进程和线程
什么是进程?
进程就是进展中的程序,或者说是执行中的程序。一个程序加载到内存后,就变为进程。
即:进程=程序+执行
进程模型的三个视角

为什么要引入进程机制?
原因是为了实现多道编程。
多道编程的好处一是提高cpu的利用率。
举例:如果一个程序,有20%的使用cpu进行计算,另外80%的时间用来进行I/O
如果是单道编程,cpu的利用率是1-0.8=0.2。
如果是多道编程,比如两个进程,cpu的利用率是1-0.80.8=0.36 (两个进程都处于I/O时,cpu才会处于空闲)。
如果是三个进程,1-0.80.8*0.8=48%。即随着进程数量增多,cpu利用率上升,并趋近于某个阈值。
多道编程的好处二是响应时间改善
进程的产生和销毁

后来人们根据以上状态,总结出进程的三种状态:
1.执行
2.就绪
3.阻塞
CPU只轮询和运算前两种状态进程,不会轮询阻塞态的进程。此外,三种状态之间可以进行各种转换。但是标红的转换不可能发生。
执行——就绪
执行——阻塞
就绪——阻塞
就绪——执行
阻塞——执行
阻塞——就绪
什么是线程
为什么要有线程?就拿我用onenote写课堂笔记来说,onenote需要监听我打字输入的状态,还需要每隔一段时间对笔记进行自动保存。假设如果只有这个进程本身,那么当对笔记进行保存时,因为此时需要访问硬盘,而访问硬盘的时间进程是阻塞状态的,这时我的任何输入都会没有响应,这种用户体验是无法接受的,或许我们可以通过键盘或者鼠标的输入去中断保存草稿的过程,但这种方案也并不讨好。而引入了线程概念后,确切的说,我们用一个线程或多个线程来完成工作,每个线程仅仅需要处理自己那一部分应该完成的任务,而不用去关心和其它线程的冲突。
操作系统引入线程概念后,线程是进程真正工作的单位,一个进程下至少有一个线程。线程也是进程的分身,能够让一个进程在宏观上同时干多件事。
因为线程是进程的分身,所以每个线程在本质上是一样的,有相同的程序文本。线程和进程一样,有三种状态:执行、就绪和阻塞。
总结:进程的出现,是为了满足多道编程,提高cpu利用率。而线程的出现,是为了让一个进程在宏观上同时做多件事。
即现代计算机引入了进程和线程后,使得cpu利用率和操作响应时间大大提高。
进程是组织资源的最小单位,独占一块内存地址空间,在内存空间里存储一些全局变量等。
线程是cpu执行的最小单位,即程序在工作,实际是cpu在运算一个个的线程。
打个比喻:进程一个舞台,组织了各种资源,灯光、道具等。而线程就是这舞台上的演员,共享和运用舞台的资源来表演。
NIO与BIO
NIO概述
Non-Blocking I/O,是一种非阻塞通信模型。不同的语言或操作系统都有其不同的实现。
我们主要学习基于Java语言的NIO,也称为java.nio。
java.nio是jdk1.4版本引入的一套API,我们可以利用这套API实现非阻塞的网络编程模型。
为什么要学习NIO
目前无论是何种应用,都是分布式架构,因为分布式架构能够抗高并发,实现高可用,负载均衡以及存储和处理海量数据,而分布式架构的基础是网络通信。因此, 因此,网络编程始终是分布式软件工程师和架构师的必备高端基础技能之一。
随着当前大数据和实时计算技术的兴起,高性能 RPC 框架与网络编程技术再次成为焦点。 比如Fackebook的Thrift框架,scala的 Akka框架,实时流领域的 Storm、Spark框架,又或者开源分布式数据库中的 Mycat、VoltDB,这些框架的底层通信技术都采用了 NIO(非阻塞通信)通信技术。而 Java 领域里大名鼎鼎的 NIO 框架——Netty,则被众多的开源项目或商业软件所采用。
java.bio和java.nio的区别

NIO和BIO的应用场景
NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,网页浏览。编程比较复杂,
BIO开发,处理每一个客户端都需要在服务器端创建一个线程来处理。开启线程需要占用内存资源,并且线程轮询也需要消耗资源。所以,BIO编程,不可能应对高用户量访问的场景。
但是有些持续性操作,比如上传下载一个大文件,用NIO的方式不会比IO好。
BIO实现的Socket——4种产生阻塞的方法
BIO 4种产生阻塞的方法:
ServerDemo1代码(用于测试accpet,connect,read):
/**
* 这个类是作为socket的服务端
* @author ysq
*
*/
public class ServerDemo1 {
public static void main(String[] args) throws Exception {
ServerSocket ss=new ServerSocket();
ss.bind(new InetSocketAddress(9999));
//accept方法会产生阻塞,直到有客户端连接
//传统的BIO会产生阻塞:
//1.服务端accept()方法会产生阻塞
Socket s=ss.accept();
//接下来做读入流的测试
//当有客户端接入时,accpet()方法不阻塞
//但是客户端没有任何的流输入,所以产生了阻塞
//2.即read()方法也会产生阻塞
InputStream in=s.getInputStream();
System.out.println("1");
in.read();
System.out.println("2");
}
}
