网站流量统计案例概述
背景说明
网站流量统计是改进网站服务的重要手段之一,通过获取用户在网站的行为,可以分析出哪些内容受到欢迎,哪些页面存在问题,从而使网站改进活动更具有针对性。
统计指标说明
常用的网站流量统计指标一般包括以下情况分析:
1)按在线情况分析
在线情况分析分别记录在线用户的活动信息,包括:来访时间、访客地域、来路页面、当前停留页面等,这些功能对企业实时掌握自身网站流量有很大的帮助。
2)按时段分析
时段分析提供网站任意时间内的流量变化情况.或者某一段时间到某一段时间的流量变化,比如小时段分布,日访问量分布,对于企业了解用户浏览网页的的时间段有一个很好的分析。
3)按来源分析
来源分析提供来路域名带来的来访次数、IP、独立访客、新访客、新访客浏览次数、站内总浏览次数等数据。这个数据可以直接让企业了解推广成效的来路,从而分析出那些网站投放的广告效果更明显。
本项目统计的指标说明
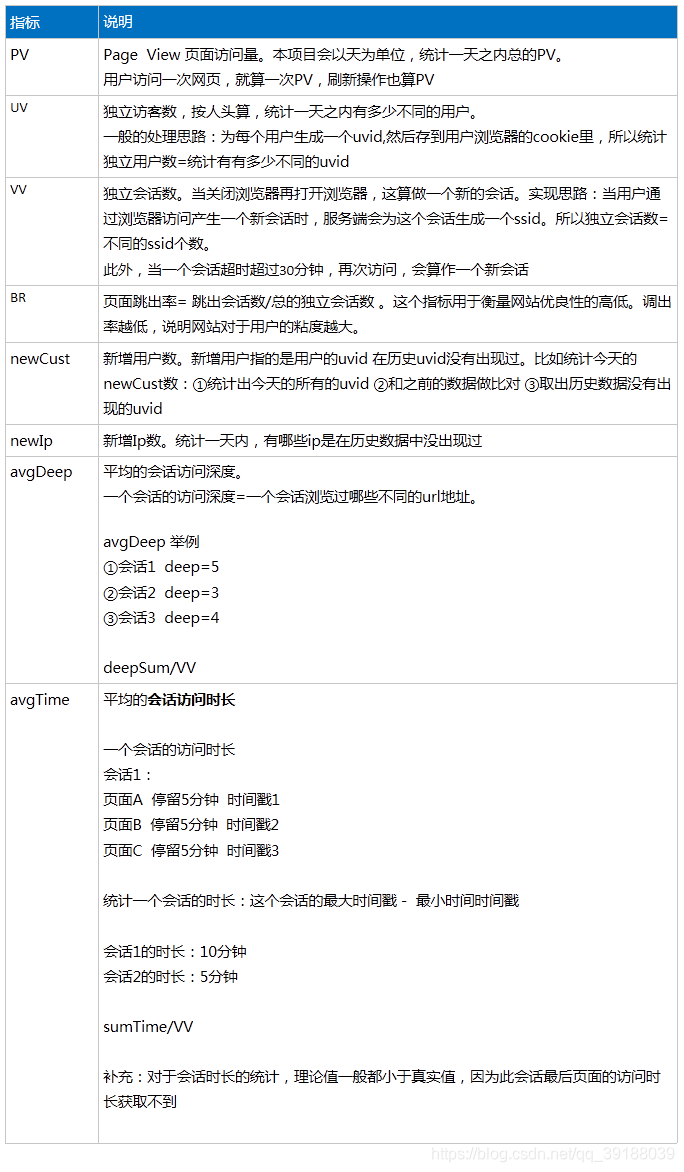
系统架构设计
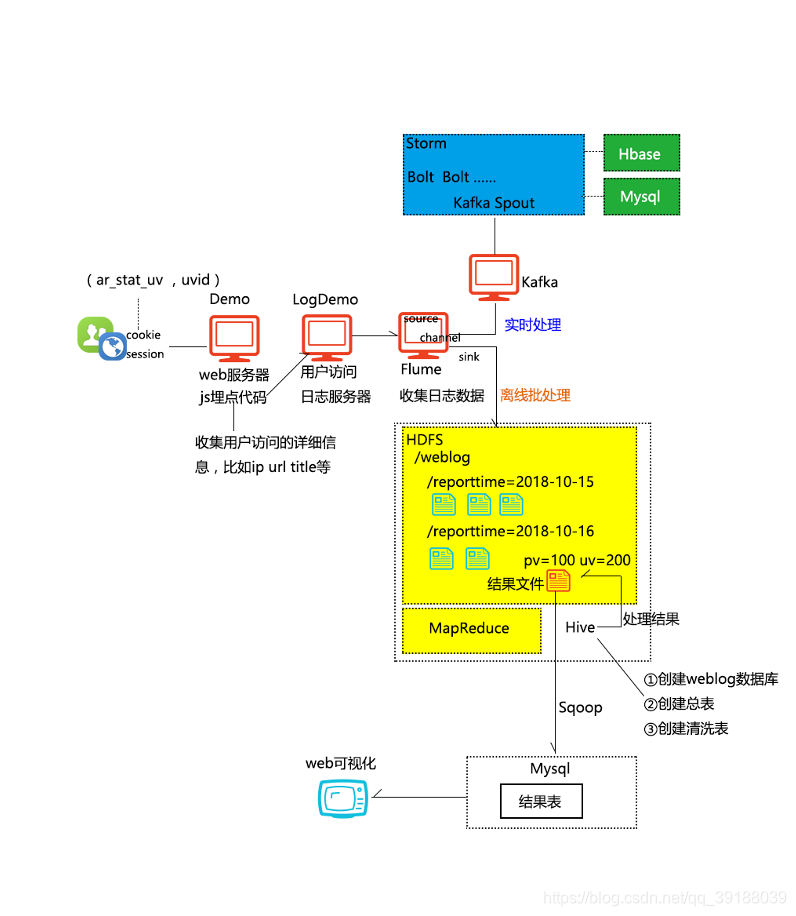
数据的埋点和采集
概述
所谓埋点就是在应用中特定的流程收集一些信息,用来跟踪应用使用的状况,后续用来进一步优化产品或是提供运营的数据支撑,即通过数据埋点来采集数据,比如采集:访问(Visits),访客(Visitor),停留时间(Time On Site),页面查看(Page Views,又称为页面浏览)和跳出率(Bounce Rate,又可称为蹦失率)等等。
一个典型的数据平台,对于数据的处理,是由如下的5个步骤组成的:
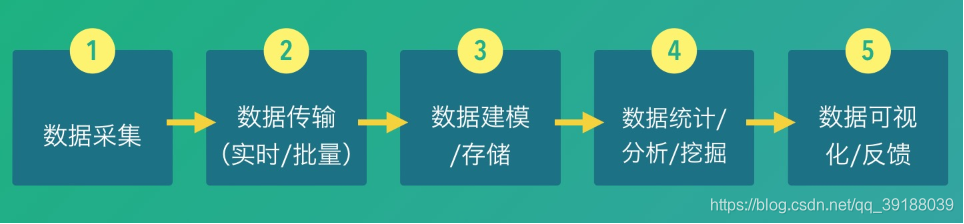
其中,我们认为第一个步骤,也即数据埋点和采集是最基础的问题。数据采集是否丰富,采集的数据是否准确,采集是否及时,都直接影响整个数据平台的应用的效果。
埋点的两种方式:
第一种:自己公司研发在产品中注入埋点代码进行采集。将埋点代码比如写到一个js里,然后放到某个应用网站上。
第二种:使用第三方统计工具,如友盟、百度移动、魔方、App Annie、talking data等。
本项目的埋点实现
我们是通过js代码来实现埋点。编写特定的js脚本,然后嵌入到需要做日志分析的web页面上(实际是通过
日志数据采集模块说明
概述
日志收集的目的最终是把用户对目标网站的访问日志汇聚到HDFS文件系统中的特定目录,以便提供给下一步的数据清洗模块进行处理。要完成这一工作,需要分为如下几个步骤去做:
1)JS埋点
2)日志服务器搭建
3)日志收集
下面对上述四个步骤一一进行详细说明:
一、 JS埋点
我们需要收集某个网页的访问情况,通用的做法是在这个网页上嵌入一个JS脚本,这样当用户访问该页面时,页面上的JS脚本会在页面上动态加入一个标签,并且
的src属性指向日志服务器下的一个透明图片的URL地址。
在该URL参数上会附带一些用户的访问信息(如被访问页面的URL、识别用户身份的cookie等),这样通过分析日志服务器(一般是nginx或apache)的access日志文件就能获取到这些信息。这个JS埋点的脚本可以自己编写来实现,代码片断如下:
js主函数代码:
function ar_main() {
//收集完日志 提交到的路径
var dest_path = "http://localhost:8090/LogDemo/servlet/LogServlet?";
var expire_time = 30 * 60 * 1000;//会话超时时长
//处理uv
//--获取cookie ar_stat_uv的值
var uv_str = ar_get_cookie("ar_stat_uv");
var uv_id = "";
//--如果cookie ar_stat_uv的值为空
if (uv_str == ""){
//--为这个新uv配置id,为一个长度20的随机数字
uv_id = ar_get_random(20);
//--设置cookie ar_stat_uv 保存时间为10年
ar_set_cookie("ar_stat_uv", uv_id, 1);
}
//--如果cookie ar_stat_uv的值不为空
else{
//--获取uv_id
uv_id = uv_str;
}
//处理ss
//--获取cookie ar_stat_ss
var ss_str = ar_get_cookie("ar_stat_ss");
var ss_id = ""; //sessin id
var ss_no = 0; //session有效期内访问页面的次数
//--如果cookie中不存在ar_stat_ss 说明是一次新的会话
if (ss_str == ""){
//--随机生成长度为10的session id
ss_id = ar_get_random(10);
//--session有效期内页面访问次数为0
ss_no = 0;
//--拼接cookie ar_stat_ss 值 格式为 会话编号_会话期内访问次数_客户端时间_网站id
value = ss_id+"_"+ss_no+"_"+ar_get_stm();
