遗传算法是一种基于自然群体遗传进化机制的自适应全局优化概率搜索算法。
1、遗传算法的基本概念
1、遗传学基本概念与术语
**基因型(genotype):**遗传因子组合的模型
**表现型(phenotype):**由染色体决定形状的外部表现
**基因座(locus):**遗传基因在染色体中所占据的位置,同一基因座可能有的全部基因称为等位基因
**编码(coding):**表现型到基因型的映射
**解码(decoding):**从基因型到表现型的映射
2、遗传算法的构成要素
- 种群(popoulation),种群大小(pop_size),即个体数目
- 基因表达法——编码方式(encoding scheme;gene repressentation)
- 遗传算子(Genetic Operator):交叉(Crossover),变异(Mutation)
- 选择策略:一般为正比例选择
- 停止准则(Stopping Rule/Criterion),一般情况下停止准则为最大代数,即指定迭代次数
3、生物进化与遗传算法对应关系

4、遗传算法的基本操作
1、选择(selection)
- 根据各个个体的适应值,按照一定的规则,从第t代群体P(t)中选择出一些优良的个体遗传到下一代群体P(t+1)中
- 选择(复制)操作把当前种群的染色体按与适应值成正比例的概率复制到新的种群中
- 主要思想:适应值较高的染色体有较大的选择(复制)机会
- 实现1:“轮盘赌”选择(Roulette wheel selection)
“轮盘赌”选择步骤
- 将种群中所有染色体的适应值相加求总和,染色体适应值按其比例转化为选择概率Ps
- 产生一个在0与总和(也可为1)之间的随机数m
- 从种群中编号为1的染色体开始,将其适应值与后续染色体的适应值相加,直到累加和等于或大于m
数学表示:
设种群的规模为N,
是种群中的第i个染色体,
为第i个染色体的适应度值,
为种群中所有染色体适应度值之和,则染色体
被选的概率为
“轮盘赌”算法伪代码
- r = random(0,1),s = 0, i = 0;
- 如果s >= r,则转4
- s = s + p(x_i), i = i + 1,转2
- x_i 即为被选中的染色体,输出i
- 结束
特点
选择操作得到的新的群体称为交配池,交配池是当前代和下一代之间的中间群体,其规模为初始群体规模。选择操作的作用是提高群体的平均适应值,但同时也损失了群体的多样性。选择操作没有产生新的个体,群体中最好个体的适应值不会改变。
2、交叉(crossover)
- 将群体P(t)内的各个个体随机搭配成对,对每一个个体以某个概率 即交叉概率,交换它们之间的部分染色体
- 发生在两个染色体之间,这两个染色体被称为双亲的父代染色体,经杂交以后,产生两个具有双亲的部分基因的新的染色体,从而检测搜索空间中的新的点
- 选择(复制)操作每次作用在一个染色体上,而交叉每次作用在从交配池随机选取的两个个体上(交叉概率P_c),有放回选取交叉个体子代可能会重复和不防回是两回事
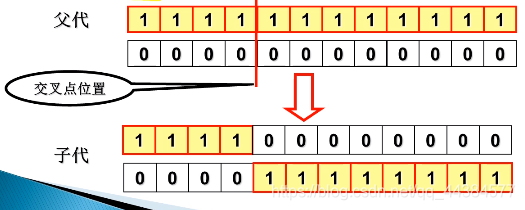
单点交叉(1-point crossover) - 在双亲的父代染色体中随机产生一个交叉点位置