ClientDemo1代码(用于测试accpet,connect,read):
/**
* 这个类是客户端的Socket
* @author ysq
*
*/
public class ClientDemo1 {
public static void main(String[] args) throws Exception {
//如果服务端未启动,客户端就连接的话会报错,Connection refused
//但是,需要留意的是,这个异常在程序启动后,并不是马上抛出的
//而是卡顿了一秒钟才出现的
//这个现象的原因:
//客户端程序启动=》尝试连接服务端=》等待服务端的链接响应=》服务端没有启动=》
//客户端收到服务端的响应,报出错误提示
//实际上,对应客户端,socket.connect()这个方法也会产生阻塞
Socket socket=new Socket();
socket.connect(new InetSocketAddress("127.0.0.1", 9999));
//while(true){}的意思是让客户端一直保持连接。
while(true){}
}
}
ServerDemo2代码(用于测试write方法):
public class ServerDemo2 {
public static void main(String[] args) throws Exception {
ServerSocket ss =new ServerSocket();
ss.bind(new InetSocketAddress(9998));
Socket s=ss.accept();
while(true){
}
}
}
ClientDemo2代码(用于测试write方法):
/**
*这个类是用来测试客户端socket write()方法是否阻塞
*/
public class ClientDemo2 {
public static void main(String[] args) throws IOException {
Socket s=new Socket();
s.connect(new InetSocketAddress("127.0.0.1",9998));
OutputStream out=s.getOutputStream();
for(int i=0;i<1000000;i++){
System.out.println(i);
//结果证明,当不断向outputStream里写数据时,写到一定大小后,会产生阻塞
//即Write方法也会产生阻塞
out.write("a".getBytes());
}
out.flush();
out.close();
}
}
由于底层设备的缓存大小有限,当一直向缓冲区里写数据,却一直不往出取时,达到缓冲区大小上限时,就会造成阻塞,写不出去了。
Buffer—ByteBuffer
Buffer:缓冲区,内存里一段连续的空间
Buffer的子类,对应了8种基本数据类型里的七种(没有boolean类型),分别是:
1.ByteBuffer
2.CharBuffer
3.DoubleBuffer
4.FolatBuffer
5.IntBuffer
6.LongBuffer
7.ShortBuffer
ByteBuffer
1.创建缓冲区
static ByteBuffer allocate(int capacity)
参数:capacity 缓冲区的容量,以字节为单位
相关代码:
@Test
public void testCreateBuffer(){
//ByteBuffer是一个抽象类,我们得到的是他的实现子类对象,HeapByteBuffer
ByteBuffer buffer=ByteBuffer.allocate(1024);
}
相关代码:
@Test
public void testCreateBufferByWrap(){
//wrap方法也可以创建一个Buffer,接收的是一个字节数组,
//并且利用wrap方法创建完buffer之后,buffer里就有了字节数组里的数据
byte[] b={1,2,3,4};
ByteBuffer buffer=ByteBuffer.wrap(b);
//也可以通过指定数组下标的界限来创建Buffer并填充数据,需要注意的是:
//利用此方法创建buffer,buffer的容量和数组的容量一致,buffer里也包含了数组的全部数据,
//不同的是limit的位置变化了
ByteBuffer buffer2=ByteBuffer.wrap(b,0,2);
}
2.向缓冲区里写数据
put(byte b)
put(byte[] src)
putXxx()
代码:
public void testPutData(){
ByteBuffer buffer=ByteBuffer.allocate(1024);
//利用put方法,存入的是字节数据,占一个字节
buffer.put((byte) 1);
//putInf,存入的是整数数据,占四个字节,在开发里,我们操作都是字节数据,所以掌握put方法即可
buffer.putInt(1);
//put方法也可以传入字节数组
buffer.put("123".getBytes());
}
3.从缓冲区里读数据
get()
但是,当向缓冲区里写入字节时,比如1,当调用get()方法时,得到的却是0,这是什么原因呢?