//--设置cookie ar_stat_ss
ar_set_cookie("ar_stat_ss", value, 0);
}
//--如果cookie中存在ar_stat_ss
else {
//获取ss相关信息
var items = ss_str.split("_");
//--ss_id
var cookie_ss_id = items[0];
//--ss_no
var cookie_ss_no = parseInt(items[1]);
//--ss_stm
var cookie_ss_stm = items[2];
//如果当前时间-当前会话上一次访问页面的时间>30分钟,虽然cookie还存在,但是其实已经超时了!仍然需要重新生成cookie
if (ar_get_stm() - cookie_ss_stm > expire_time) {
//--重新生成会话id
ss_id = ar_get_random(10);
//--设置会话中的页面访问次数为0
ss_no = 0;
}
//--如果会话没有超时
else{
//--会话id不变
ss_id = cookie_ss_id;
//--设置会话中的页面方位次数+1
ss_no = cookie_ss_no + 1;
}
//--重新拼接cookie ar_stat_ss的值
value = ss_id+"_"+ss_no+"_"+ar_get_stm();
ar_set_cookie("ar_stat_ss", value, 0);
}
//当前地址
var url = document.URL;
url = ar_encode(String(url));
//当前资源名
var urlname = document.URL.substring(document.URL.lastIndexOf("/")+1);
urlname = ar_encode(String(urlname));
//返回导航到当前网页的超链接所在网页的URL
var ref = document.referrer;
ref = ar_encode(String(ref));
//网页标题
var title = document.title;
title = ar_encode(String(title));
//网页字符集
var charset = document.charset;
charset = ar_encode(String(charset));
//屏幕信息
var screen = ar_get_screen();
screen = ar_encode(String(screen));
//颜色信息
var color =ar_get_color();
color =ar_encode(String(color));
//语言信息
var language = ar_get_language();
language = ar_encode(String(language));
//浏览器类型
var agent =ar_get_agent();
agent =ar_encode(String(agent));
//浏览器是否支持并启用了java
var jvm_enabled =ar_get_jvm_enabled();
jvm_enabled =ar_encode(String(jvm_enabled));
//浏览器是否支持并启用了cookie
var cookie_enabled =ar_get_cookie_enabled();
cookie_enabled =ar_encode(String(cookie_enabled));
//浏览器flash版本
var flash_ver = ar_get_flash_ver();
flash_ver = ar_encode(String(flash_ver));
//当前ss状态 格式为"会话id_会话次数_当前时间"
var stat_ss = ss_id+"_"+ss_no+"_"+ar_get_stm();
//拼接访问地址 增加如上信息
dest=dest_path+"url="+url+"&urlname="+urlname+"&title="+title+"&chset="+charset+"&scr="+screen+"&col="+color+"&lg="+language+"&je="+jvm_enabled+"&ce="+cookie_enabled+"&fv="+flash_ver+"&cnv="+String(Math.random())+"&ref="+ref+"&uagent="+agent+"&stat_uv="+uv_id+"&stat_ss="+stat_ss;
//通过插入图片访问该地址
document.getElementsByTagName("body")[0].innerHTML += "<img src=\""+dest+"\" border=\"0\" width=\"1\" height=\"1\" />";
}
此外这个js埋点的脚本我们也可以考虑用第三方开源的产品,这样这些开源产品会自动帮助我们出分析结果。
