遗传算法(Genetic Algorithm,GA)是一种基于生物进化过程的优化算法,通过模拟自然界的遗传和进化机制,寻找问题的最优解。在解决复杂和多变量的优化问题中,遗传算法表现出良好的鲁棒性和全局搜索能力。
遗传算法的流程包括以下步骤:
-
初始化种群:创建由个体组成的初始种群。每个个体表示问题的一个潜在解,并用染色体(Chromosome)表示。
-
评估适应度:通过适应度函数评估种群中每个个体的适应度,即个体解的优劣程度。适应度函数根据问题不同而定,可以是目标函数值的最大化或最小化。
-
选择操作:根据适应度值,选择一部分适应度较高的个体作为“父代”,用于产生下一代。高适应度个体被选择的概率较高,以保留良好特性。
-
交叉操作:从父代中选择两个个体,通过交叉操作生成新的个体。交叉操作模拟了基因在生物繁殖过程中的交叉。
-
变异操作:对新生成的个体进行变异,以增加种群的多样性。变异操作模拟了基因突变过程。
-
更新种群:用新生成的个体替换原有的个体,形成下一代种群。
-
终止条件:重复进行步骤2到步骤6,直到满足终止条件,如达到最大迭代次数或达到特定的目标解。
遗传算法的优点包括:
-
全局搜索能力:遗传算法通过维护一个多样性的种群,能够在解空间中进行全局搜索,找到更优解。
-
鲁棒性:遗传算法不依赖于问题的具体形式,适用于多种优化问题。它可以处理连续、离散或混合型的变量,并且对问题的约束灵活适应。
-
并行计算能力:由于遗传算法是通过对个体进行并行评估和操作,它能够有效利用并行计算能力,加速优化过程。
然而,遗传算法也存在一些缺点:
-
参数设置:遗传算法的性能表现高度依赖于参数的设置,如种群大小、交叉率、变异率等。不同的问题可能需要不同的参数设置。
-
收敛速度:由于遗传算法通过随机搜索进行优化,它的收敛速度相对较慢。对于复杂问题,可能需要较长的时间才能找到较好的解。
-
问题依赖性:尽管遗传算法适用于多种问题,但对于特定的问题,可能存在更适合的优化算法。
遗传算法是一种强大的优化算法,能够解决复杂的优化问题,并具有全局搜索能力和鲁棒性。但它也有一些限制,对参数设置敏感,收敛速度较慢。在实践中,可以根据具体问题的特点和限制,选择合适的优化算法进行求解。
早上的时候遇上一个问题就是想要能够自动化地求解N个地点遍历最优的路径规划,这时候想到了使用遗传算法GA,GA可以说是比较早比较经典的算法了,上面对其进行了简单的总结和回顾,这里,我们来看下具体的实现。
为了方便说明,这里简化问题,数据都是随机生成的,当然了你也可以实际使用地图获取真实的城市坐标,都是可以的:
# 城市坐标
city_pos_list = np.random.rand(config.city_num, config.pos_dimension)
print("city_pos_list: ", city_pos_list)接下来需要构建计算城市两两之间的距离,形成距离矩阵,如下所示:
def build_dist_mat(data):
"""
构建距离矩阵
"""
n = config.city_num
dist_mat = np.zeros([n, n])
for i in range(n):
for j in range(i + 1, n):
d = data[i, :] - data[j, :]
dist_mat[i, j] = np.dot(d, d)
