Linux nc安装
Linux nc 介绍和安装使用
NetCat,在网络工具中有“瑞士军刀”美誉,其有Windows和Linux的版本。因为它短小精悍(1.84版本也不过25k,旧版本或缩减版甚至更小)、功能实用,被设计为一个简单、可靠的网络工具,可通过TCP或UDP协议传输读写数据。同时,它还是一个网络应用Debug分析器,因为它可以根据需要创建各种不同类型的网络连接。
安装方法一:在线安装
1.如果是在线安装,则执行:
wget http://sourceforge.NET/projects/netcat/files/netcat/0.7.1/netcat-0.7.1-1.i386.rpm
如果是离线安装,先从下载地址: http://sourceforge.net/projects/netcat/files/netcat/0.7.1/netcat-0.7.1-1.i386.rpm/download
下载nc的rpm包,然后上传到虚拟机上。
2.执行:rpm -ihv netcat-0.7.1-1.i386.rpm
如果出现:
warning: netcat-0.7.1-1.i386.rpm: Header V3 DSA/SHA1 Signature, key ID b2d79fc1: NOKEY
error: Failed dependencies:
libc.so.6 is needed by netcat-0.7.1-1.i386
libc.so.6(GLIBC_2.0) is needed by netcat-0.7.1-1.i386
libc.so.6(GLIBC_2.1) is needed by netcat-0.7.1-1.i386
libc.so.6(GLIBC_2.3) is needed by netcat-0.7.1-1.i386
说明还需要安装nc的依赖软件包:glibc
3.通过yum源查看glibc相关的资源列表(需要联网),执行:yum list glibc*
如果在yum安装时,报错404错误,说明当前默认yum源连接不可用(一般默认是用国外的yum源),所以,需要更换yum源,换成国内的yum源。
4.通过yum安装glibc,执行:yum install glibc.i686
Preparing... ########################################### [100%]
1:netcat ########################################### [100%]
5.安装netcat包,执行:rpm -ihv netcat-0.7.1-1.i386.rpm
Preparing... ########################################### [100%]
1:netcat ########################################### [100%]
再次测试zookeeper的四字命令,会发现成功。
安装方法二:yum安装(推荐)
执行:
yum install -y nc
会自动将nc 以及依赖环境都安装完毕
Linux—Yum介绍
Yum(全称为 Yellow dog Updater, Modified)是一个Linux的Shell前端软件包管理器。基于RPM包管理,能够从指定的服务器自动下载RPM包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软件包,无须繁琐地一次次下载、安装。
Linux—RPM介绍
RPM包:可以在linux环境下被安装或被卸载的程序软件包。通过Linux的 rpm指令来进行安装或卸载。
rpm常用指令:
1.rpm -qa 查看所有已安装的rpm包
2.rpm -qa | grep xxx 根据xxx关键字查找rpm的安装信息
3.rpm -ivh xxx.rpm 安装某个rpm包
4.rpm -ev --nodeps mysql-libs-5.1.71-1.el6.x86_64
Linux—更换yum源
网易yum源比较常用,拿网易yum源举例
实现步骤:
1.进入yum源配置目录
执行:cd /etc/yum.repos.d
2.备份系统自带的yum源
执行:mv CentOS-Base.repo CentOS-Base.repo.bk
3.下载网易的yum源(需要联网):
执行:wget http://mirrors.163.com/.help/CentOS6-Base-163.repo
4.下载完yum源后,执行下边命令更新yum配置,使操作立即生效
执行:yum makecache (这个时间会很长)
除了网易之外,国内还有其他不错的yum源,比如中科大和搜狐的
中科大的yum源:
wget http://centos.ustc.edu.cn/CentOS-Base.repo
sohu的yum源
wget http://mirrors.sohu.com/help/CentOS-Base-sohu.repo
Zookeeper集群指令
Zookeeper集群命令
可以通过Linux nc 工具来查看Zookeeper集群服务状态(掌握3个即可)
-
执行:echo stat|nc 127.0.0.1 2181
查看哪个节点(想看哪个节点,就写那个节点的ip即可)被选择作为follower或者leader
Clients:
/127.0.0.1:407430
Latency min/avg/max: 0/0/0
Received: 2
Sent: 1
Connections: 1
Outstanding: 0
Zxid: 0x500000002
Mode: follower
Node count: 8 -
执行:echo ruok|nc 127.0.0.1 2181
测试是否启动了该Server,若回复imok表示已经启动。 -
echo conf | nc 127.0.0.1 2181 ,输出相关服务配置的详细信息。
clientPort=2181
dataDir=/home/software/zookeeper-3.4.7/tmp/version-2
dataLogDir=/home/software/zookeeper-3.4.7/tmp/version-2
tickTime=2000
maxClientCnxns=60
minSessionTimeout=4000
maxSessionTimeout=40000
serverId=1
initLimit=10
syncLimit=5
electionAlg=3
electionPort=3888
quorumPort=2888
peerType=0 -
echo kill | nc 127.0.0.1 2181 ,关掉server
-
echo dump| nc 127.0.0.1 2181 ,列出未经处理的会话和临时节点。
-
echo cons | nc 127.0.0.1 2181 ,列出所有连接到服务器的客户端的完全的连接 / 会话的详细信息。
-
echo envi |nc 127.0.0.1 2181 ,输出关于服务环境的详细信息(区别于 conf 命令)。
-
echo reqs | nc 127.0.0.1 2181 ,列出未经处理的请求。
-
echo wchs | nc 127.0.0.1 2181 ,列出服务器 watch 的详细信息。
-
echo wchc | nc 127.0.0.1 2181 ,通过 session 列出服务器 watch 的详细信息,它的输出是一个与 watch 相关的会话的列表。
-
echo wchp | nc 127.0.0.1 2181 ,通过路径列出服务器 watch 的详细信息。它输出一个与 session 相关的路径。
Zookeeper配置详解

2PC算法
分布式下的数据一致性问题
对于一个将数据副本分布在不同分布式节点上的系统来说,如果对第一个节点的数据进行了更新操作并且更新成功后,却没有使得第二个节点上的数据得到相应的更新,于是在对第二个节点的数据进行读取操作时,获取的依然是老数据(或称为脏数据),这就是典型的分布式数据不一致情况。
为了解决分布式一致性问题,在长期的探索研究过程中,涌现出了一大批经典的一致性协议和算法,其中最著名的就是二阶段提交协议、三阶段提交协议和Paxos算法。
2PC
2PC,是Two-Phase Commit的缩写,即二阶段提交,是计算机网络尤其是在数据库领域内,为了使基于分布式系统架构下的所有节点在进行事务处理过程中能够保持原子性和一致性而设计的一种算法。通常,二阶段提交协议也被认为是一种一致性协议,用来保证分布式系统数据的一致性。目前,绝大部分的关系型数据库都是采用二阶段提交协议来完成分布式事务处理的,利用该协议能够非常方便地完成所有分布式事务参与者的协调,统一决定事务的提交或回滚,从而能够有效地保证分布式数据一致性,因此二阶段提交协议被广泛地应用在许多分布式系统中。
提交过程
二阶段提交协议是将事务的提交过程分成了两个阶段来进行处理,其执行流程如下。
阶段一:提交事务请求+执行事务
- 事务询问。
协调者向所有的参与者发送事务内容,询问是否可以执行事务提交操作,并开始等待各参与者的响应。 - 执行事务。
各参与者节点执行事务操作,并将Undo和Redo信息记入事务日志中。 - 各参与者向协调者反馈事务询问的响应。
如果参与者成功执行了事务操作,那么就反馈给协调者Yes响应,表示事务可以执行;如果参与者没有成功执行事务,那么就反馈给协调者No响应,表示事务不可以执行。