日志采集系统搭建
实现步骤:
- 创建一个Web工程,比如工程名Demo,这个web工程相当于是一个被访问的web应用,用于生产数据。所以这个web工程会嵌入js埋点
- 创建另一个Web工程,并引入相关的jar包。
此工程用于数据采集,工程名叫LogDemo
log4j配置说明:
log4j.rootLogger = info,stdout,flume
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = %m%n
log4j.appender.flume = org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.flume.Hostname = 192.168.234.21
log4j.appender.flume.Port = 44444
log4j.appender.flume.UnsafeMode = true
收到的一条访问数据如下:
url=http://localhost:8090/Demo/b.jsp&urlname=b.jsp&title=页面B&chset=UTF-8&scr=1024x768&col=24-bit&lg=zh-cn&je=0&ce=1&fv=27.0 r0&cnv=0.7150457187789598&ref=http://localhost:8090/Demo/a.jsp&uagent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2783.4 Safari/537.36&stat_uv=78024453153757966560&stat_ss=8963768770_4_1511903074331
代码示意:
public class LogServlet extends HttpServlet {
private static Logger logger = Logger.getLogger(LogServlet.class);
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String qs = URLDecoder.decode(request.getQueryString(), "utf-8");
String [] attrs = qs.split("\\&");
StringBuffer buf = new StringBuffer();
for(String attr : attrs){
String [] kv = attr.split("=");
String key = kv[0];
String value = kv.length == 2 ? kv[1] : "";
buf.append(value+"|");
}
buf.append(request.getRemoteAddr());
String log = buf.toString();
logger.info(log);
}
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doGet(request, response);
}
}
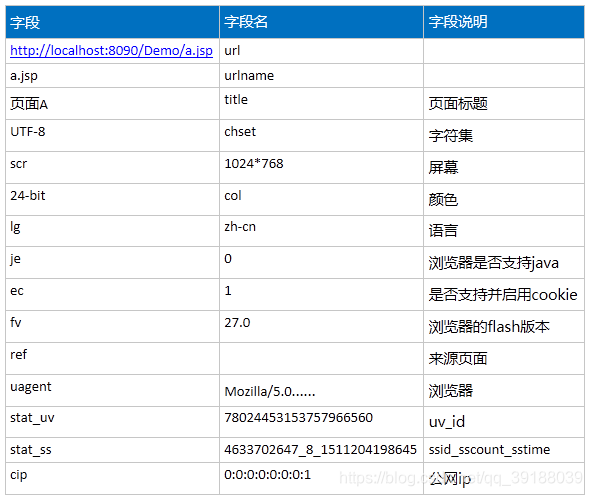
字段说明
3.启动一台flume服务器,测试是否能接收到数据
配置示例:
a1.sources=r1
a1.sinks=s1
a1.channels=c1
a1.sources.r1.type=avro
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=44444
a1.sinks.s1.type=logger
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sources.r1.channels=c1
a1.sinks.s1.channel=c1
启动指令:../bin/flume-ng agent -n a1 -c ./ -f ./02.conf -Dflume.root.logger=INFO,console
Log4j使用介绍
Log4j简介
Log4j有三个主要的组件:Loggers(记录器),Appenders (输出源)和Layouts(布局)。这里可简单理解为日志类别,日志要输出的地方和日志以何种形式输出。
在配置时,这三个组件需要配合在一起进行配置,从而达到日志记录和信息显示的目的。
组件:Loggers
Loggers组件在此系统中被分为五个级别:DEBUG、INFO、WARN、ERROR和FATAL。这五个级别是有顺序的,DEBUG < INFO < WARN < ERROR < FATAL,分别用来指定这条日志信息的重要程度,明白这一点很重要,Log4j有一个规则:只输出级别不低于设定级别的日志信息,假设Loggers级别设定为INFO,则INFO、WARN、ERROR和FATAL级别的日志信息都会输出,而级别比INFO低的DEBUG则不会输出。
组件:Appenders
