版权声明:版权归零零天所有,若有转载请注明出处。 https://blog.csdn.net/qq_39188039/article/details/86620967
FileChannel
代码:
/*
* 这个方法用来测试FileChannel,FileChannel只能通过FileInputStream,FileOutputStream和
* RandomAccessFile的getChannel()方法得到。
* FileChannel在文件操作上,性能上没什么差别。读或写都是通过缓冲区来操作。此外还提供了一些额外方法,比如可以指定从文件的某个位置开始读或写
* 如果FileChannel是通过FileInputStream得到,那他只能读文件,不能写文件。
*/
@Test
public void test02() throws Exception{
FileChannel fc=new FileInputStream(new File("test02.txt")).getChannel();
ByteBuffer buffer=ByteBuffer.allocate(1);
fc.position(4);
fc.read(buffer);
System.out.println(new String(buffer.array()));
fc.close();
}
@Test
public void test03() throws Exception{
FileChannel fc=new FileOutputStream(new File("test03.txt")).getChannel();
fc.write(ByteBuffer.wrap("test03".getBytes()));
fc.close();
}
/*
* 通过RandomAccessFile得到的FileChannel,既可以对指定文件读也可以写。并且都可以指定开始读或写的位置
*/
@Test
public void test04() throws Exception{
FileChannel fc=new RandomAccessFile(new File("test03.txt"), "rw").getChannel();
ByteBuffer readBuf=ByteBuffer.allocate(1);
fc.position(2);
fc.read(readBuf);
System.out.println("读到的是:"+new String(readBuf.array()));
fc.write(ByteBuffer.wrap("new data".getBytes()));
fc.close();
}
散列表
概述
若关键字为k,则其值存放在f(k)的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系f为散列函数,按这个思想建立的表为散列表。
对不同的关键字可能得到同一散列地址,即k1≠k2,而f(k1)=f(k2),这种现象称为碰撞(英语:Collision)。具有相同函数值的关键字对该散列函数来说称做同义词。综上所述,根据散列函数f(k)和处理碰撞的方法将一组关键字映射到一个有限的连续的地址集(区间)上,并以关键字在地址集中的"像"作为记录在表中的存储位置,这种表便称为散列表,这一映射过程称为散列造表或散列,所得的存储位置称散列地址。
若对于关键字集合中的任一个关键字,经散列函数映象到地址集合中任何一个地址的概率是相等的,则称此类散列函数为均匀散列函数(Uniform Hash function),这就是使关键字经过散列函数得到一个"随机的地址",从而减少碰撞。
散列函数
散列函数是这样的函数,即无论你给它什么数据,它都还你一个数字。
如果用专业术语来表达的话,我们会说,散列函数“将输入映射到数字”。你可能认为散列函数输出的数字没什么规律,但其实散列函数必须满足一些要求。


DatagramChannel
代码:
/*
* 这个方法是用来测试DatagramChannel的客户端,用于实现UDP通信。本方法是发送数据方
*/
@Test
public void test01_Client() throws Exception{
DatagramChannel dc=DatagramChannel.open();
dc.send(ByteBuffer.wrap("hello".getBytes()),new InetSocketAddress("127.0.0.1",7777));
}
/*
* 这个方法是用来做UDP通信的服务端的,用于接收数据。
*/
@Test
public void test01_Server() throws Exception{
DatagramChannel dc=DatagramChannel.open();
dc.socket().bind(new InetSocketAddress(7777));
ByteBuffer buffer=ByteBuffer.allocate(5);
dc.receive(buffer);
System.out.println(new String(buffer.array()));
}
Blocking Queue

ArrayBlockingQueue

LinkedBlokingQueue

PriorityBlokingQueue


SynchronousQueue

BlockingDeque

LinkedBlockingDeque

ConcurrentMap

测试代码
/**
* 这个类是用来测试ConcurrentHashMap的
* 从JDK1.2,有了hashmap,但是hashmap并不是线程安全的。所以当时为了解决map的线程安全问题,因此多线程操作时需要格外小心。
* 为此创造了Hashtable,Hashtable里每个方法都加了synchronized,这样做,虽然解决的线程安全问题,但是效率非常低。
*
* 在JDK1.5版本,Doug Lea给我们带来的concurrent包,其中ConcurrentMap就是其中线程安全map,并且效率要比hashtable要高很多。
* 实现原理:
* 他引入了"分段锁"的概念,可以理解为把一个大的Map拆分成N个小的HashTable,根据Key的hashcode来决定把这个key放在哪个hashtable中。
* 在看源代码的时候,会看到一个segments,这个就相当于分拆的hashtable。对于ConcurrentMap,创建时默认是有16个segments。
* 那有了这个机制之后,如何就能提高并发性能呢?
* 打个比方:
* 创建一个ConcurrentMap=》存储16个key=》恰巧这个16Key值分布在16个segment(hashtable)中=》如果都是读操作,不加锁,如果是写操作
* 即操作某一个key值,就只会锁这个key对应的segment,而其他15个segment不会锁上,即不会锁住整表=》从而提高了并发性能。
* 分为N个Segment,效率会提升N倍,默认是提升16倍
* @author ysq
*
*/
public class ConcurrentHashMapDemo {
public static void main(String[] args) {
//可以进入断点,看到16个segment
cmap.put("key", "value");
cmap.get("key");
}
}
ConcurrentNavigableMap