- 在交叉点位置分离双亲染色体
- 互换交叉点位置右边的基因码产生两个子代染色体
- 交叉概率P_c一般范围为(60%,90%),平均约80%
- 例子:

- 当双亲染色体相同时,交叉操作不起作用,例如:假如交叉概率P_c=50%,则交配池中50%的染色体将进行交叉操作,余下的50%的染色体进行选择(复制)操作
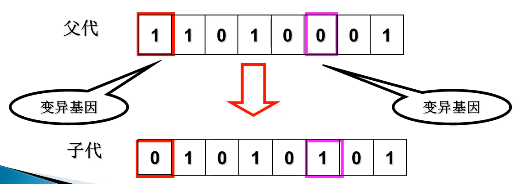
3、变异(mutation)
- 对群体P(t)中的每一个个体,以某一概率P_m即变异概率,改变某一个或一些基因座上基因值为其他的等位基因。
- 当以二进制编码时,变异的基因由0变成1,或由1变成0
- 变异概率P_m一般介于1/种群规模与1/染色体长度之间,平均约1~2%
- 例子:
- 比起选择和交叉,变异操作是GA中的次要操作,可增加群体的多样性。
群体无明显聚集时,减少编译,增加交叉
群体过于集中时,增加变异,减少交叉
4、编码(coding)
表现型空间到基因型空间是编码
基因型空间到表现型空间是解码
一般情况下,遗传算法的基因型空间是二进制编码
5、适应函数(Fitness Function)
. 群体中的每个染色体都需要计算适应值
. 适应函数一般由目标函数变换而成
. 适应函数的常见形式:
- 直接将目标函数转化为是适应值函数,若目标函数为最大化问题: 若目标函数为最小化问题:
- 界限构造法
. 目标函数为最大化问题 其中 为f(x)的最小估计值
. 目标函数为最小化问题
其中 为f(x)的最大估计值
6、停止准则
- 种群中个体的最大适应值超过预设值
- 种群中个体的最小适应值超过预设值
- 种群中个体的进化代数超过预设值
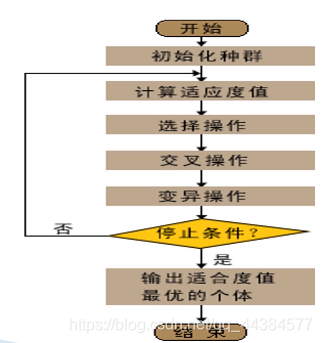
7、基本步骤
- 随机产生初始种群
- 计算种群中每个个体的适应度值,判断是否,满足停止条件,若不满足,则转第3步,否则转第6步
- 按由个体适应度值所决定的某个规则选择将进入下一代的个体
- 按交叉概率P_c进行交叉操作,产生新个体
- 按变异概率P_m进行变异操作,产生新个体
- 输出种群中适应度值最优的染色体作为问题的满意解
算法流程图
8、简单的遗传算法伪代码
begin
t = 0
初始化 P(t)
计算P(t)的适应度值
while(不满足停止准则) do
begin
t = t + 1
从P(t - 1)中选择P(t) //selection,这里是一个轮盘赌
重组P(t) //crossover and mutation
计算P(t)的适应度值
end
end
2、Holland的基本GA
最基本的遗传算法,只使用选择、交叉、变异三种基本算子。
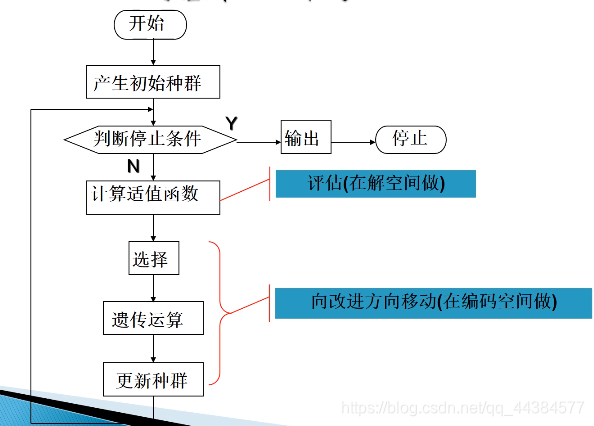
图中涉及到解空间和编码空间的转换,具体看下图: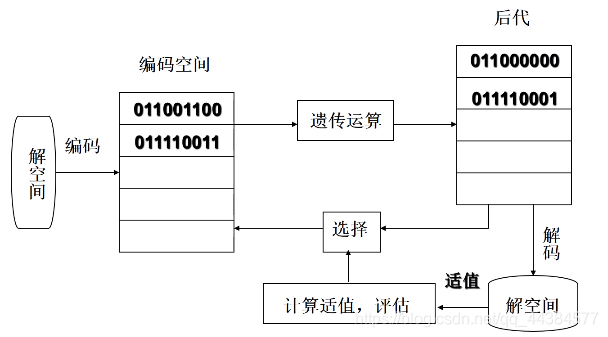
1、各步骤的实现
- 初始种群的产生
- 编码方法
- 适值函数
- 遗传运算
- 选择策略
- 停止准则
1、初始种群的产生
随机产生(依赖于编码方法);种群大小(依赖于计算机的算力)