禁用和使用日志请求只是Log4j的基本功能,Log4j日志系统还提供许多强大的功能,比如允许把日志输出到不同的地方,如控制台(Console)、文件(Files)等,可以根据天数或者文件大小产生新的文件,可以以流的形式发送到其它地方等等。
常使用的类如下:
org.apache.log4j.ConsoleAppender(控制台)
org.apache.log4j.FileAppender(文件)
org.apache.log4j.DailyRollingFileAppender(每天产生一个日志文件)
org.apache.log4j.RollingFileAppender(文件大小到达指定尺寸的时候产生一个新的文件)
org.apache.log4j.WriterAppender(将日志信息以流格式发送到任意指定的地方)
配置模式:
log4j.appender.appenderName = className
log4j.appender.appenderName.Option1 = value1
…
log4j.appender.appenderName.OptionN = valueN
组件:Layouts
有时用户希望根据自己的喜好格式化自己的日志输出,Log4j可以在Appenders的后面附加Layouts来完成这个功能。Layouts提供四种日志输出样式,如根据HTML样式、自由指定样式、包含日志级别与信息的样式和包含日志时间、线程、类别等信息的样式。
常使用的类如下:
org.apache.log4j.HTMLLayout(以HTML表格形式布局)
org.apache.log4j.PatternLayout(可以灵活地指定布局模式)
org.apache.log4j.SimpleLayout(包含日志信息的级别和信息字符串)
org.apache.log4j.TTCCLayout(包含日志产生的时间、线程、类别等信息)
配置模式:
log4j.appender.appenderName.layout =className
log4j.appender.appenderName.layout.Option1 = value1
…
log4j.appender.appenderName.layout.OptionN = valueN
配置说明
配置log4j简单俩说分两步
- 配置组件Logger
- 根据Logger配置appender组件和Layout组件。
Log4j支持两种配置文件格式,一种是XML格式的文件,一种是properties属性文件,下面以properties属性文件为例介绍 log4j.properties的配置。
步骤一,配置根Logger
log4j.rootLogger = [ level ] , appenderName1, appenderName2, …
level :设定日志记录的最低级别,DEBUG、INFO、WARN、ERROR和FATAL。
appenderName:就是指定日志信息要输出到哪里。可以同时指定多个输出目的地,用逗号隔开。
示例:
log4j.rootLogger = info,stdout,E
步骤二,配置输出源及布局
比如我们将stdout输出源定位为:输出到控制台,并指定布局(显示方式)。
示例:
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
此外,我们也可以将D输出源定位为:输出到文件,并指定error级别以上的信息输出的文件里。同时指定日志信息已追加的方式进行记录
示例:
###输出 ERROR 级别以上的日志到 =E://logs/error.log ###
log4j.appender.E = org.apache.log4j.DailyRollingFileAppender
log4j.appender.E.File =E://logs/error.log
log4j.appender.E.Append = true
log4j.appender.E.Threshold = ERROR
log4j.appender.E.layout = org.apache.log4j.PatternLayout
log4j.appender.E.layout.ConversionPattern =%-d{yyyy-MM-dd HH\:mm\:ss} [ %t\:%r ] - [ %p ] %m%n
Log4j输出源配置大全

如何在项目里使用Log4j
实现步骤:
- 创建一个工程
- 引入Log4j jar包
- 在src目录下引入log4j的属性配置文件
配置文件:
###设置 ###
log4j.rootLogger = info,stdout,D,E
###输出信息到控制抬 ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target = System.out
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = [%-5p] %d{yyyy-MM-dd HH:mm:ss,SSS} method:%l%n%m%n