CountDownLatch 闭锁

代码:
public class CountDownLatchDemo {
/*
* CountDownLatch,闭锁,线程递减锁
* 在构造方法里,需要传进一个整数值,这个值是计数器的初始值。每调用一次,计数器减1。
* 闭锁的应用场景,认为的来控制阻塞。主要是通过await()和countDown()这两个方法来配合
* await()会产生阻塞,当计数器减为0的时候,阻塞放开。所以需要执行countDown()方法
*/
@Test
public void test01() throws InterruptedException{
CountDownLatch cdl=new CountDownLatch(1);
cdl.countDown();
cdl.await();
System.out.println("代码执行到了这里");
}
/*
* 用闭锁实现做饭流程
* 1.先买锅 线程一
* 买菜 线程二
* 2.开始做法
*/
@Test
public void test02() throws InterruptedException{
CountDownLatch cdl=new CountDownLatch(2);
new Thread(new BuyGuo(cdl)).start();
new Thread(new BuyCai(cdl)).start();
cdl.await();
System.out.println("做饭");
}
}
class BuyGuo implements Runnable{
private CountDownLatch cdl=null;
public BuyGuo(CountDownLatch cdl) {
this.cdl=cdl;
}
public void run() {
System.out.println("线程一:把锅买过来了");
cdl.countDown();
}
}
class BuyCai implements Runnable{
private CountDownLatch cdl=null;
public BuyCai(CountDownLatch cdl) {
this.cdl=cdl;
}
public void run() {
System.out.println("线程二:把菜买回来了");
cdl.countDown();
}
}
CyclicBarrier 栅栏