由于上面讲述的内容在形式上近似是协调者组织各参与者对一次事务操作的投票表态过程,因此二阶段提交协议的阶段一也被称为“投票阶段”,即各参与者投票表明是否要继续执行接下去的事务提交操作。
阶段二:事务提交
在阶段二中,协调者会根据各参与者的反馈情况来决定最终是否可以进行事务提交操作,正常情况下,包含以下两种可能。
执行事务提交
假如协调者从所有的参与者获得的反馈都是Yes响应,那么就会执行事务提交。
- 发送提交请求。
协调者向所有参与者节点发出Commit请求。 - 事务提交。
参与者接收到Commit请求后,会正式执行事务提交操作,并在完成提交之后释放在整个事务执行期间占用的事务资源。 - 反馈事务提交结果。
参与者在完成事务提交之后,向协调者发送Ack消息。 - 完成事务。
协调者接收到所有参与者反馈的Ack消息后,完成事务。
中断事务
假如任何一个参与者向协调者反馈了No响应,或者在等待超时之后,协调者尚无法接收到所有参与者的反馈响应,那么就会中断事务。 - 发送回滚请求。
协调者向所有参与者节点发出Rollback请求。 - 事务回滚。
参与者接收到Rollback请求后,会利用其在阶段一中记录的Undo信息来执行事务回滚操作,并在完成回滚之后释放在整个事务执行期间占用的资源。 - 反馈事务回滚结果。
参与者在完成事务回滚之后,向协调者发送Ack消息。 - 中断事务。
协调者接收到所有参与者反馈的Ack消息后,完成事务中断。
以上就是二阶段提交过程中,前后两个阶段分别进行的处理逻辑。简单地讲,二阶段提交将一个事务的处理过程分为了投票和执行两个阶段,其核心是对每个事务都采用先尝试后提交的处理方式,因此也可以将二阶段提交看作一个强一致性的算法,下图分别展示了二阶段提交过程中“事务提交”和“事务中断”两种场景下的交互流程。

优缺点
二阶段提交协议的优点:原理简单,实现方便。
二阶段提交协议的缺点:同步阻塞、单点问题、脑裂、太过保守。
如果一个管理集群中,同时出现2个Leader或多个Leader,称为脑裂现象
同步阻塞
二阶段提交协议存在的最明显也是最大的一个问题就是同步阻塞,这会极大地限制分布式系统的性能。在二阶段提交的执行过程中,所有参与该事务操作的逻辑都处于阻塞状态,也就是说,各个参与者在等待其他参与者响应的过程中,将无法进行其他任何操作。
单点问题
在上面的讲解过程中,相信读者可以看出,协调者的角色在整个二阶段提交协议中起到了非常重要的作用。一旦协调者出现问题,那么整个二阶段提交流程将无法运转,更为严重的是,如果协调者是在阶段二中出现问题的话,那么其他参与者
太过保守
如果在协调者指示参与者进行事务提交询问的过程中,参与者出现故障而导致协调者始终无法获取到所有参与者的响应信息的话,这时协调者只能依靠其自身的超时机制来判断是否需要中断事务,这样的策略显得比较保守。换句话说,二阶段提交协议没有设计较为完善的容错机制,任意一个节点的失败都会导致整个事务的失败。
Paxos算法

Leslie B. Lamport is an American computer scientist. Lamport is best known for his seminal work in distributed systems and as the initial developer of the document preparation system LaTeX. Leslie Lamport was the winner of the 2013 Turing Award for imposing clear, well-defined coherence on the seemingly chaotic behavior of distributed computing systems, in which several autonomous computers communicate with each other by passing messages. He devised important algorithms and developed formal modeling and verification protocols that improve the quality of real distributed systems. These contributions have resulted in improved correctness, performance, and reliability of computer systems.
Read more about Leslie Lamport’s extensive work and publication archive at: www.lamport.org.