###输出 ERROR 级别以上的日志到 =E://logs/error.log ###
log4j.appender.E = org.apache.log4j.DailyRollingFileAppender
log4j.appender.E.File =E://logs/error.log
log4j.appender.E.Append = true
log4j.appender.E.Threshold = ERROR
log4j.appender.E.layout = org.apache.log4j.PatternLayout
log4j.appender.E.layout.ConversionPattern =%-d{yyyy-MM-dd HH\:mm\:ss} [ %t\:%r ] - [ %p ] %m%n
4.在代码里通过Log4j API 进行日志信息记录
代码示例:
public class AuthLg {
private static Logger log=Logger.getLogger(AuthLg.class);
public static void main(String[] args) {
log.debug("debug级别信息");
log.info("info级别信息");
log.warn("warn级别信息");
log.error("erro错误信息");
log.fatal("fatal级别信息");
}
}
离线业务系统搭建
我们现在要搭建 数据从flume-hdfs
实现步骤
- 启动hadoop
- 配置flume
配置示例:
a1.sources=r1
a1.channels=c1
a1.sinks=k1
a1.sources.r1.type=avro
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=44444
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.i1.type=timestamp
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=hdfs://192.168.234.21:9000/weblog/reportTime=%Y-%m-%d
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.rollInterval=30
a1.sinks.k1.hdfs.rollSize=0
a1.sinks.k1.hdfs.rollCount=1000
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
- 启动flume
hive做离线数据处理
实现步骤
- 启动hive
进入hive的bin目录
执行:./hive
2 .创建数据库
hive>create database weblog;
3.创建外部分区表管理数据
>use weblog;
>create external table flux (url string,urlname string,title string,chset string,scr string,col string,lg string,je string,ec string,fv string,cn string,ref string,uagent string,stat_uv string,stat_ss string,cip string) PARTITIONED BY (reporttime string) row format delimited fields terminated by '|' location '/weblog';
切分函数:select split (name,”,”)[1] from taba
>alter table flux add partition (reportTime='2018-09-02') location '/weblog/reportTime=2018-09-02';
4.建立数据清洗表: dataclear 指定的分割符 : |
去除多余字段,只保留需要的字段,并将会话信息拆开保存
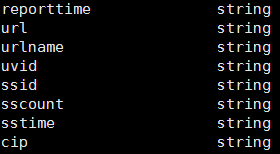
所需要的字段为:
reporttime、url、urlname、uvid、ssid、sscount、sstime、cip
5.建立完dataclear之后,需要从flux(总表中)将相关字段的值插入到dataclear表。
线索:会用到hive的内置函数:split 函数 ——比如:select split("hello,world",",")[1];
>create table dataclear(reportTime string,url string,urlname string,uvid string,ssid string,sscount string,sstime string,cip string)row format delimited fields terminated by '|';
