什么是遗传算法(GA)?
GA中的GA。
解决方案是什么样的?
GA流程及其运营商。
健身功能。
R中的遗传算法
自己尝试一下。
关于概念。
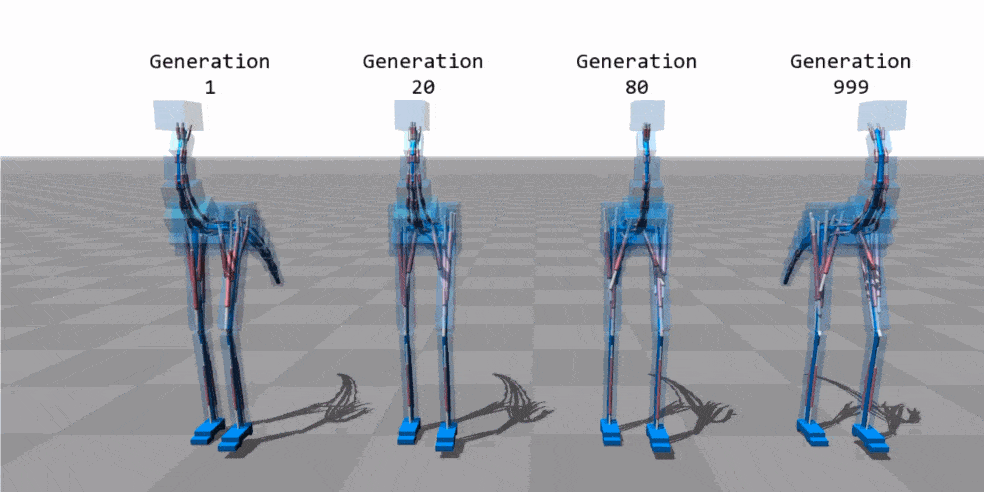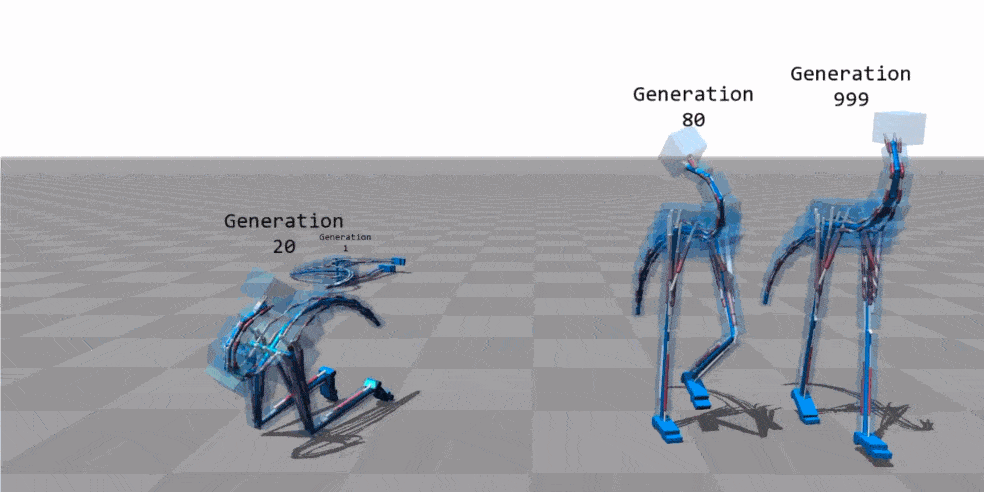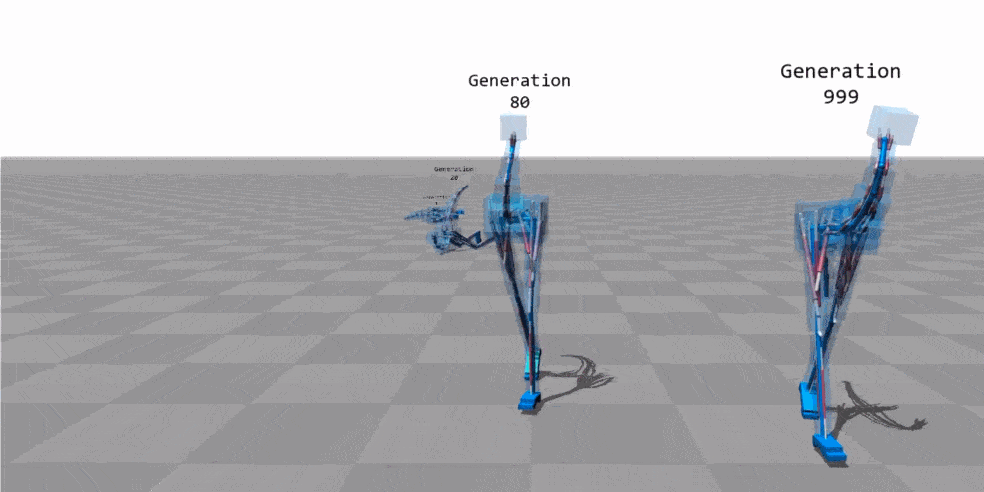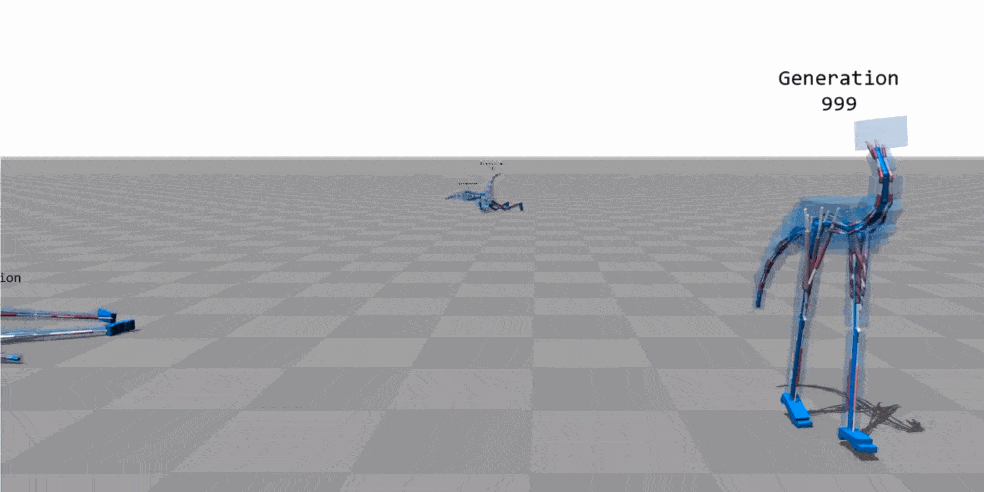
动画来源:“基于肌肉的双足动物运动” - Thomas Geijtenbeek
[在Twitter和LinkedIn上找到我]
项目背后的理念
想象一个黑盒子,它可以帮助我们在无限多种可能性之间做出决定,其标准是我们可以找到一个可接受的解决方案(时间和质量)来解决我们制定的问题。
什么是遗传算法?
遗传算法(GA)是一种受查尔斯达尔文自然选择思想启发的数学模型。
自然选择只保留了几代人中最适合的人。
想象一下,1900年有100只兔子。如果我们看一下今天的种群,我们将看到兔子比他们的祖先更有技巧,更擅长寻找食物。
GA中的GA
在机器学习中,遗传算法的一个用途是获取正确数量的变量以创建预测模型。
选择正确的变量子集是组合逻辑和优化的问题。
这种技术优于其他技术的优势在于它可以从最好的先前解决方案中获得最佳解决方案。一种进化算法,可以改善随时间的选择。
GA的想法是将一代又一代的不同解决方案结合起来,从每一个中提取最佳基因(变量)。通过这种方式,它可以创造新的更合适的人。
我们可以找到GA的其他用途,例如超调谐参数,找到函数的最大值(或最小值),或搜索正确的神经网络架构(神经进化)等。
特征选择中的GA
GA的每个可能的解决方案,即所选变量,被视为一个整体,因此它不会针对目标单独对变量进行排序。
这很重要,因为我们已经知道变量可以成组运行。
解决方案是什么样的?