Leslie Lamport(莱斯利·兰伯特)
Paxos算法的作者Leslie Lamport(莱斯利·兰伯特)及其对计算机科学尤其是分布式计算领域的杰出贡献。作为2013年的新科图灵奖得主,现年73岁的Lamport是计算机科学领域一位拥有杰出成就的传奇人物,其先后多次荣获ACM和IEEE以及其他各类计算机重大奖项。Lamport对时钟同步算法、面包店算法、拜占庭将军问题以及Paxos算法的创造性研究,极大地推动了计算机科学尤其是分布式计算的发展,全世界无数工程师得益于他的理论,其中Paxos算法的提出,正是Lamport多年的研究成果。
说起Paxos理论的发表,还有一段非常有趣的历史故事。Lamport早在1990年就已经将其对Paxos算法的研究论文The Part-Time Parliament提交给ACM TOCS Jnl.的评审委员会了,但是由于Lamport“创造性”地使用了故事的方式来进行算法的描述,导致当时委员会的工作人员没有一个能够正确地理解他对算法的描述,时任主编要求Lamport使用严谨的数据证明方式来描述该算法,否则他们将不考虑接受这篇论文。遗憾的是,Lamport并没有接收他们的建议,当然也就拒绝了对论文的修改,并撤销了对这篇论文的提交。在后来的一个会议上,Lamport还对此事耿耿于怀:“为什么这些搞理论的人一点幽默感也没有呢?”
幸运的是,还是有人能够理解Lamport那公认的令人晦涩的算法描述的。1996年,来自微软的Butler Lampson在WDAG96上提出了重新审视这篇分布式论文的建议,在次年的WDAG97上,麻省理工学院的Nancy Lynch也公布了其根据Lamport的原文重新修改后的Revisiting the Paxos Algorithm,“帮助”Lamport用数学的形式化术语定义并证明了Paxos算法。于是在1998年的ACM TOCS上,这篇延迟了9年的论文终于被接受了,也标志着Paxos算法正式被计算机科学接受并开始影响更多的工程师解决分布式一致性问题。
后来在2001年,Lamport本人也做出了让步,这次他放弃了故事的描述方式,而是使用了通俗易懂的语言重新讲述了原文,并发表了Paxos Made Simple——当然,Lamport甚为固执地认为他自己的表述语言没有歧义,并且也足够让人明白Paxos算法,因此不需要数学来协助描述,于是整篇文章还是没有任何数学符号。好在这篇文章已经能够被更多的人理解,相信绝大多数的Paxos爱好者也都是从这篇文章开始慢慢进入了Paxos的神秘世界。
由于Lamport个人自负固执的性格,使得Paxos理论的诞生可谓一波三折。关于Paxos理论的诞生过程,后来也成为了计算机科学领域被广泛流传的学术趣事。
拜占庭将军问题的提出
1982年,Lamport与另两人共同发表了论文The Byzantine Generals Problem,提出了一种计算机容错理论。在理论描述过程中,为了将所要描述的问题形象的表达出来,Lamport设想出了下面这样一个场景:
拜占庭帝国有许多支军队,不同军队的将军之间必须制订一个统一的行动计划,从而做出进攻或者撤退的决定,同时,各个将军在地理上都是被分隔开来的,只能依靠军队的通讯员来进行通讯。然而,在所有的通讯员中可能会存在叛徒,这些叛徒可以任意篡改消息,从而达到欺骗将军的目的。
这就是著名的“拜占庭将军问题”。实际上拜占庭将军问题是一个分布式环境下的协议问题,拜占庭帝国军队的将军们必须全体一致的决定是否攻击某一支敌军。
Paxos算法的诞生
Lamport在1990年提出了一个理论上的一致性解决方案,同时给出了严格的数学证明。鉴于之前采用故事类比的方式成功的阐述了“拜占廷将军问题”,因此这次Lamport同样用心良苦地设想出了一个场景来描述这种一致性算法需要解决的问题,及其具体的解决过程:
在古希腊有一个叫做Paxos的小岛,岛上采用议会的形式来通过法令,议会中的议员通过信使进行消息的传递。值得注意的是,议员和信使都是兼职的,他们随时有可能会离开议会厅,并且信使可能会重复的传递消息,也可能一去不复返。因此,议会协议要保证在这种情况下法令仍然能够正确的产生,并且不会出现冲突。
这就是论文The Part-Time Parliament中提到的兼职议会,而Paxos算法名称的由来也是取自论文中提到的Paxos小岛。在这个论文中,Lamport压根没有说Paxos小岛是虚构出来的,而是煞有介事的说是考古工作者发现了Paxos议会事务的手稿,从这些手稿猜测Paxos人开展议会的方法。因此,在这个论文中,Lamport从问题的提出到算法的推演论证,通篇贯穿了对Paxos议会历史的描述。