代码:
@Test
public void testGet(){
ByteBuffer buffer=ByteBuffer.allocate(1024);
buffer.put((byte) 1);
buffer.put((byte) 2);
buffer.put((byte) 3);
//当调用get方法是,之所以是0,是因为,在buffer缓冲区里,有一个position指针,每次put后,position位置+1
//所以,但put完之后,直接调用get()方法,get()是根据最新指针位置来取值的,最新位置肯定是没有数据的,所以是0
System.out.println(buffer.get());
//也可以通过get(position)来读取指定位置的数据
System.out.println(buffer.get(0));
}
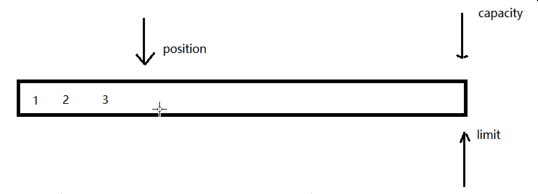
4.Buffter缓冲区的4个关键元素
①capacity,缓存区总容量
②limit的大小<=capacity的大小,创建缓冲区时,默认=capacity
③position,初始位置在缓存区的0位,当写入数据时,数据的写入位置就是position的位置
写完后,position的位置+1。
④mark,标记
测试代码:
@Test
public void testPositionAndLimit(){
ByteBuffer buffer=ByteBuffer.allocate(1024);
buffer.put((byte) 1);
buffer.put((byte) 2);
buffer.put((byte) 3);
//当一个缓冲区创建出来之后,position的初始位置是0,每put()一次或每get()一次,都会使得positon的位置+1
System.out.println("当前的position位置:"+buffer.position());
//在写完数据后,将limit设置为当前position位置,然后将position位置重置为0
//这样做的目的是为了从头开始读数据,并且,用limit限制了读取下标,不会造成读出空数据的情况
buffer.limit(buffer.position());
//position位置重置为0
buffer.position(0);
}

5.filp()方法:
flip()反转缓冲区,作用相当于buffer.limit(buffer.position());+ buffer.position(0);
代码:
@Test
public void testFlip(){
ByteBuffer buffer=ByteBuffer.allocate(1024);
buffer.put((byte) 1);
buffer.put((byte) 2);
buffer.put((byte) 3);
//flip()反转缓冲区,作用相当于buffer.limit(buffer.position());+buffer.position(0);
buffer.flip();
}
HasRemaining方法:
告知当前位置(position)和限制位(limit)之间是否还有元素
代码:
public void testHasRemaining(){
ByteBuffer buffer=ByteBuffer.allocate(1024);
buffer.put((byte) 1);
buffer.put((byte) 2);
buffer.put((byte) 3);
buffer.flip();
while(buffer.hasRemaining()){
System.out.println(buffer.get());
}
}
6.rewind()重绕缓冲区
将position置为0
7.clear()清空缓冲区
@Test
public void testClear(){
ByteBuffer buffer=ByteBuffer.allocate(1024);
buffer.put((byte) 1);
buffer.put((byte) 2);
buffer.put((byte) 3);
//clear的作用是清空缓冲区,但并不真正的清除数据,而是把postion置为0,limit置为容量上限
//所以,当get(0)时,是可以得到原缓冲区数据的。但是我们一般都是在clear()方法之后,写数据,然后filp()
//所以,并不影响缓冲区的重用。
buffer.clear();
System.out.println(buffer.get(0));
}
Channel
Channel:通道,面向缓冲区,进行双向传输
总接口:Channel
其中重点关注他的4个子类:
操作TCP的
SocketChannel
ServerSocketChannel
操作UDP的
DatagramChannel
操作文件的
FileChannel
1.ServerSocketChannel
代码:
//这个方法用来测试ServerSocketChannel
@Test
public void testServerSocketChannel() throws IOException{