>insert overwrite table dataclear
select reporttime,url,urlname,stat_uv,split(stat_ss,"_")[0],split(stat_ss,"_")[1],split(stat_ss,"_")[2],cip from flux;
要求:
①统计pv(页面访问量)用户每次访问,就算一个pv
②统计UV(独立访客数)提示:我们是根据uvid来标识一个用户的
5.业务处理
1)pv
hive>select count(*) as pv from dataclear where reportTime = '2018-04-16';
2)uv
uv - 独立访客数 - 一天之内所有的访客的数量 - 一天之内uvid去重后的总数
hive>select count(distinct uvid) as uv from dataclear where reportTime = '2018-04-16';
3)vv
vv - 独立会话数 - 一天之内所有的会话的数量 - 一天之内ssid去重后的总数
hive>select count(distinct ssid) as vv from dataclear where reportTime = '2018-03-26';
4)br
br - 跳出率 - 一天内跳出的会话总数/会话总数
hive>
select round(br_taba.a/br_tabb.b,4)as br from (select count(*) as a from (select ssid from dataclear where reportTime='2018-07-02' group by ssid having count(ssid) = 1) as br_tab) as br_taba,(select count(distinct ssid) as b from dataclear where reportTime='2018-07-02') as br_tabb;
5)newip
newip - 新增ip总数 - 一天内所有ip去重后在历史数据中从未出现过的数量
hive>select count(distinct dataclear.cip) from dataclear where dataclear.reportTime = '2018-10-15'
and cip not in
(select dc2.cip from dataclear as dc2 where dc2.reportTime < '2018-10-15');
6)newcust
newcust - 新增客户数 - 一天内所有的uvid去重后在历史数据中从未出现过的总数
hive>select count(distinct dataclear.uvid) from dataclear where dataclear.reportTime='2018-10-15'
and uvid not in
(select dc2.uvid from dataclear as dc2 where dc2.reportTime < '2018-10-15');
7)avgtime
avgtime - 平均访问时常 - 一天内所有会话的访问时常的平均值
注: 一个会话的时长 = 会话中所有访问的时间的最大值 - 会话中所有访问时间的最小值
hive>select avg(atTab.usetime) as avgtime from
(select max(sstime) - min(sstime) as usetime from dataclear where reportTime='2018-10-15' group by ssid) as atTab;
8)avgdeep
avgdeep - 平均访问深度 - 一天内所有会话访问深度的平均值
一个会话的访问深度=一个会话访问的所有url去重后的个数
比如会话①:url http://demo/a.jsp http://demo/b.jsp http://demo/a.jsp 则访问深度是2
hive>select round(avg(adTab.deep),4) as avgdeep from
(select count(distinct urlname) as deep from dataclear where reportTime='2018-10-15' group by ssid) as adTab;
创建业务表并插入数据
hive> create table tongji(reportTime string,pv int,uv int,vv int, br double,newip int, newcust int, avgtime double,avgdeep double) row format delimited fields terminated by '|';
hive>
insert overwrite table tongji select '2018-07-02',tab1.pv,tab2.uv,tab3.vv,tab4.br,tab5.newip,tab6.newcust,tab7.avgtime,tab8.avgdeep from