算法陈述
Paxos算法实际上也是一个类2pc算法,而重点是引入了“过半性”的投票理念,通俗地讲就是少数服从多数的原则。此外,Paxos算法支持分布式节点角色之间的轮换,即当协调者出现问题后,参与者可以变成协调者工作。这极大地避免了分布式单点的出现,因此Paxos算法既解决了无限期等待问题,也提高了性能,是目前来说最优秀的分布式一致性协议之一。
zookeeper底层是基于paxos算法来改进。zookeeper用的 fast paxos算法。paxos算法可能会引起活锁问题。《The chubby lock service for loosely coupled for distributed system》
课外阅读
论文下载地址:
https://www.microsoft.com/en-us/research/publication/paxos-made-simple/?from=http%3A%2F%2Fresearch.microsoft.com%2Fen-us%2Fum%2Fpeople%2Flamport%2Fpubs%2Fpaxos-simple.pdf

Zookeeper观察者
观察者
在不影响写入性能的情况下缩放Zookeeper
虽然客户端直接连接到投票选举的Zookeeper成员执行良好,但这个架构很难扩展到大量的客户端。问题就是因为我么添加了更多的投票成员,写入性能下降。这是由于这样的事实:一个写入操作要求共识协议至少是整体的一半,因此投票的成本随着投票者越多会显著增加。
我们引入了一个新的Zookeeper节点类型叫做Observer,它帮助处理这个问题并进一步完善了Zookeeper的可扩展性。观察者不参与投票,它只监听投票的结果,不是导致了他们的共识协议。除了这个简单的区别,观察者精确的和追随者一样运行 - 客户端可能链接他们并发送读取和写入请求。观察者像追随者一样转发这些请求到领导者,而他们只是简单的等待监听投票的结果。正因为如此,我们可以尽可能多的增加观察者的数量,而不影响投票的性能。
观察这还有其他优势。因为他们不投票,他们不是Zookeeper整体的主要组件。因此他们可以故障,或者从集群断开连接,而不影响Zookeeper服务的可用性。对用户的好处是观察者可以连接到比追随者更不可靠的网络。事实上,观察者可以用于从其他数据中心和Zookeeper服务通信。观察者的客户端会看到快速的读取,因为所有的读取都在本地,并且写入导致最小的网络开销,因为投票协议所需的消息数量更小。
怎么使用观察者
使用观察者设置Zookeeper全员非常简单,只需要在原来的配置文件上改两个地方。第一,在要设置的那个节点的配置文件设置为观察者,必须放置这一行:
peerType=observer

Zookeeper插件

Zookeeper特性
数据一致性
client不论连接到哪个Zookeeper,展示给它都是同一个视图,即查询的数据都是一样的。这是zookeeper最重要的性能。
原子性
对于事务决议的更新,只能是成功或者失败两种可能,没有中间状态。要么都更新成功,要么都不更新。即,要么整个集群中所有机器都成功应用了某一事务,要么都没有应用,一定不会出现集群中部分机器应用了改事务,另外一部分没有应用的情况。
可靠性
一旦服务端成功的应用了一个事务,并完成对客户端的响应,那么该事务所引起的服务端状态变更将会一直保留下来,除非有另一个事务又对其进行了改变。
实时性
Zookeeper保证客户端将在非常短的时间间隔范围内获得服务器的更新信息,或者服务器失效的信息,或者指定监听事件的变化信息。(前提条件是:网络状况良好)
顺序性
如果在一台服务器上消息a在消息b前发布,则在所有Server上消息a都将在消息b前被发布。
过半性
zookeeper集群必须有半数以上的机器存活才能正常工作。因为只有满足过半数,才能满足选举机制选出Leader。因为只有过半,在做事务决议时,事务才能更新
Java原生序列化和反序列化
序列化
Person对象代码(注意要实现Serializable接口):
public class Person implements Serializable{
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