//ServerSocketChannel是一个抽象类,不能直接new,所以调用其静态方法open()
//创建出来的对象是ServerSocketChannelImpl的实例
ServerSocketChannel ssc=ServerSocketChannel.open();
ssc.socket().bind(new InetSocketAddress(9999));
//ServerSocketChannel 创建出来之后,默认是阻塞的,如果要设置成非阻塞模式,需要设置:
//ssc.configureBlocking(false); 属性为false表示非阻塞
ssc.configureBlocking(false);
ssc.accept();
System.out.println("NIO服务端收到客户端请求");
}
2.SocketChannel
代码:
@Test
public void testSocketChannel() throws Exception{
SocketChannel sc=SocketChannel.open();
//SocketChannel默认也是非阻塞的,需要个更改下configureBlocking(false);
sc.configureBlocking(false);
sc.connect(new InetSocketAddress("127.0.0.1",9999));
}
3.read和write方法
服务端代码(read)代码:
public class ServerDemo1 {
public static void main(String[] args) throws Exception {
ServerSocketChannel ssc=ServerSocketChannel.open();
ssc.configureBlocking(false);
ssc.socket().bind(new InetSocketAddress(9999));
//ServerSocketChannel不做任何数据上的处理,只是提供通道,负责连接。SocketChannel职责和net包下的socket类似
SocketChannel sc=null;
while(sc==null){
sc=ssc.accept();
}
ByteBuffer buffer=ByteBuffer.allocate(12);
//这里需要注意的是:当read读的时候,需要分配好容量。
//此外,read方法也是非阻塞的,需要用while(buffer.hasRemaining())来确保数据读取完整
while(buffer.hasRemaining()){
sc.read(buffer);
}
System.out.println("服务端接收数据:"+new String(buffer.array()));
}
}
客户端代码(write)代码:
public class ClientDemo1 {
public static void main(String[] args) throws IOException {
SocketChannel sc=SocketChannel.open();
sc.configureBlocking(false);
sc.connect(new InetSocketAddress("127.0.0.1", 9999));
while(!sc.isConnected()){
sc.finishConnect();
}
ByteBuffer buffer=ByteBuffer.wrap("hello1604NIO".getBytes());
while(buffer.hasRemaining()){
//因为write方法是非阻塞的,那就是意味着write方法是否已经将buffer里的数据全部写完都会执行后面的代码
//所以要用到while(buffer.hasRemaining())这种形式来确保buffer数据全部写出
sc.write(buffer);
}
sc.close();
}
}
Selector
Selector 多路复用器:
可以理解为路由器和交换机
在一个Selector上可以同时注册多个非阻塞的通道,从而只需要很少的线程数既可以管理许多通道。特别适用于开启许多通道但是每个通道中数据流量都很低的情况

回顾BIO的缺陷:
在高并发场景下,BIO的阻塞会产生一些无法解决的问题,
1.一个客户端连接,服务端就会分配一个线程来处理,如果有1000个客户端访问,就会有1000个线程。线程多所造成的问题

2.比如针对聊天程序,可能某一个线程没有做任何事情,却一直连着,导致线程大部门时间都是闲置的状态。
针对上面的模型,我们想出用下面的模型来处理:

这种模型的核心思想:
有一个关键的元素,选择器。针对上图来说,三个客户端连接请求过来之后,先在选择器上进行注册,然后由选择器来决定当前时刻哪个客户端需要被处理,就交给线程来处理。
这样,就相当用很少的线程来处理很多的客户端的连接请求。
但需要注意,针对上述这种模型,传统的BIO做不了。为什呢?