(select count(*) as pv from dataclear where reportTime = '2018-07-02') as tab1,
(select count(distinct uvid) as uv from dataclear where reportTime = '2018-07-02') as tab2,
(select count(distinct ssid) as vv from dataclear where reportTime = '2018-07-02') as tab3,
(select round(br_taba.a/br_tabb.b,4)as br from (select count(*) as a from (select ssid from dataclear where reportTime='2018-07-02' group by ssid having count(ssid) = 1) as br_tab) as br_taba,
(select count(distinct ssid) as b from dataclear where reportTime='2018-07-02') as br_tabb) as tab4,
(select count(distinct dataclear.cip) as newip from dataclear where dataclear.reportTime = '2018-07-02' and cip not in (select dc2.cip from dataclear as dc2 where dc2.reportTime < '2018-07-02')) as tab5,
(select count(distinct dataclear.uvid) as newcust from dataclear where dataclear.reportTime='2018-07-02' and uvid not in (select dc2.uvid from dataclear as dc2 where dc2.reportTime < '2018-07-02')) as tab6,
(select round(avg(atTab.usetime),4) as avgtime from (select max(sstime) - min(sstime) as usetime from dataclear where reportTime='2018-07-02' group by ssid) as atTab) as tab7,
(select round(avg(deep),4) as avgdeep from (select count(distinct urlname) as deep from dataclear where reportTime='2018-07-02' group by ssid) as adTab) as tab8;
利用Sqoop工具从HDFS上将数据导入到Mysql数据库中
Mysql建表语句:
create table tongji(reportTime varchar(40),pv int,uv int,vv int,br double,newip int,newcust int,avgtime double,avgdeep double);
Sqoop:
sh sqoop export --connect jdbc:mysql://192.168.150.137:3306/weblog --username root --password root --export-dir '/user/hive/warehouse/weblog.db/tongji' --table tongji -m 1 --fields-terminated-by '|'
Hive的占位符与文件的调用
概述
对于上述的工作,我们发现需要手动去写hql语句从而完成离线数据的ETL,但每天都手动来做显然是不合适的,所以可以利用hive的文件调用与占位符来解决这个问题。
Hive文件的调用
实现步骤:
1)编写一个文件,后缀名为 .hive,
比如我们现在我们创建一个01.hive文件
目的是在 hive的weblog数据库下,创建一个tb1表
01.hive 文件编写示例:
use weblog;
create table tb1 (id int,name string);
2)进入hive安装目录的bin目录
执行: sh hive -f 01.hive
注:-f 参数后跟的是01.hive文件的路径
3)测试hive的表是否创建成功
Hive占位符的使用
我们现在想通过hive执行文件,将 "tb1"这个表删除
则我们可以这样做
1)创建02.hive文件
编写示例:
use weblog;
drop table ${tb_name}
2)在bin目录下,执行:
sh hive -f 02.hive -d tb_name="tb1"
结合业务的实现