测试代码:
/*这个方法是测试Person对象序列化的,利用的是java提供的原生序列化机制
*主要掌握的是ObjectOutputStream.writeObject()方法
*需要注意的是被序列化的对象要实现Serializabel接口
*/
public void testSerialize01() throws Exception{
Person p=new Person();
p.setAge(23);
p.setName("jary");
ObjectOutputStream oos=new ObjectOutputStream(new FileOutputStream("person.data"));
oos.writeObject(p);
oos.flush();
oos.close();
}
反序列化
测试代码:
/*这个方法是测试Person对象反序列化的,利用的是java原生提供的反序列
* 需要掌握的是ObjectInputStream.readObject()方法
*/
@Test
public void testDeserialize01() throws Exception{
ObjectInputStream ois=new ObjectInputStream(new FileInputStream("person.data"));
Person p =(Person) ois.readObject();
System.out.println(p.getAge());
System.out.println(p.getName());
}
三、SerializableId的作用
测试代码:
/*
* 这个方法是测试SerializeId的作用
* 当Person对象序列化完毕后,如果更改Person类的结构,比如新增一个私有属性等,再次反序列化时会报错。
* 原因是:当序列化时,会自动生成一个SerializeId,反序列化时,也会生成一个SerializeId,如果更改了Person对 象会导致两个SerializeId不一样,从而反序列化失败。
* 所以解决办法是:手动加上SerializeId
*/
@Test
public void testSerializeId() throws Exception{
ObjectInputStream ois=new ObjectInputStream(new FileInputStream("person.data"));
Person p =(Person) ois.readObject();
System.out.println(p.getAge());
System.out.println(p.getName());
}
Person代码:
public class Person implements Serializable{
private static final long serialVersionUID = 1500208610485192912L;
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
四、SerializableId的作用
在某些场景下,对于某些字段我们不想序列化,出于安全的角度,比如密码。此时,我们就可以用transient关键字,在序列化时忽略此字段。
示例代码:
public class Person implements Serializable{
private static final long serialVersionUID = 1500208610485192912L;
private String name;
private int age;
private transient String password;
五、总结Java原生序列化
1.java原生序列化在实际开发中用的非常少,因为序列化完后的数据文件很大。
2.不能跨语言。java序列化后的数据文件,不能用c语言或其他语言还原回来
3.速度慢
4.java的序列化机制在每个类的对象第一次出现的时候保存了每个类的信息, 比如类名, 第二次出现的类对象会有一个类的reference, 导致空间的浪费
5.有成千上万(打个比方,不止这么多)的对象要反序列化, 而java序列化机制不能复用对象, java反序列化的时候, 每次要构造出新的对象. 在hadoop的序列化机制中, 反序列化的对象是可以复用的.