dist_mat[j, i] = dist_mat[i, j]
return dist_mat我们这里设定城市数量为5,看下实例结果输出:
city_pos_list:
[[0.4857694 0.37717288]
[0.12982822 0.92253033]
[0.63096373 0.89184198]
[0.70368269 0.59460617]
[0.8681248 0.58574649]]
city_dist_mat:
[0.0, 0.4241088699265403, 0.2859656753224421, 0.09476343738540502, 0.18969860731199]
[0.4241088699265403, 0.0, 0.25207857105384973, 0.43684320650858754, 0.6585051993116404]
[0.2859656753224421, 0.25207857105384973, 0.0, 0.09363717469660143, 0.1499398246120906]
[0.09476343738540502, 0.43684320650858754, 0.09363717469660143, 0.0, 0.02711970301160461]
[0.18969860731199, 0.6585051993116404, 0.1499398246120906, 0.02711970301160461, 0.0]GA算法的实现可以直接参考开源社区即可,网上有很多非常好的讲解,这里我给出自己的实例实现,如下所示:
class Individual:
"""
个体类
"""
def __init__(self, genes=None):
# 随机生成序列
if genes is None:
genes = [i for i in range(gene_len)]
random.shuffle(genes)
self.genes = genes
self.fitness = self.evaluate_fitness()
def evaluate_fitness(self):
# 计算个体适应度
fitness = 0.0
for i in range(gene_len - 1):
# 起始城市和目标城市
from_idx = self.genes[i]
to_idx = self.genes[i + 1]
fitness += city_dist_mat[from_idx, to_idx]
# 连接首尾
fitness += city_dist_mat[self.genes[-1], self.genes[0]]
return fitness
class Ga:
def __init__(self, input_):
global city_dist_mat
city_dist_mat = input_
self.best = None # 每一代的最佳个体
self.individual_list = [] # 每一代的个体列表
self.result_list = [] # 每一代对应的解
self.fitness_list = [] # 每一代对应的适应度
def cross(self):
new_gen = []
