概述
并行运算:
并行计算或称平行计算是相对于串行计算来说的。它是一种一次可执行多个指令的算法,目的是提高计算速度,及通过扩大问题求解规模,解决大型而复杂的计算问题。所谓并行计算可分为时间上的并行和空间上的并行。 时间上的并行就是指流水线技术,而空间上的并行则是指用多个处理器并发的执行计算。
并行计算(Parallel Computing)是指同时使用多种计算资源解决计算问题的过程,是提高计算机系统计算速度和处理能力的一种有效手段。它的基本思想是用多个处理器来协同求解同一问题,即将被求解的问题分解成若干个部分,各部分均由一个独立的处理机来并行计算。并行计算系统既可以是专门设计的、含有多个处理器的超级计算机,也可以是以某种方式互连的若干台的独立计算机构成的集群。通过并行计算集群完成数据的处理,再将处理的结果返回给用户。
为利用并行计算,通常计算问题表现为以下特征:
(1)将工作分离成离散部分,有助于同时解决;
(2)随时并及时地执行多个程序指令;
(3)多计算资源下解决问题的耗时要少于单个计算资源下的耗时。
OpenMp:
OpenMP是由OpenMP Architecture Review Board牵头提出的,并已被广泛接受,用于共享内存并行系统的多处理器程序设计的一套指导性编译处理方案(Compiler Directive)。OpenMP支持的编程语言包括C、C++和Fortran;而支持OpenMp的编译器包括Sun Compiler,GNU Compiler和Intel Compiler等。OpenMp提供了对并行算法的高层的抽象描述,程序员通过在源代码中加入专用的pragma来指明自己的意图,由此编译器可以自动将程序进行并行化,并在必要之处加入同步互斥以及通信。当选择忽略这些pragma,或者编译器不支持OpenMp时,程序又可退化为通常的程序(一般为串行),代码仍然可以正常运作,只是不能利用多线程来加速程序执行。
进化算法:
进化算法,或称“演化算法” (evolutionary algorithms, EAS) 是一个“算法簇”,尽管它有很多的变化,有不同的遗传基因表达方式,不同的交叉和变异算子,特殊算子的引用,以及不同的再生和选择方法,但它们产生的灵感都来自于大自然的生物进化。与传统的基于微积分的方法和穷举法等优化算法相比,进化计算是一种成熟的具有高鲁棒性和广泛适用性的全局优化方法,具有自组织、自适应、自学习的特性,能够不受问题性质的限制,有效地处理传统优化算法难以解决的复杂问题。
本报告主要使用OpenMp解决基于多智能体进化算法的并行问题。在本实验中,目标函数的维度设定为8000,在串行条件下,在本地计算机中的运行时间为21.454s秒,在加入适当的并行方法之后运行时间为7.192s,运算速度为原来的2.84倍。
算法描述
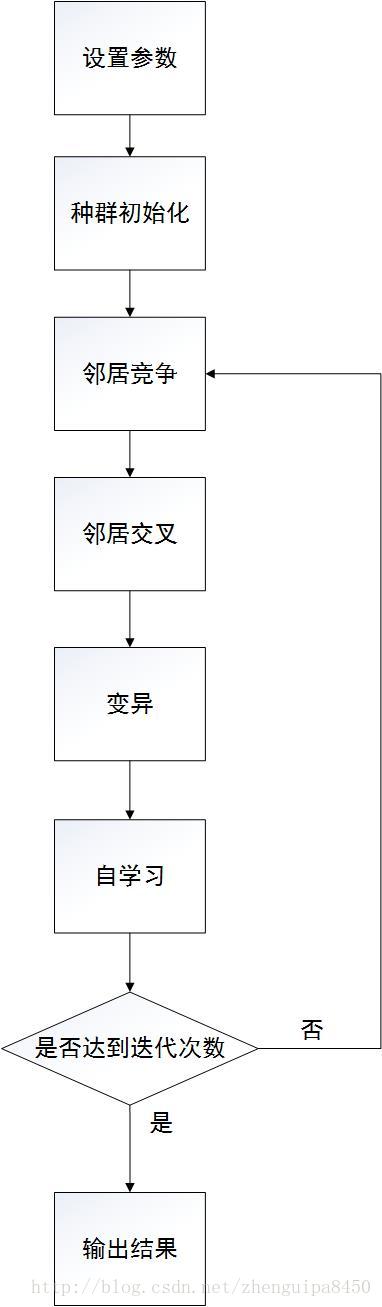
本实验仿真的是基于多智能体的进化算法,其算法流程包括以下步骤:参数设定,种群初始化,邻居竞争,邻居交叉,变异,自学习,五个步骤。其中我们将变量
本实验的优化目标函数为:
其中变量取值范围
其中
并行设计
1、进化算法中国适应度函数的计算次数较多,且可以进行并行化设计,所以在适应度函数的计算中加入求和的并行运算:
void Fitness(LL &P) //计算适应度以及能量
{
P.fitness = 0.0;
double u[x_num];
double a = 5.0, k = 100.0, m = 4.0, b1 = 0.0;
int i;
#pragma omp parallel for reduction(+:b1)
for (i = 0; i < x_num; i++)
{
if (P.x[i] >= -a && P.x[i] <= a)
{
u[i] = 0;
}
else if (P.x[i] > a)
{
u[i] = k * pow((P.x[i] - a), m);
}
else if (P.x[i] < -a)
{
u[i] = k * pow(-P.x[i] - a, m);
}
b1 += u[i];
}
double a1 = 0;
#pragma omp parallel for reduction(+:a1)
for (i = 0; i < x_num - 1; i++)
{
a1 += (P.x[i] - 1) * (1 + 10 * pow(sin(PI * P.x[i + 1] * 3), 2)) * (P.x[i] - 1);
}
P.fitness = 0.1 * (pow(sin(3 * PI * P.x[0]), 2) + a1 + (pow(sin(P.x[x_num - 1] * 2 * PI), 2)) + 1) * pow(P.x[x_num - 1], 2) + b1;
P.energy = -P.fitness;
}
2、始化过程中,每个智能体之间不影响,因此加入并行运算:
void Init_L(LL P[Lsize][Lsize]) //初始化函数
{
int i, j, k;
#pragma omp parallel private(i, j, k)
#pragma omp for schedule(dynamic)
for (i = 0; i < Lsize; i++)
{
for (j = 0; j < Lsize; j++)
{
for (k = 0; k < x_num; k++)
{
P[i][j].x[k] = rand() / (RAND_MAX + 1.0) * (upper - lower) - (upper - lower) / 2.0;
}
Fitness(P[i][j]);
}
}
}
3、在运行过程中多次用到的选择智能体最优邻居函数,且不互相影响,因此也将其并行设计:
LL Nmax(LL L[Lsize][Lsize], int i, int j) //找到邻居中的最大值 其中的i,j是需要P的坐标
{
LL max1[5];
max1[1] = (i == 0) ? L[Lsize - 1][j] : L[i - 1][j];
max1[2] = (j == 0) ? L[i][Lsize - 1] : L[i][j - 1];
max1[3] = (i == Lsize - 1) ? L[0][j] : L[i + 1][j];
max1[4] = (j == Lsize - 1) ? L[i][0] : L[i][j + 1];
max1[0] = max1[1];
#pragma omp parallel for
for (int k = 2; k < 5; k++)
{
if (max1[0].energy <= max1[k].energy)
max1[0] = max1[k];
}
return max1[0];
}
4、在邻居互相竞争函数中要对基因中的每个元素进行操作,因此也将其并行设计:
#pragma omp parallel for
for (int i = 0; i < x_num; i++)
{
a = B.x[i] + (rand() / (RAND_MAX + 1.0) * 2 - 1) * (B.x[i] - P1.x[i]);
if (a < lower)
{
P1.x[i] = lower;
continue;
}
else if (a > upper)
{
P1.x[i] = upper;
continue;
}
P1.x[i] = a;
}
}
5、在变异操作中也需要对基因中的每个元素进行操作,对其进行并行设计:
void Mutation(LL &P, int t) //变异作用
{
#pragma omp parallel for
for (int i = 0; i < x_num; i++)
{
if (rand() / (RAND_MAX + 1.0) < 1 / x_num)
{
continue;
}
else
{
P.x[i] += rand() / (RAND_MAX + 1.0) / t * 2 - 1.0 / (t + 0.0);
P.x[i] = P.x[i] < lower ? lower : P.x[i];
P.x[i] = P.x[i] > upper ? upper : P.x[i];
}
}
Fitness(P);
}
6、在自学习函数中,需要对最优个体建立子网络,其中每个网格中的智能体也不互相影响,因此对其进行并行处理:
int i, j, k;
#pragma omp parallel private(i,j,k)
#pragma omp for schedule(dynamic)
for (i = 0; i < sLsize; i++) //首先生成这个自学习举证
{
for (j = 0; j < sLsize; j++)
{
if (i == 0 || j == 0)
{
sL[i][j] = P;
}
else
{
for (k = 0; k < x_num; k++)
{
double Temp;
Temp = rand() / (RAND_MAX + 1.0) * sR * 2 - sR + 1;
if (P.x[k] * Temp < lower)
{
sL[i][j].x[k] = lower;
continue;
}
else if (P.x[k] * Temp > upper)
{
sL[i][j].x[k] = upper;
continue;
}
sL[i][j].x[k] = P.x[k] * Temp;
}
}
Fitness(sL[i][j]);
if (sL[i][j].energy > sBest.energy)
sBest = sL[i][j];
}
}
实验结果
分别在串行和并行两种条件下进行十次实验,其结果为:

由结果可知并行程序平均运行时间为7.192s,串行程序平均运行时间为20.454s,是并行程序的2.843倍。