保持示例简单,假设我们总共有6个变量,
一种解决方案可以拿起三个变量,比方说 var2,var4和var5。
另一种解决方案可以是 var1和var5。
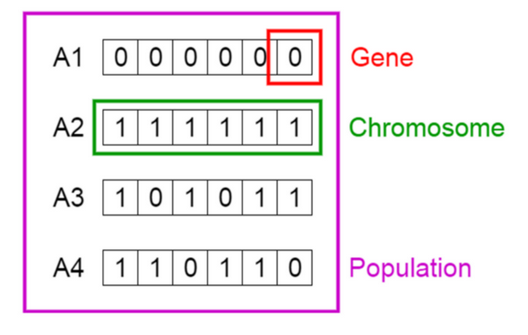
这些解决方案是人群中所谓的个体或染色体。它们是我们问题的可能解决方案。
信用图片:Vijini Mallawaarachchi
从图像中,解决方案3可以表示为单热矢量:c(1,0,1,0,1,1)。每个都1表示包含该变量的解决方案。在这种情况下:var1,var3,var5,var6。
虽然解决方案4是 c(1,1,0,1,1,0)。
载体中的每个位置都是基因。
GA过程及其运算符
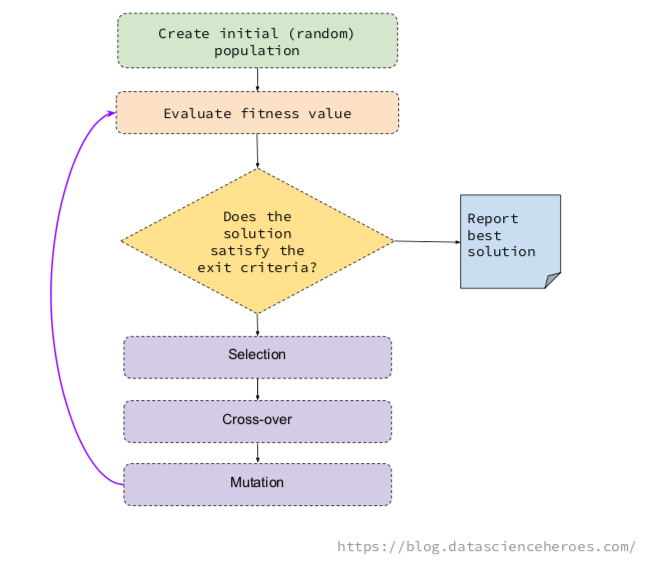
GA的基本思想是生成一些随机可能的解决方案(称为population),它们代表不同的变量,然后在迭代过程中组合最佳解决方案。
这种组合遵循基本的GA操作,即选择,变异和交叉。
选择:在一代人中挑选最适合的人(即提供最高ROC的解决方案)。
交叉:基于两种解决方案的基因创建两个新个体。这些孩子将出现在下一代。
突变:在个体中随机改变基因(即翻转
0到1)。
我们的想法是,每一代人都能找到更好的个体,比如更快的兔子。
我推荐Vijini Mallawaarachchi关于遗传算法如何工作的帖子。
这些基本操作允许算法通过以最大化目标的方式组合它们来改变可能的解决方案。
健身功能
例如,该目标最大化是与最大化ROC曲线下面积的解决方案保持一致。这被定义为适应度函数。
适应度函数采用可能的解决方案(或染色体,如果您想要听起来更复杂),并评估选择的有效性。
通常,适应度函数采用单热矢量c(1,1,0,0,0,0) 并且例如创建具有var1和的随机森林模型var2,并且返回适合度值(ROC)。
此代码中的适合度值计算为 ROC value/number of variables。通过这样做,该算法利用大量变量惩罚解。类似于Akaike信息标准或AIC 的想法。
R中的遗传算法!