如果用传统的IO,即阻塞式IO,当选择器选择处理某一个客户端时,可能会因accept,connect,read,write产生阻塞,如果线程产生阻塞,就会导致线程没有机会去处理其他的客户端连接请求。
NIO实现之服务端
服务端代码:
public class ServerSocketBySelector {
public static void main(String[] args) {
new Thread(new Server()).start();
}
static class Server implements Runnable{
@Override
public void run() {
try {
selector=Selector.open();
ServerSocketChannel ssc=ServerSocketChannel.open();
ssc.configureBlocking(false);
ssc.socket().bind(new InetSocketAddress(8888));
Selector selector=Selector.open();
ssc.register(selector, SelectionKey.OP_ACCEPT);
while(true){
//select()是选择器selector查询是否有事件触发的方法,比如accpet事件是否触发,如果accpet事件触发:
//就意味着有客户端接入了。注意,select()是一个阻塞方法。当有事件被触发时,阻塞放开。
//引入selector的好处是:线程不必每时每刻都去工作、去查询客户端是否有新事件,没有事件的时候,线程就睡觉,休息
//有事件发生,selector会知道,线程再醒来工作。这样一来,可以避免了线程无意义的空转,节省cpu资源,同时也不影响工作
selector.select();
//能走到下面的代码,说明有事件需要处理了,我们需要根据具体是什么事件,来做相应的处理,对于服务端来说,事件分为:
//1.SelectionKey.OP_ACCPET 新客户端接入事件
//2.SelectionKey.OP_WRITE 客户端接入后,客户端给服务端传数据事件
//3.SelectionKey.OP_READ 客户端接入后,服务端给客户端传数据事件
Set<SelectionKey> set=selector.selectedKeys();
Iterator<SelectionKey> it=set.iterator();
while(it.hasNext()){
SelectionKey key=it.next();
if(key.isAcceptable()){
System.out.println("有客户端接入");
ServerSocketChannel ss=(ServerSocketChannel) key.channel();
SocketChannel sc=ss.accept();
sc.configureBlocking(false);
sc.register(selector, SelectionKey.OP_READ);
}else if(key.isReadable()){
System.out.println("read");
//处理如何向客户端写出数据
//处理完后,将OP_READ事件移除
SocketChannel s=(SocketChannel) key.channel();
ByteBuffer buffer=ByteBuffer.allocate(3);
while(buffer.hasRemaining()){
s.read(buffer);
}
//处理完read事件后,需要把read事件从当前的SelectionKey键集里删除,避免重复处理
//如果想取消SelectionKey里某一个事件,先对这个事件的二进制取反,在&当前键集的状态
System.out.println("服务端接收到信息:"+new String(buffer.array()));
s.register(selector, key.interestOps()&~SelectionKey.OP_READ);
}
//防止已处理完毕的SelectionKey再次被处理
it.remove();
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
NIO实现之客户端
客户端代码:
public class SocketChannelBySelector {
public static void main(String[] args) {
new Thread(new Client()).start();
}
static class Client implements Runnable{
@Override
public void run() {
try {
Selector selector=Selector.open();
SocketChannel sc=SocketChannel.open();
sc.configureBlocking(false);
