所消耗的空间是相同的。为了降低空间成本,我们选择了存储bucket索引的替代方法。我们将桶的平均值编码为桶索引。例如,将0.21量化为用均值表示的第四个桶之后,我们通过桶索引从零开始对其进行编码,即0.21对应的是数字3。 - 步骤4:二进制编码。
通常,桶的数量是一个小整数。我们通过将bucket索引编码为二进制数来压缩它们。如果q=256,一个字节就足够对bucket索引进行编码。通过这种方式,我们将占用的空间减少,我们可以在很大程度上减少传输的数据。
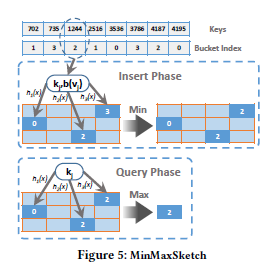
- MinMaxSketch
- 插入的阶段。
- 每个输入项由原始密钥和已编码的桶索引(kj,b(vj))组成。
- 使用s哈希函数计算哈希码。在图5中,有三个哈希函数,h1(-)、h2(-)和h3(-)。
- 在第i个哈希表中选择一个哈希bin后,比较当前值H(i,hi(kj))和b(vj)。如果H(i,hi (kj)) > b(vj),我们用b(vj)替换当前值。否则,我们不更改当前值。
- 查询阶段。
- 输入为梯度键,用kj表示。s哈希函数应用于kj,每个哈希函数从哈希表中选择一个哈希bin。
- 给定不同行的s个候选项,选择最大的作为最终结果。在图5中,三个候选项是{0,2,2},我们选择2作为结果。
- Delta-Binary Encoding
通过对梯度键数据分布的分析,发现梯度键具有三个特征。首先,键是非重复的。其次,键按升序排列。第三,尽管在许多高维应用中键可以非常大,但是相邻键之间的差别要小得多。基于以上三点,我们建议只存储键的增量。
- 步骤1:增量编码
梯度键存储在数组中。我们从头到尾扫描数组,并计算两个相邻键之间的差值。然后,我们得到键的增量,我们称之为键。 - 步骤2:二进制编码
通过增量编码,很明显增量键要比原始键小得多。如果我们以整数或长整数的格式存储delta键,那么压缩是没有意义的,因为所消耗的内存空间和通信成本保持不变。为了解决这个问题,我们将不同的空间分配给不同的delta键,并将它们编码为二进制格式。
五、 实验
- 实验设置
- 实现。我们在Spark上实现了一个原型。训练数据集在executor上进行分区。每个executor读取子集并计算梯度。driver聚合来自executor的梯度,更新经过训练的模型,并将更新后的模型传播给executor。这个过程迭代直到收敛。
- 集群。实验中使用了两个集群。集群1是我们实验室的一个十节点集群,使用这个集群来评估我们提出的方法的有效性。集群2是腾讯公司一个拥有300个节点的生产集群,使用这个集群来比较三种模型的端到端性能。
- 数据集。实验中使用了三个数据集。第一个数据集KDD10由KDD CUP 2010发布的公共数据集,包含1900万个实例和2900万个特性。第二个数据集KDD12是KDD10的下一代。第三个数据集CTR是腾讯公司的专有数据集。
- 统计模型。我们选择了三种常用的机器学习模型:2-正则化逻辑回归(LR)、支持向量机(SVM)和线性回归(Linear)。
- 基线。实验将SketchML与两个竞争对手:Adam SGD和ZipML进行了比较。
- 指标。每个历元的平均运行时间和相对于运行时间的损失函数。
- 提出模型的效率
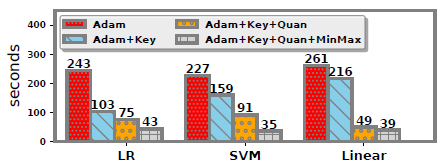
- 运行时间