我的目的是为您提供干净的代码,以便您可以了解它的工作原理,同时尝试新的方法,例如修改适应度函数。这是至关重要的一点。
要在您自己的数据集上使用,请确保data_x(数据框)和data_y(因子)与该custom_fitness功能兼容。
主图书馆GA由Luca Scrucca开发。请参阅 此处 以获取示例。
重要提示:以下代码不完整。克隆存储库以运行该示例。
#data_x:输入数据帧
#data_y:目标变量(因子)
#GA参数
param_nBits = NcoI位(数据_x)
col_names = colnames(data_x)
#执行GA
ga_GA_1 = ga(fitness = function(vars)custom_fitness(vars = vars,
data_x = data_x,
data_y = data_y,
p_sampling = 0.7),#自定义适应度函数
type = “ binary”,#optimization数据类型
crossover = gabin_uCrossover, #cross-over方法
精英 = 3,#最好Ñ逐张。传递给下一次迭代
pmutation = 0.03,#mutation rate prob
popSize = 50,#indivduals / solutions的数量
nBits = param_nBits,#变量总数
names = col_names,#variable name
run = 5,#max iter没有改进(停止标准)
maxiter = 50,#total runs或generation
monitor = plot,#在每次迭代时绘制结果
keepBest = TRUE,#最后保留最佳解决方案
parallel = T,#允许并行处理
seed = 84211 #用于再现性目的
)
#检查结果
摘要(ga_GA_1)
── 遗传 算法 ──────────────────
GA 设置:
Type = binary
人口 规模 = 50
数目 的 世代 = 50
精英主义 = 3
交叉 概率 = 0.8
突变 概率 = 0.03
GA 结果:
迭代次数 = 17
适应度 函数 值 = 0.2477393
解决方案 =
radius_mean texture_mean perimeter_mean area_mean smoothness_mean compactness_mean
[ 1,] 0 1 0 0 0 1
concavity_mean 凹 points_mean symmetry_mean fractal_dimension_mean ...
[ 1,] 0 0 0 0