五、开源的序列化框架
Google: google protobuffer
Apache: AVRO
facebook: thrift
zookeeper的应用场景
统一命名服务(Name Service)
分布式应用中,通常需要有一套完整的命名规则,既能够产生唯一的名称又便于人识别和记住, 就像数据库中产生一个唯一的数字主键一样。我们利用Zookeeper 可以轻松实现这一功能——利用znode路径。因为znode路径是全局唯一的。
集群管理
通过zookeeper知道集群里机器的状态,实现思路:集群里每台机器都在zookeeper里注册自己的临时节点,并上传自己的运行状态,我们可以查看这些临时节点,来得知节点的数据信息,加入某个临时节点消失了,意味着这台节点挂掉了,从而也可以达到集群监控的目的。
数据订阅发布
这个最典型的就是集群配置信息要发布到集群的客户机节点上,实现配置信息的集中式管理和动态更新。
配置管理(Configuration Management)
配置的管理在分布式应用环境中很常见,例如同一个应用系统需要多台 PC Server 运行,但是它们运行的应用系统的某些配置项是相同的,如果要修改这些相同的配置项,那么就必须同时修改每台运行这个应用系统的 PC Server,这样非常麻烦而且容易出错。
像这样的配置信息完全可以交给 Zookeeper 来管理,将配置信息保存在 Zookeeper 的某个目录节点中,然后将所有需要修改的应用机器监控配置信息的状态,一旦配置信息发生变化,每台应用机器就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中。
分布式同步协调通知
任务分配
负载均衡
分布式锁
分布式队列
所有客户端创建有序临时节点,创建节点后,其他节点可以根据顺序编号来取数据
简单互斥锁(Simple Lock)
我们知识,在传统的应用程序中,线程、进程的同步,都可以通过操作系统提供的机制来完成。但是在分布式系统中,多个进程之间的同步,操作系统层面就无能为力了。这时候就需要像ZooKeeper这样的分布式的协调(Coordination)服务来协助完成同步,下面是用ZooKeeper实现简单的互斥锁的步骤,这个可以和线程间同步的mutex做类比来理解:
多个进程尝试去在指定的目录下去创建一个临时性(Ephemeral)结点 /locks/my_lock
ZooKeeper能保证,只会有一个进程成功创建该结点,创建结点成功的进程就是抢到锁的进程,假设该进程为A
其它进程都对/locks/my_lock进行Watch
当A进程不再需要锁,可以显式删除/locks/my_lock释放锁;或者是A进程宕机后Session超时,ZooKeeper系统自动删除/locks/my_lock结点释放锁。此时,其它进程就会收到ZooKeeper的通知,并尝试去创建/locks/my_lock抢锁,如此循环反复
5. 互斥锁(Simple Lock without Herd Effect)
上一节的例子中有一个问题,每次抢锁都会有大量的进程去竞争,会造成羊群效应(Herd Effect),为了解决这个问题,我们可以通过下面的步骤来改进上述过程:
每个进程都在ZooKeeper上创建一个临时的顺序结点(Ephemeral Sequential) /locks/lock_${seq}
{seq}是ZooKeeper生成的Sequenctial Number)
其它进程都对只watch比它次小的进程对应的结点,比如2 watch 1, 3 watch 2, 以此类推
当前持锁者释放锁后,比它次大的进程就会收到ZooKeeper的通知,它成为新的持锁者,如此循环反复
这里需要补充一点,通常在分布式系统中用ZooKeeper来做Leader Election(选主)就是通过上面的机制来实现的,这里的持锁者就是当前的“主”。
读写锁(Read/Write Lock)
我们知道,读写锁跟互斥锁相比不同的地方是,它分成了读和写两种模式,多个读可以并发执行,但写和读、写都互斥,不能同时执行行。利用ZooKeeper,在上面的基础上,稍做修改也可以实现传统的读写锁的语义,下面是基本的步骤:
每个进程都在ZooKeeper上创建一个临时的顺序结点(Ephemeral Sequential) /locks/lock_${seq}
${seq}最小的一个或多个结点为当前的持锁者,多个是因为多个读可以并发
需要写锁的进程,Watch比它次小的进程对应的结点
需要读锁的进程,Watch比它小的最后一个写进程对应的结点
当前结点释放锁后,所有Watch该结点的进程都会被通知到,他们成为新的持锁者,如此循环反复
屏障(Barrier)
在分布式系统中,屏障是这样一种语义: 客户端需要等待多个进程完成各自的任务,然后才能继续往前进行下一步。下用是用ZooKeeper来实现屏障的基本步骤:
Client在ZooKeeper上创建屏障结点/barrier/my_barrier,并启动执行各个任务的进程
Client通过exist()来Watch /barrier/my_barrier结点
每个任务进程在完成任务后,去检查是否达到指定的条件,如果没达到就啥也不做,如果达到了就把/barrier/my_barrier结点删除
Client收到/barrier/my_barrier被删除的通知,屏障消失,继续下一步任务