例如:0,1编码:产生x_i,x_i > 0.5, y_i = 1;x_i < 0.5, y_i=0
2、编码方法——二进制编码
用0,1字符串表达。例如:0110010适用以下三种情况。
- 背包问题:1:背,0:不背
- 实优化:精度高时编码长,一般不采用此法而用实值函数
- 指派问题
二级制编码时的位数控制
直接给出实例:变量x的定义域为[-2,5],要求其精度为10^(-6),则我们需要将[-2,5]分成至少7,000,000个等长区间,而每个区间用一个二进制串表示。于是串长至少等于23.这是因为: 因此,其他精度也可以按照此法进行计算。
3、适值函数——根据目标函数
用适值函数F(x)标定目标函数f(x)
采用-minf(x)或maxf(x)
4、遗传运算——交叉和变异
- 交叉(crossover)
单切点交叉:随机产生一个断点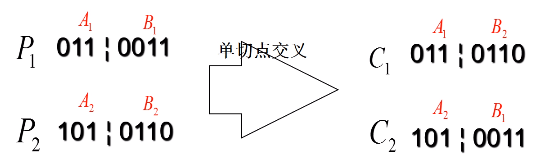
双切点交叉(交换中间段):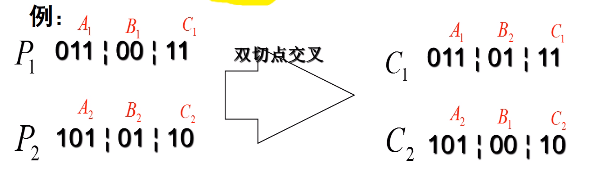
- 变异(mutation):按变异概率P_m任选若干位基因改变位值0变1 或 1变0,P_m一般在5%以下
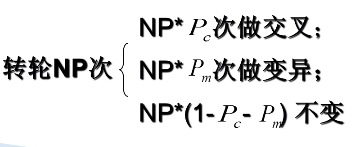
5、选择策略
正比选择,转化为概率选择:
NP为种群大小,number of population
得到选择概率之后,采用轮盘赌法进行选择。
6、停止准则
- 最大迭代次数(NG-Number of max Generation)
- 相邻两次适应度值的差
2、计算实例
1、例子:
,NP=5
-
编码为五位的0,1编码,设编码长度L,取决于
C为编码精度,若要求编码精度为1,则由C<=1可推得L>=5 -
步骤:1、产生初始种群,令NG=10(执行最大代数),t=0
2、判断停止准则
3、计算适值
4、用轮盘赌法正比选择 -
计算生成的列表:
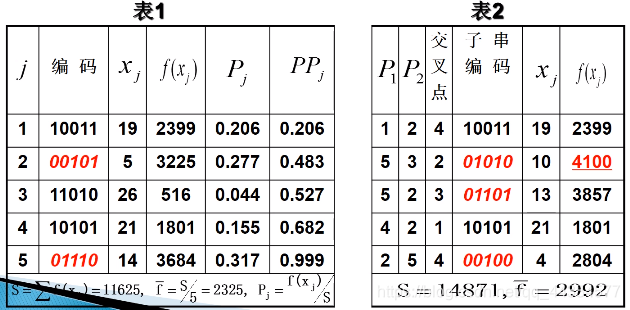
-
观察结果
1、整个种群在改善,平均适应度值增加了
2、模板S_1 0较好,而S_2 1较差
3、S_1类的增多一个,S_2类的减少一个 -
做交叉时双亲的选择方法:
1、随机选:产生(0,1)之间的随机数,然后
2、比例选:产生(0,1)之间的随机数,当 ,选择个体i
3、父亲优选,母亲随机选:选P_2,
2、其他编码方法:
1、顺序编码:又称自然数编码,用1到N的自然数的不同顺序来编码,该编码不允许重复,即
且
该法的适应范围很广:指派、旅行商问题、、单机调度问题
2、实数编码:
特点:方便,运算简单,但反映不出基因的特征
3、整数编码:和自然数编码差不多,只是编码可以重复
3、遗传运算中的问题
在顺序编码的过程中会遇见不合法的编码,应对的策略有两种:拒绝或修复

采用修复策略,进行修复
- 1、顺序编码的合法性修复
交叉修复策略:部分映射交叉(Partially Mapped Crossover,PMX)、顺序交叉(Order Crossover,OX)、循环交叉(Cycle Crossover,CX)
变异的修复策略:换位变异(最常用)、移位变异 - 2、实数编码的合法性修复
交叉:单切点交叉、双切点交叉、凸组合交叉