sc.connect(new InetSocketAddress("127.0.0.1",8888));
sc.register(selector,SelectionKey.OP_CONNECT);
while(true){
selector.select();
Set<SelectionKey> set=selector.selectedKeys();
Iterator<SelectionKey> it=set.iterator();
while(it.hasNext()){
SelectionKey key=it.next();
if(key.isConnectable()){
SocketChannel s=(SocketChannel) key.channel();
if(!s.isConnected()){
s.finishConnect();
}
s.register(selector, SelectionKey.OP_WRITE);
}else if(key.isWritable()){
SocketChannel s=(SocketChannel) key.channel();
ByteBuffer buffer=ByteBuffer.wrap("aaa".getBytes());
while(buffer.hasRemaining()){
s.write(buffer);
}
s.register(selector, key.interestOps()&~SelectionKey.OP_WRITE);
}
it.remove();
}
}
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
粘包问题及NIO代码改造
TCP粘包
在进行TCP通信时,TCP粘包是指发送方发送若干包数据,而接受方在接受时粘成一包。从缓冲区来看这些数据,后一包数据的头紧接着前一包数据的尾。
比如:jary23manrose25woman
不是所有的粘包问题都需要处理的。比如文件传输,只要能保证是连续流数据即可。但是,如果是带结构的数据,比如每次发送的包数据长度正好代表一条用户信息,那这个是时候粘包就需要处理了,我们也叫分包。
解决粘包问题,一般有几下几种策略:
1.发送方和接收方实现就规定好 包的数据长度。但这种方式不灵活
2.约定分割符 比如 # 发送方: helloworld#welcome。但这种方式,需要考虑 切割符是包数据的情景
3.制订协议,根据协议头,比如package-length信息得知包信息的长度。
Java NIO的总结
总结
最后总结一下到底NIO给我们带来了些什么:
1)事件驱动模型
2)避免多线程
3)单线程处理多任务
4)非阻塞I/O,I/O读写不再阻塞
5)基于block的传输,通常比基于流的传输更高效
6)IO多路复用大大提高了Java网络应用的可伸缩性和实用性
相对于它的老前辈 BIO(阻塞通信)来说,NIO 模型非常复杂,以至于苦学了很久以后也很少有人能够精通它,难以编写出一个没有缺陷、高效且适应各种意外情况的稳定的 NIO 通信模块。
之所以会出现这样的问题,是因为 NIO 编程不是单纯的一个技术点,而是涵盖了一系列相关的技术、专业知识、编程经验和编程技巧的复杂工程。
Java NIO 虽然提供了非阻塞的网络通信编程API,但它的设计本身也有一些问题。
Zebra阶段试题
一、单选题
1.关于nio和bio的说法,不正确的是
a.nio是非阻塞io
b.nio是面向流的
c.nio是面向缓冲区的
d.bio是阻塞io
答案:b
2.selector监听的事件不包括
a.connect
b.accept
c.quit
d.write
e.read
答案:c
3.下列关于Buffer缓冲区说法不正确的是
a.ByteBuffer是字节缓冲区
b.创建缓冲区后,position的初始位置等于limit的初始位置
c.ByteBuffer可以存储整型数据
答案:b
4.以下关于阻塞队列说法不正确的是
a.LinkedBlockingQueue 创建时默认是无界的
b.阻塞队列是生产-消费模型
c.put( )方法会抛异常
d.poll()方法会抛特定值
答案:c
5.以下关于ConcurrentMap说法不正确的是
a.ConcurrentHashMap是并发安全的
b.ConcurrentHashMap性能要高于HashTable
c.ConcurrentHashMap调用 insert(k,v)方法插入key和value值
答案:c
6.以下关于CountDownLatch说法不正确的是
1.默认是公平锁
2.await( )方法会产生阻塞
3.countdown( )方法会使递减1
答案:a
二、判断题
7.Zookeeper适用于存储大量数据 (错)
8.Zookeeper集群数量一般是奇数个(对)
9.Zookeeper里节点路径不是唯一的(错)
10.Zookeeper集群一共5台机器,则最多可配置Zookeeper的观察者数量为3台(错)
三、问答题
简单阐述Zookeeper的选举机制
Zookeeper的节点有几种类型?分别有什么特点
如何利用Zookeeper实现分布式锁?
