参考网址:https://blog.csdn.net/weixin_39881922/article/details/80569803
https://blog.csdn.net/liuyan20062010/article/details/78905517
https://blog.csdn.net/ei1990/article/details/75282855
1.下载SSD框架到本地
2.测试:在notebook中测试ssd_notebook.ipynb中的代码,该文件是完成对于单张图片的测试(如果想改为py格式可参考https://blog.csdn.net/weixin_39881922/article/details/80569803)
3.准备自己的数据集
4.修改datasets文件夹中pascalvoc_common.py文件,将训练类修改别成自己的。
VOC_LABELS = {
'none': (0, 'Background'),
'aeroplane': (1, 'Vehicle'),
'bicycle': (2, 'Vehicle'),
'bird': (3, 'Animal'),
'boat': (4, 'Vehicle'),
'bottle': (5, 'Indoor'),
'bus': (6, 'Vehicle'),
'car': (7, 'Vehicle'),
'cat': (8, 'Animal'),
'chair': (9, 'Indoor'),
'cow': (10, 'Animal'),
'diningtable': (11, 'Indoor'),
'dog': (12, 'Animal'),
'horse': (13, 'Animal'),
'motorbike': (14, 'Vehicle'),
'Person': (15, 'Person'),
'pottedplant': (16, 'Indoor'),
'sheep': (17, 'Animal'),
'sofa': (18, 'Indoor'),
'train': (19, 'Vehicle'),
'tvmonitor': (20, 'Indoor'),
}
5.将图像数据转换为tfrecods格式,修改datasets文件夹中的pascalvoc_to_tfrecords.py文件,然后更改文件的83行读取方式为’rb‘,如果你的文件不是.jpg格式,也可以修改图片的类型。

然后使用使用 tf_convert_data.py进行数据转换。在终端输入转换命令:
DATASET_DIR=./VOC2007/test/
OUTPUT_DIR=./tfrecords
python tf_convert_data.py \
--dataset_name=pascalvoc \
--dataset_dir=${DATASET_DIR} \
--output_name=voc_2007_train \
--output_dir=${OUTPUT_DIR}我是用的方法为直接在 tf_convert_data.py文件中进行修改相应的路径,修改后的样子如下所示:
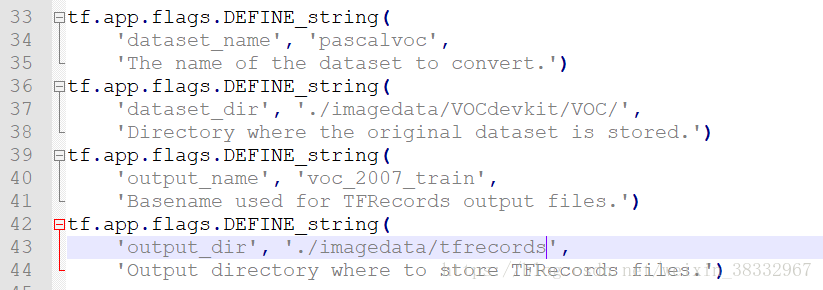
然后在cmd中转到相应路径下直接运行python tf_convert_data.py即可。
6.训练模型
train_ssd_network.py修改第154行的最大训练步数,将None改为比如50000。(tf.contrib.slim.learning.training函数中max-step为None时训练会无限进行。)
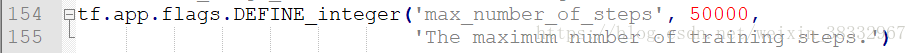
train_ssd_network.py,网络参数配置,若需要改,在此文件中进行修改
修改如下图中的数字600,可以改变训练多长时间保存一次模型

根据自己数据集的情况其他需要修改的地方:
a. nets/ssd_vgg_300.py (因为使用此网络结构) ,修改87 和88行的类别

b. train_ssd_network.py,修改类别120行,GPU占用量,学习率,batch_size等


c eval_ssd_network.py 修改类别,66行

d. datasets/pascalvoc_2007.py 根据自己的训练数据修改整个文件
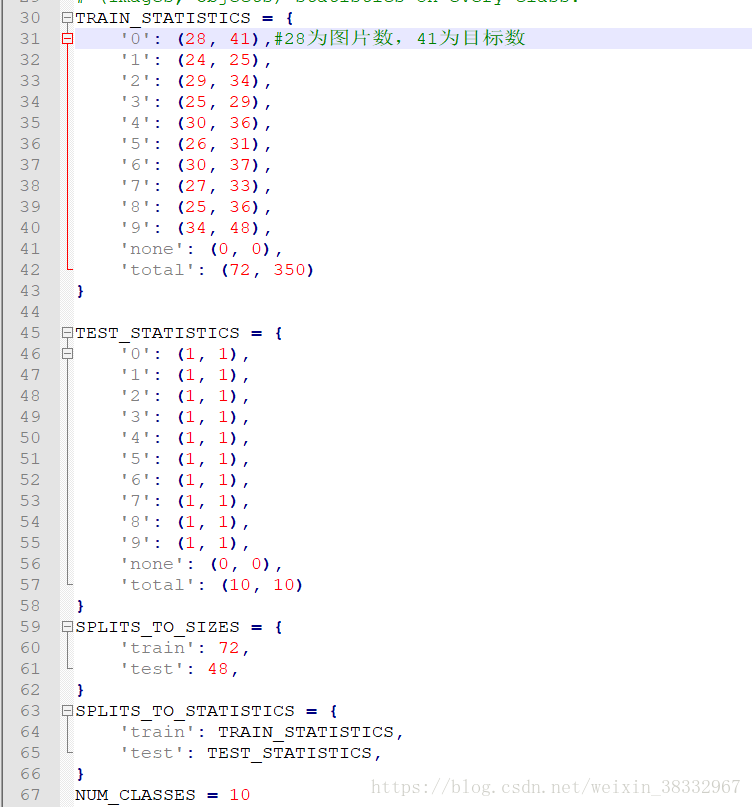
我修改后的数据如上所示,根据自己的理解,建议数据的存放格式为训练集、测试集放在独立的文件夹中,这里只需要修改TRAIN_STATISTICS变量,TEST_STATISTICS的值不需要修改,SPLITS_TO_SIZES为自己数据集的大小,注意此时NUM_CLASSES的值为自己数据集的类别数,不需要加1
7.通过加载预训练好的vgg16模型来训练自己的数据集,此时我仍然是通过修改train_ssd_network.py中文件的位置进而在命令行运行python train_ssd_network.py的。
在博客中介绍的训练网络的方法较多,并且也提供了可视化的方法,大家可以参考。