random.shuffle(self.individual_list)
for i in range(0, individual_num - 1, 2):
# 父代基因
genes1 = copy_list(self.individual_list[i].genes)
genes2 = copy_list(self.individual_list[i + 1].genes)
index1 = random.randint(0, gene_len - 2)
index2 = random.randint(index1, gene_len - 1)
pos1_recorder = {value: idx for idx, value in enumerate(genes1)}
pos2_recorder = {value: idx for idx, value in enumerate(genes2)}
# 交叉
for j in range(index1, index2):
value1, value2 = genes1[j], genes2[j]
pos1, pos2 = pos1_recorder[value2], pos2_recorder[value1]
genes1[j], genes1[pos1] = genes1[pos1], genes1[j]
genes2[j], genes2[pos2] = genes2[pos2], genes2[j]
pos1_recorder[value1], pos1_recorder[value2] = pos1, j
pos2_recorder[value1], pos2_recorder[value2] = j, pos2
new_gen.append(Individual(genes1))
new_gen.append(Individual(genes2))
return new_gen
def mutate(self, new_gen):
for individual in new_gen:
if random.random() < mutate_prob:
# 翻转切片
old_genes = copy_list(individual.genes)
index1 = random.randint(0, gene_len - 2)
index2 = random.randint(index1, gene_len - 1)
genes_mutate = old_genes[index1:index2]
genes_mutate.reverse()
individual.genes = old_genes[:index1] + genes_mutate + old_genes[index2:]
# 两代合并
self.individual_list += new_gen
def select(self):
# 筛选
group_num = 10 # 小组数
group_size = 10 # 每小组人数
group_winner = individual_num // group_num # 每小组获胜人数
winners = [] # 锦标赛结果
for i in range(group_num):
group = []
for j in range(group_size):