Hadoop阶段试题
一. 单选题
-
下面哪个进程负责 HDFS 的数据存储。
a.NameNode
b.ResourceManager
c.Datanode
d.NodeManager
答案:C datanode -
HDfS 中的 block 默认保存几份?
a.3 份
b.2 份
c.1 份
d.不确定
答案:A 默认3份 -
下列哪个程序通常与 NameNode在一个节点启动?
a.SecondaryNameNode
b.DataNode
c.NodeManager
d.ResourceManager
答案:D -
Hadoop作者
a.Martin Fowler
b.Kent Beck
c.Doug cutting
答案:C Doug cutting
5.Hadoop2.0版本, HDFS默认Block Size多大?
a.32MB
b.64MB
c.128MB
答案:C
-
下列哪项通常是集群的最主要瓶颈
a.CPU
b.网络
c.磁盘IO
d.内存
答案:C磁盘
分析:
首先集群的目的是为了节省成本,用廉价的pc机,取代小型机及大型机。cpu处理能力强, 内存够大, 所以集群的瓶颈不可能是a和d; 网络是一种稀缺资源,但是并不是瓶颈。由于大数据面临海量数据,读写数据都需要io,然后还要冗余数据,hadoop一般备3份数据,所以IO就会打折扣。对于磁盘IO:当我们面临集群作战的时候,我们所希望的是即读即得。可是面对大数据,读取数据需要经过IO,这里可以把IO理解为水的管道。管道越大越强,我们对于T级的数据读取就越快。所以IO的好坏,直接影响了集群对于数据的处理。 -
关于SecondaryNameNode哪项是正确的?
a.它是NameNode的热备
b.它对内存没有要求
c.它的目的是帮助NameNode合并编辑日志,减少NameNode启动时间
d.SecondaryNameNode应与NameNode部署到一个节点
答案C。
二.多选题
-
下面哪项正确
a.如果一个机架出问题,不会影响数据读写
b.写入数据的时候会写到不同机架的 DataNode 中
c.MapReduce会根据机架获取离自己比较近的网络数据
答案:ABC -
Client 端上传文件的时候下列哪项正确
a.数据经过 NameNode 传递给 DataNode
b.Client端将文件切分为Block,Block再变成packet依次上传
c.Client只上传数据到一台DataNode,然后由NameNode负责Block复制工作
答案:B -
下列哪个是 Hadoop 运行的模式
a.单机版
b.伪分布式
c.完全分布式
答案:ABC
三. 判断题
11. Block Size是不可以修改的。(错误)
它是可以被修改的
-
如果NameNode意外终止,SecondaryNameNode会接替它使集群继续工作。(错误)
分析:
SecondaryNameNode是帮助恢复,而不是替代,因为它达不到热备效果。2.0版本已经舍去SNN机制。 -
Hadoop是Java开发的,所以MapReduce只支持Java语言编写。(错误)
-
Hadoop 支持数据的随机读写。(错)
分析:
lucene是支持随机读写的,而hdfs只支持随机读。但是HBase可以来补救。HBase提供随机读写,来解决Hadoop不能处理的问题。
HBase自底层设计开始即聚焦于各种可伸缩性问题:表可以很“高”,有数十亿个数据行;也可以很“宽”,有数百万个列;水平分区并在上千个普通商用机节点上自动复制。表的模式是物理存储的直接反映,使系统有可能提高高效的数据结构的序列化、存储和检索。 -
NameNode 负责管理 metadata,client 端每次发送读请求时,它都会从磁盘中读取 metadata 信息并反馈 client 端。(错误)
分析:
NameNode 不需要从磁盘读取 metadata,所有数据都在内存中,硬盘上的只是序列化的结果,只有每次 namenode 启动的时候才会读取。 -
NameNode 本地磁盘保存了 Block 的位置信息。(正确)
分析:
DataNode是文件存储的基本单元,它将Block存储在本地文件系统中,保存了Block的Meta-data,同时周期性地将所有存在的Block信息发送给NameNode。 -
因为 HDFS 有多个副本,所以 NameNode 是不存在单点问题的。(错误)
-
每个 map 槽就是一个线程。(错误)
分析:首先我们知道什么是map槽,map槽->map slot
map slot只是一个逻辑值 ( org.apache.hadoop.mapred.TaskTracker.TaskLauncher.numFreeSlots ),而不是对应着一个线程或者进程 -
Mapreduce 的 input split 就是一个 block。(错误 )
20.HDFS适合存储海量小文件。(错误)
21.MapReduce默认的分区数量是1个。(正确)
四、问答题:
-
简述MapReduce大致流程,map -> shuffle -> reduce
-
写出三种你熟知的Hadoop调优策略,并阐述原理
-
简述HDFS的写流程
4.简述Hive的物理模型跟传统数据库有什么不同
5.Hbase中的metastore用来做什么的?