在hive最后插入数据时,涉及到一个日志的分区是以每天为单位,所以我们需要手动去写这个日期,比如 2017-8-20。
现在,我们学习了Hive文件调用和占位符之后,我们可以这样做
1)将hql语句里的日期相关的取值用占位符来表示,并写在weblog.hive文件里
编写示例:
use weblog;
insert overwrite table tongji select ${reportTime},tab1.pv,tab2.uv,tab3.vv,tab4.br,tab5.newip,tab6.newcust,tab7.avgtime,tab8.avgdeep from (select count(*) as pv from dataclear where reportTime = ${reportTime}) as tab1,(select count(distinct uvid) as uv from dataclear where reportTime = ${reportTime}) as tab2,(select count(distinct ssid) as vv from dataclear where reportTime = ${reportTime}) as tab3,(select round(br_taba.a/br_tabb.b,4)as br from (select count(*) as a from (select ssid from dataclear where reportTime=${reportTime} group by ssid having count(ssid) = 1) as br_tab) as br_taba,(select count(distinct ssid) as b from dataclear where reportTime=${reportTime}) as br_tabb) as tab4,(select count(distinct dataclear.cip) as newip from dataclear where dataclear.reportTime = ${reportTime} and cip not in (select dc2.cip from dataclear as dc2 where dc2.reportTime < ${reportTime})) as tab5,(select count(distinct dataclear.uvid) as newcust from dataclear where dataclear.reportTime=${reportTime} and uvid not in (select dc2.uvid from dataclear as dc2 where dc2.reportTime < ${reportTime})) as tab6,(select round(avg(atTab.usetime),4) as avgtime from (select max(sstime) - min(sstime) as usetime from dataclear where reportTime=${reportTime} group by ssid) as atTab) as tab7,(select round(avg(deep),4) as avgdeep from (select count(distinct urlname) as deep from dataclear where reportTime=${reportTime} group by ssid) as adTab) as tab8;
2.在hive 的bin目录下执行:
sh hive -f weblog.hive -d reportTime="2017-8-20"
对于日期,如果不想手写的话,可以通过linux的指令来获取:
> date "+%G-%m-%d"
所以我们可以这样来执行hive文件的调用:
>sh hive -f 03.hive -d reportTime=date “+%G-%m-%d” (注:是键盘左上方的反引号)
也可以写为:
sh hive -f 03.hive -d reportTime=$(date "+%G-%m-%d")
Linux Crontab 定时任务
在工作中需要数据库在每天零点自动备份所以需要建立一个定时任务。
crontab命令的功能是在一定的时间间隔调度一些命令的执行。
可以通过 crontab -e 进行定时任务的编辑
crontab文件格式:
-
* * * * command
minute hour day month week command
分 时 天 月 星期 命令

0 0 * * * ./home/software/hive/bin/hive -f /home/software/hive/bin/03.hive -d reportTime=`
date %G-%y-%d`
每隔1分钟,执行一次任务
编写示例:
*/1 * * * * rm -rf /home/software/1.txt
每隔一分钟,删除指定目录的 1.txt文件