# 随机组成小组
player = random.choice(self.individual_list)
player = Individual(player.genes)
group.append(player)
group = Ga.rank(group)
# 取出获胜者
winners += group[:group_winner]
self.individual_list = winners
@staticmethod
def rank(group):
# 冒泡排序
for i in range(1, len(group)):
for j in range(0, len(group) - i):
if group[j].fitness > group[j + 1].fitness:
group[j], group[j + 1] = group[j + 1], group[j]
return group
def next_gen(self):
# 交叉
new_gen = self.cross()
# 变异
self.mutate(new_gen)
# 选择
self.select()
# 获得这一代的结果
for individual in self.individual_list:
if individual.fitness < self.best.fitness:
self.best = individual
def train(self):
# 初代种群
self.individual_list = [Individual() for _ in range(individual_num)]
self.best = self.individual_list[0]
# 迭代
for i in range(gen_num):
self.next_gen()
# 连接首尾
result = copy_list(self.best.genes)
result.append(result[0])
self.result_list.append(result)
self.fitness_list.append(self.best.fitness)
return self.result_list, self.fitness_list
接下来就可以喂入数据执行算法计算了:
# 遗传算法运行
ga = Ga(city_dist_mat)
result_list, fitness_list = ga.train()为了直观呈现效果,这里对其结果进行了可视化,如下所示:
【5个城市】

【10个城市】
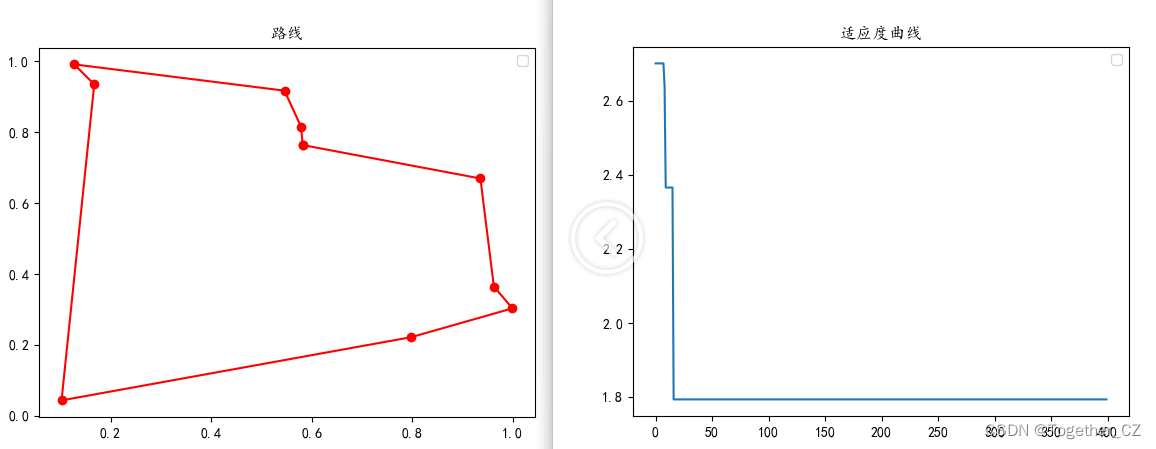
【15个城市】
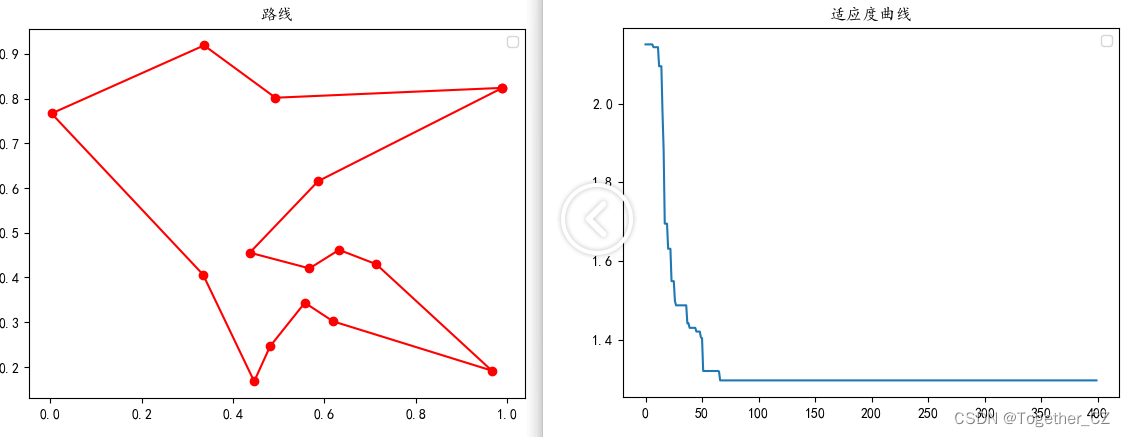
【20个城市】
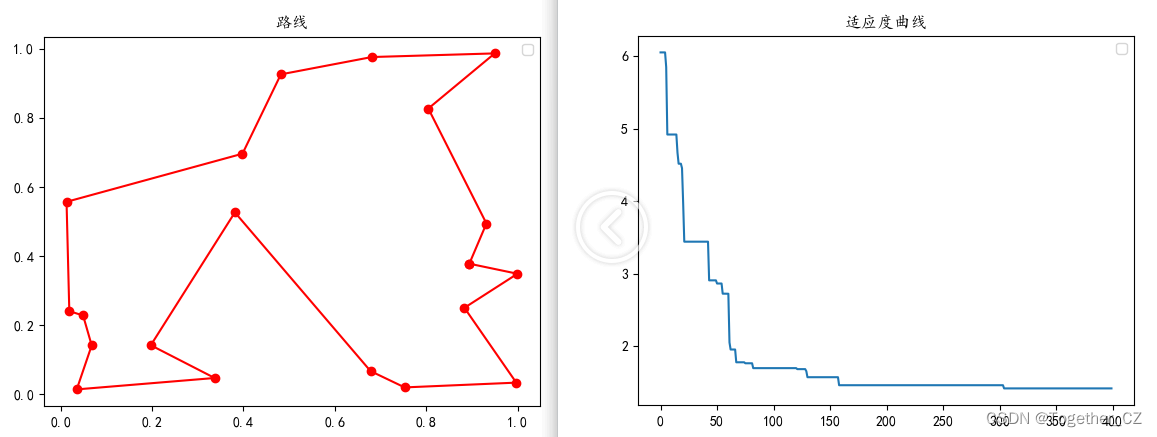
【30个城市】
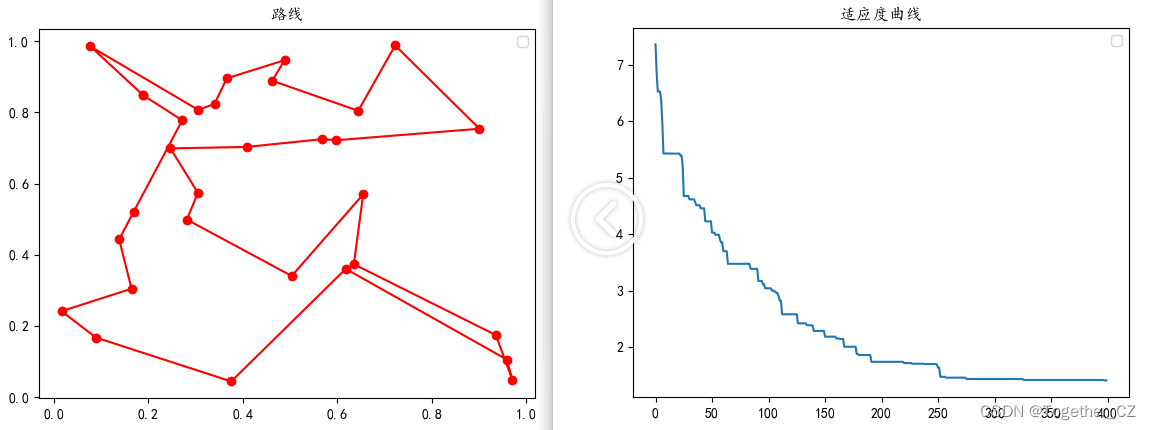
【50个城市】
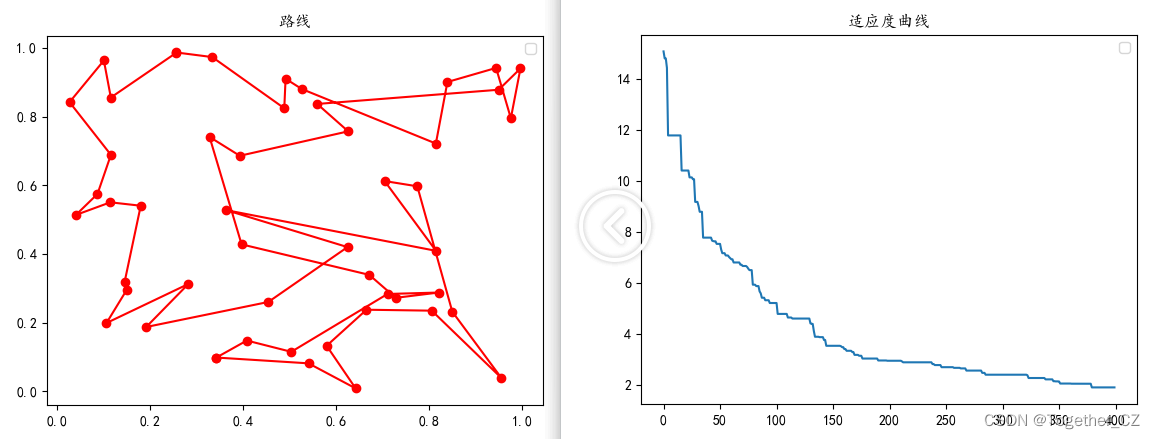
【100个城市】
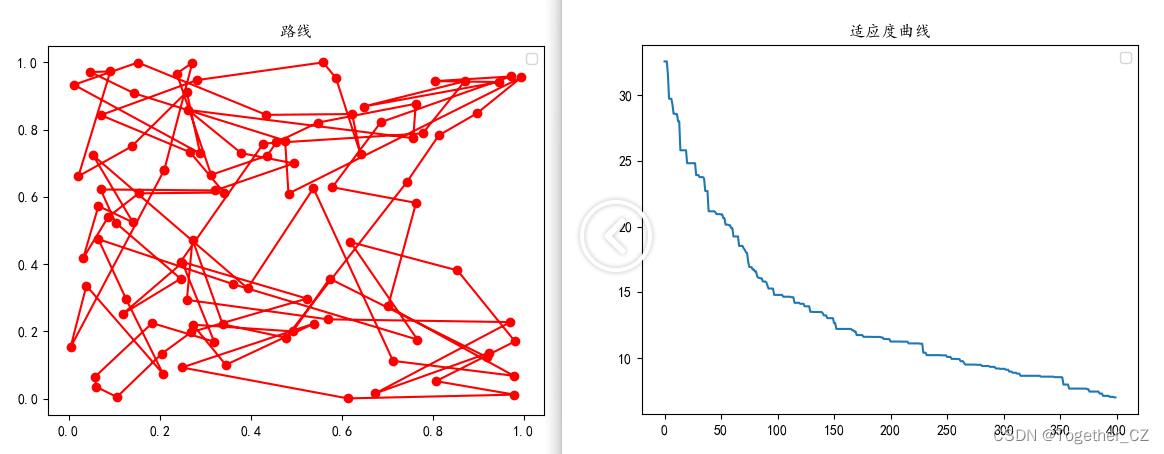
随着城市数量的增多,路线显得比较混乱,不过还是能看出来轮廓的,感兴趣的话都可以自行动手尝试一下。