Exchanger交换机

Semaphore信号量

ExecutorService 线程池
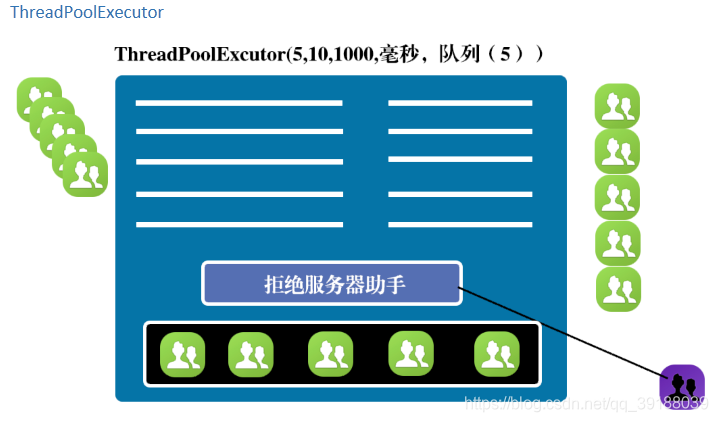
代码:
public class ExcutorServiceDemo {
public void testThreadPoolExecutor(){
//corePoolSize 核心线程数量
//maximumPoolSize 最大线程数量
//keepAliveTime 存活时间
//时间单位
//队列,队列可以是有界队列,也可以是无界队列。如果是无界队列的话(LinkedBlokingQueue),Maxpoolsize就无意义了,这一般应对与瞬时高突发请求情况。
//拒绝服务器助手
ExecutorService ex=new ThreadPoolExecutor(5, 10, 1000, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<Runnable>(5),
new RejectedExecutionHandler() {
//r代表任务
//executor代表当前的线程池对象,即ex
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// TODO Auto-generated method stub
}
});
}
/*
* newCachedThreadPool。这个线程池的特点:适用于短时任务线程,来一任务开启一个线程,如果一个线程长时间不用,则被清除
* newFixedThreadPool(int size) 特点:corePool 和 MaxPool的数量相等,即池子里都是核心线程,此外,队列是无界的。一般情况下,常用的是这个
* newSingleThreadExecutor 只包含一个线程的线程池。
*
*/
public void testExcutor(){
ExecutorService ex1=Executors.newCachedThreadPool();
ExecutorService ex2=Executors.newFixedThreadPool(10);
ExecutorService ex3=Executors.newSingleThreadExecutor();
}
}
execute方法:
@Test
public void testExec(){
ExecutorService service=new ThreadPoolExecutor(2, 4, 10000, TimeUnit.MILLISECONDS,new ArrayBlockingQueue<Runnable>(2),
new RejectedExecutionHandler() {
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println("有任务被拒绝");
}
});
service.execute(new ExecRunner());
service.execute(new ExecRunner());
service.execute(new ExecRunner());
service.execute(new ExecRunner());
service.execute(new ExecRunner());
service.execute(new ExecRunner());
service.execute(new ExecRunner());
service.execute(new ExecRunner());
service.execute(new ExecRunner());
while(true);
}
class ExecRunner implements Runnable{
public void run() {
System.out.println(Thread.currentThread().getId()+"号线程正在工作");
try {
Thread.sleep(Integer.MAX_VALUE);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
submit方法:
/*
* 这个方法是用来测试submit方法
* 这个方法会得到future对象,通过future.get(),如果返回值是null,证明线程的run方法跑完
*/
@Test
public void testSubmit() throws InterruptedException, ExecutionException{
ExecutorService service=Executors.newFixedThreadPool(10);
Future future=service.submit(new SubmitRunner());
if(future.get()==null){
System.out.println("线程已工作完");
}
}
class SubmitRunner implements Runnable{
public void run() {
System.out.println("线程正在工作……");
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
Callable
public class CallableDemo {
@Test
public void testCallable() throws InterruptedException, ExecutionException{
ExecutorService service=Executors.newFixedThreadPool(10);
Future future=service.submit(new CallableExecRunner());
System.out.println(future.get());
while(true);
}
}
/*
* callable接口是jdk1.5版本引进来的几口,任何类实现这个接口,都是一个线程类
* 改进的地方:
* 1.引入了泛型机制
* 2.call()相当于run()方法,有返回值
* 3.call()可以抛异常,但是run()方法抛不了
* 4.callable线程类,只能通过线程池的submit方法来执行线程,返回的future对象,通过get()能够拿到call()的返回值
*/
class CallableExecRunner implements Callable<String>{
public String call() throws Exception {
System.out.println("线程正在工作");
Thread.sleep(5000);
return "success";
}
}
线程池关闭
线程池本身会消耗资源
调用shutdown 会关闭线程池,但不会立即关闭掉,但也不会接收新的任务(处理新的线程请求),等到所有线程都完成工作后,才关闭
如果想立即关闭线程池,可以调用shutdownnow
Lock 锁

ReadWriteLock读写锁

代码:
/*
* 这个方法用来测试FileChannel,FileChannel只能通过FileInputStream,FileOutputStream和
* RandomAccessFile的getChannel()方法得到。
* FileChannel在文件操作上,性能上没什么差别。读或写都是通过缓冲区来操作。此外还提供了一些额外方法,比如可以指定从文件的某个位置开始读或写
* 如果FileChannel是通过FileInputStream得到,那他只能读文件,不能写文件。
*/
@Test
public void test02() throws Exception{
FileChannel fc=new FileInputStream(new File("test02.txt")).getChannel();
ByteBuffer buffer=ByteBuffer.allocate(1);
fc.position(4);
fc.read(buffer);
System.out.println(new String(buffer.array()));
fc.close();
}
@Test
public void test03() throws Exception{
FileChannel fc=new FileOutputStream(new File("test03.txt")).getChannel();
fc.write(ByteBuffer.wrap("test03".getBytes()));
fc.close();
}
/*
* 通过RandomAccessFile得到的FileChannel,既可以对指定文件读也可以写。并且都可以指定开始读或写的位置
*/
@Test
public void test04() throws Exception{
FileChannel fc=new RandomAccessFile(new File("test03.txt"), "rw").getChannel();
ByteBuffer readBuf=ByteBuffer.allocate(1);
fc.position(2);
fc.read(readBuf);
System.out.println("读到的是:"+new String(readBuf.array()));
fc.write(ByteBuffer.wrap("new data".getBytes()));
fc.close();
}
代码:
/*
* 这个方法是用来测试DatagramChannel的客户端,用于实现UDP通信。本方法是发送数据方
*/
@Test
public void test01_Client() throws Exception{
DatagramChannel dc=DatagramChannel.open();
dc.send(ByteBuffer.wrap("hello".getBytes()),new InetSocketAddress("127.0.0.1",7777));
}
/*
* 这个方法是用来做UDP通信的服务端的,用于接收数据。
*/
@Test
public void test01_Server() throws Exception{
DatagramChannel dc=DatagramChannel.open();
dc.socket().bind(new InetSocketAddress(7777));
ByteBuffer buffer=ByteBuffer.allocate(5);
dc.receive(buffer);
System.out.println(new String(buffer.array()));
}