根据如图所示的结果,我们提出的方法可以显著加快三种不同ML算法的执行速度。
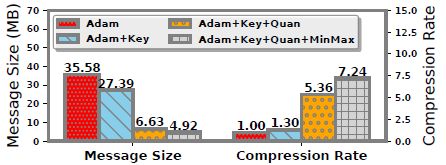
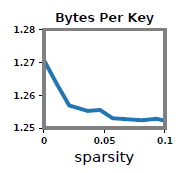
- 消息大小和压缩率
压缩的主要优点是减小了消息的大小。如图显示执行期间的平均消息大小和压缩率。
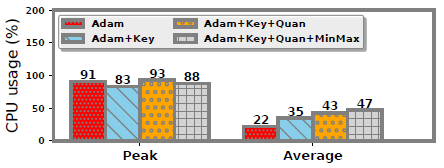
- CPU开销
为了评估压缩带来的计算开销,我们进行了一个实验,结果如图所示。我们的方法平均引入了25%的CPU使用量。CPU使用率峰值没有明显的影响。
- 批量大小和稀疏性影响
由于我们的方法压缩稀疏梯度,它提出了一个问题,数据稀疏性如何影响性能。在我们的设置中,梯度的稀疏性受批大小的影响。因此,我们通过改变批量大小的比例来改变稀疏性。
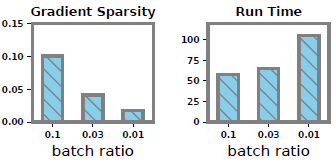
增量二进制编码的通信成本直接受到数据稀疏性的影响。因此,我们在图中记录了增量二进制编码对数据稀疏性变化的性能。
- 运行时间
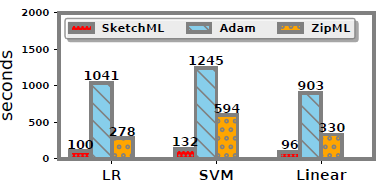
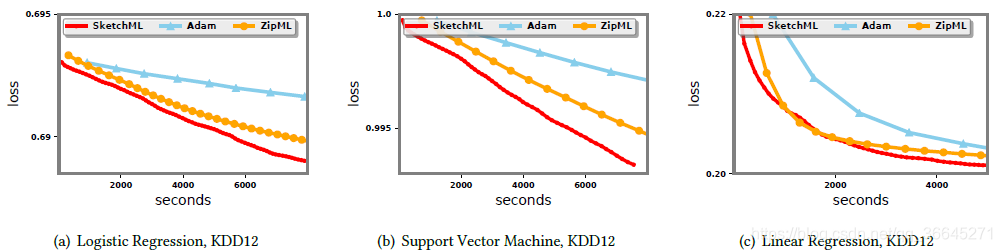
- 端到端表现
- KDD12数据集
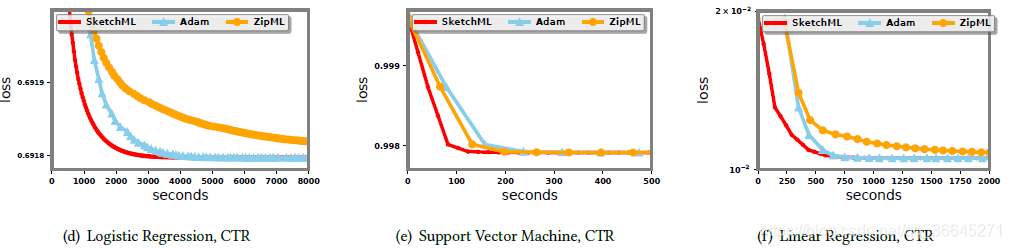
- 逻辑回归。如图所示,无论是运行时间还是收敛速度SketchML比Adam和ZipML运行得快得多。
- 支持向量机。支持向量机的结果与逻辑回归的结果相似。Adam是最慢的,其次是ZipML。
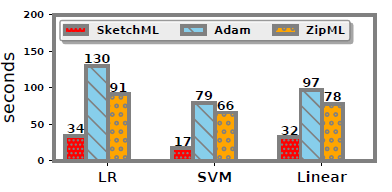
- 线性回归。对于线性回归,Adam和ZipML每历元分别花费903秒和330秒,而SketchML只需要96秒。
- CTR数据集
- 逻辑回归。在这个较大的数据集中,Adam仍然运行得最慢,其次是ZipML。SketchML比其他两种方法分别快3.8倍和2.7倍。
- 支持向量机。SketchML比Adam和ZipML快4.59和3.88倍。与逻辑回归和线性回归相比,支持向量机更容易在该数据集上收敛。
- 线性回归。SketchML需要32秒来训练一个线性回归历元,而Adam和ZipML需要97秒和78秒。
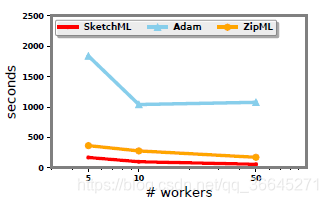
- 可扩展性
对于逻辑回归、支持向量机,线性回归来说,可移植性大致相同,治理只报告逻辑回归的可移植性。如图所示,当执行者数目从5增加到10时,三种方法的性能都有所提高。
六、 总结
为了加快分布式机器学习的速度,本文提出了一种基于草图的方法,即SketchML,来压缩通信的键值梯度。首先,我们介绍了一种方法,该方法使用分位数草图和桶排序来表示具有较小二进制编码桶索引的梯度值。然后,我们设计了一个MinMaxSketch算法来近似压缩桶索引。此外,我们还提出了一种对梯度键进行编码的增量二进制方法。从理论上分析了该方法的误差范围。在一系列大规模数据集和机器学习算法上的实验结果表明,SketchML可以比最先进的方法快10倍。
AIMI-CN AI学习交流群【1015286623】获取更多AI资料,扫码加群:

分享技术,乐享生活:欢迎关注我们的公众号,每周推送AI系列资讯类文章,欢迎您的关注!