6.什么情况下使用Hbase?
适合海量的,但同时也是简单的操作(例如:key-value)
成熟的数据分析主题,查询模式已经确定并且不会轻易改变。
传统的关系型数据库已经无法承受负荷,高速插入,大量读取
7.生产环境中为什么建议使用外部表?
8.Hive内部表和外部表的区别?
- 在导入数据到外部表,数据并没有移动到自己的数据仓库目录下,也就是说外部表中的数据并不是由它自己来管理的!而内部表则不一样;
- 在删除内部表的时候,Hive将会把属于内部表的元数据和数据全部删掉;而删除外部表的时候,Hive仅仅删除外部表的元数据,数据是不会删除的!
那么,应该如何选择使用哪种表呢?在大多数情况没有太多的区别,因此选择只是个人喜好的问题。但是作为一个经验,如果所有处理都需要由Hive完成,那么你应该创建内部表,否则使用外部表!
Nio与零拷贝
transferTo代码:
@Test
public void testWrite() throws Exception{
SocketChannel sc=SocketChannel.open();
sc.connect(new InetSocketAddress("127.0.0.1",8888));
final Path filePath = Paths.get("1.txt");
FileChannel fileChannel = (FileChannel.open(filePath,
EnumSet.of(StandardOpenOption.READ)));
//用来发送文件大小
ByteBuffer buf = ByteBuffer.allocate(8);
buf.asLongBuffer().put(fileChannel.size());
sc.write(buf);
fileChannel.transferTo(0, fileChannel.size(), sc);
fileChannel.close();
sc.close();
}
transferFrom代码:
@Test
public void testRead() throws Exception{
ServerSocketChannel ssc=ServerSocketChannel.open();
ssc.bind(new InetSocketAddress(8888));
SocketChannel sc=ssc.accept();
final Path filePath = Paths.get("2.txt");
FileChannel fileChannel = (FileChannel.open(filePath,
EnumSet.of(StandardOpenOption.CREATE_NEW,
StandardOpenOption.WRITE,
StandardOpenOption.TRUNCATE_EXISTING)));
ByteBuffer buf = ByteBuffer.allocate(8);
sc.read(buf);
buf.flip();
long fileSize = buf.getLong();
System.out.println("fileSize :" + fileSize);
fileChannel.transferFrom(sc, 0, fileSize);
fileChannel.close();
}
@Test
public void testWrite() throws Exception{
SocketChannel sc=SocketChannel.open();
sc.connect(new InetSocketAddress("127.0.0.1",8888));
//final Path filePath = Paths.get("1.txt");
FileChannel fileChannel = new FileInputStream("1.txt").getChannel();;
//用来发送文件大小
ByteBuffer buf = ByteBuffer.allocate(8);
buf.asLongBuffer().put(fileChannel.size());
sc.write(buf);
fileChannel.transferTo(0, fileChannel.size(), sc);
fileChannel.close();
sc.close();
}
@Test
public void testRead() throws Exception{
ServerSocketChannel ssc=ServerSocketChannel.open();
ssc.bind(new InetSocketAddress(8888));
SocketChannel sc=ssc.accept();
//final Path filePath = Paths.get("2.txt");
FileChannel fileChannel = new FileOutputStream("2.txt").getChannel();
ByteBuffer buf = ByteBuffer.allocate(8);
sc.read(buf);
buf.flip();
long fileSize = buf.getLong();
System.out.println("fileSize :" + fileSize);
fileChannel.transferFrom(sc, 0, fileSize);
fileChannel.close();
}