symmetry_worst fractal_dimension_worst
[ 1,] 0 0
#以下行将返回最终和最佳解决方案的变量名称
best_vars_ga = col_names [ ga_GA_1 @ solution [ 1,] == 1 ]
#检查最佳解决方案的变量......
best_vars_ga
[ 1 ] “ texture_mean” “ compactness_mean” “ area_worst” “ concavity_worst”
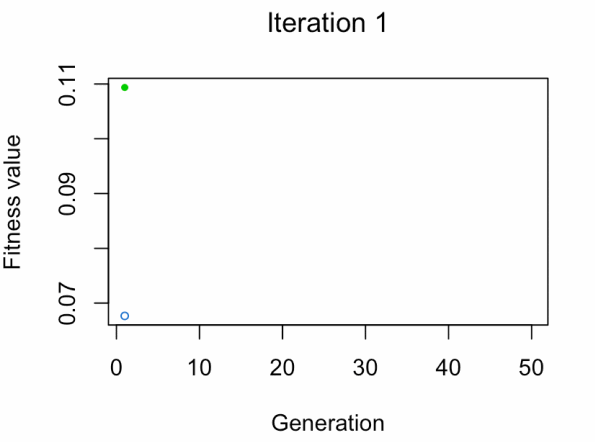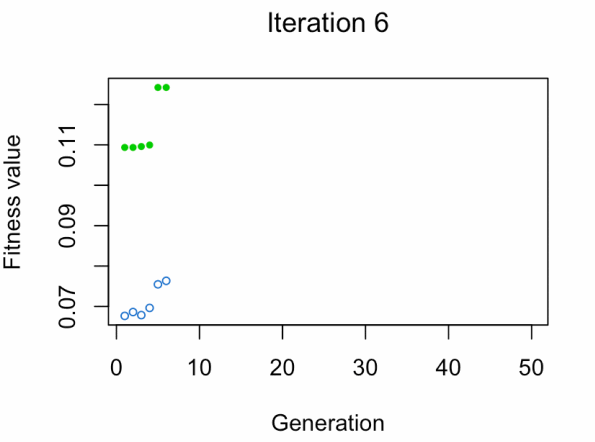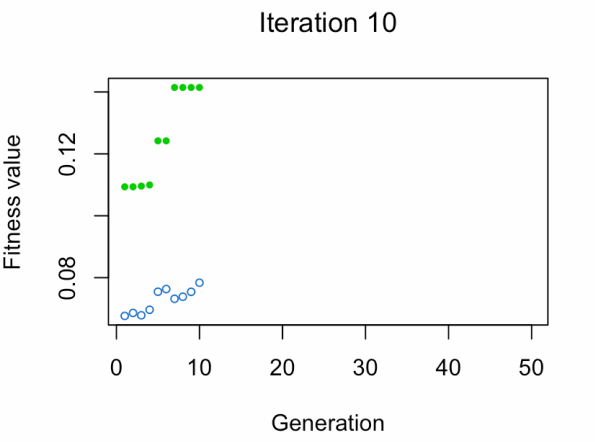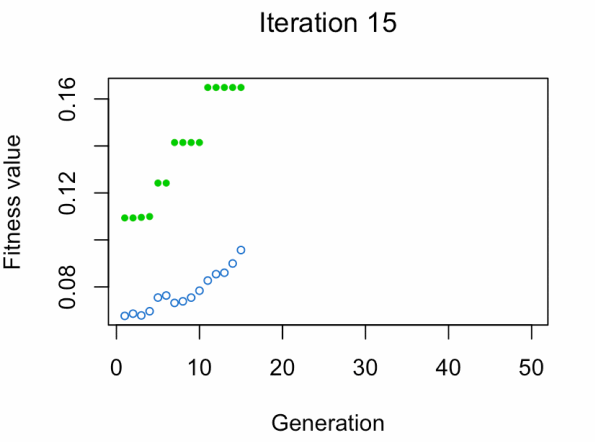
蓝点:人口健康平均值。
绿点:最佳健身价值。
注意:不要期望结果那么快。
现在我们根据最佳选择计算精度!
get_accuracy_metric(data_tr_sample = data_x,target = data_y,best_vars_ga)
[ 1 ] 0.9508279
精度约为95.08%,而ROC值接近0.95(ROC =适应值*变量数,检查适应度函数)。
分析结果
我不喜欢在没有切割点的情况下分析准确度(评分数据),但是与这个Kaggle帖子的结果进行比较是有用的。
上述帖子的作者使用基于5个变量的递归特征消除或RFE获得了类似的准确度结果,而我们的解决方案保留了四个变量。
自己动手吧
尝试新的适应度函数,有些解决方案仍然提供大量变量,可以尝试平方变量的数量。
要尝试的另一件事是获取ROC值的算法,甚至是更改度量标准的算法。
一些配置持续很长时间。在建模之前平衡类并使用p_sampling参数进行播放。采样技术可以对模型产生重大影响。有关详细信息,请查看模型性能帖子上的样本大小和类平衡。
如何改变变异率或精英主义?或尝试其他交叉方法?
增加以popSize同时测试更多可能的解决方案(按时间成本)。
随意分享任何见解或想法,以改善选择。
克隆存储库以运行该示例。
关于概念
遗传算法和深度学习之间存在平行关系,迭代和改进的概念随着时间的推移是相似的。
我添加了p_sampling参数以加快速度。它通常会实现其目标。类似于深度学习中使用的批处理概念。另一个并行是GA参数run和神经网络训练中的早期停止标准。
但最大的相似之处在于两种技术都来自于观察自然。在这两种情况下,人类观察神经网络和遗传学如何工作,并创建一个模仿其行为的简化数学模型。大自然有数百万年的进化,为什么不尝试模仿呢?