双屏障(Double Barrier)
双屏障是这样一种语义: 它可以用来同步一个任务的开始和结束,当有足够多的进程进入屏障后,才开始执行任务;当所有的进程都执行完各自的任务后,屏障才撤销。下面是用ZooKeeper来实现双屏障的基本步骤:
进入屏障:
Client Watch /barrier/ready结点, 通过判断该结点是否存在来决定是否启动任务
每个任务进程进入屏障时创建一个临时结点/barrier/process/
{process_id}
数据序列化
数据序列化(Serialization)
数据序列化就是将对象或者数据结构转化成特定的格式,使其可在网络中传输,或者可存储在内存或者文件中。反序列化则是相反的操作,将对象从序列化数据中还原出来。
而数据序列化后的数据格式可以是二进制,可以是XML,也可以是JSON等任何格式。
我们要明确的是:数据序列化的重点在于数据的交换和传输。
序列化的关注点/衡量标准
1.序列化后的数据大小
因为序列化后的字节流(二进制数据)通常是通过网络进行传输的,因此序列化后的内容越少传输耗时也就越短
2.序列化和反序列化的耗时及占用的cpu
3.是否支持跨语言,跨平台
在异构的网络系统中,网络通信双方可能是不同的语言,比如一端是Java,另一端是C。或者一端是Windows操作系统,另一端是Linux操作。
你可以这样理解:假设你传递的是字符串,没有问题,所有的机器都可以识别正常的字符串。
那么现在假设你传递的参数是一个 Java 对象,比如叫 cat。服务器并没有那么智能,它并不会知道你传递的是一个 Java 对象,而不是其他类型的数据,它识别不了 Java 对象。
因为Java 对象本质上是 class 字节码,服务器并不能根据这个字节码识别出该 Java 对象。所以,要提供一个公共的格式,不仅 Windows 能识别,你的服务器也能识别的公共的格式。
AVRO介绍

Introduction
Apache Avro™ is a data serialization system.
Avro provides:
Rich data structures.
A compact, fast, binary data format.
A container file, to store persistent data.
Remote procedure call (RPC).
Simple integration with dynamic languages. Code generation is not required to read or write data files nor to use or implement RPC protocols. Code generation as an optional optimization, only worth implementing for statically typed languages.
Avro是一个数据序列化框架(系统),提供了:
1.丰富的数据结构类型,8种基本数据类型以及6种复杂类型
2.快速可压缩的二进制形式
3.提供容器文件用于持久化数据
4.远程过程调用RPC
5.简单的动态语言结合功能,Avro 和动态语言结合后,读写数据文件和使用 RPC 协议都不需要生成代码,而代码生成作为一种可选的优化只值得在静态类型语言中实现。
同类主流产品
Google的:Protobuffer
facebook的:Thrift
Google protobuffer
优点
1)二进制消息,性能好/效率高(空间和时间效率都很不错)
2)proto文件生成目标代码,简单易用
3)序列化反序列化直接对应程序中的数据类,不需要解析后在进行映射(XML,JSON都是这种方式)
4)支持向前兼容(新加字段采用默认值)和向后兼容(忽略新加字段),简化升级
5)支持多种语言(可以把proto文件看做IDL文件)
6)Netty等一些框架集成
Thrift
应用
Facebook的开源的日志收集系统(scribe: https://github.com/facebook/scribe)
淘宝的实时数据传输平台(TimeTunnel http://code.taobao.org/p/TimeTunnel/wiki/index)
Evernote开放接口(https://github.com/evernote/evernote-thrift)
Quora(http://www.quora.com/Apache-Thrift)
HBase( http://abloz.com/hbase/book.html#thrift )
…
优点
支持非常多的语言绑定
thrift文件生成目标代码,简单易用
消息定义文件支持注释
数据结构与传输表现的分离,支持多种消息格式
包含完整的客户端/服务端堆栈,可快速实现RPC
支持同步和异步通信
网络模型
https://blog.csdn.net/qq_33624952/article/details/79212500
https://jingyan.baidu.com/article/00a07f387b7e0682d028dce2.html
经典:https://www.cnblogs.com/lemo-/p/6391095.html
新:RPC
概述
RPC 的全称是 Remote Procedure Call 是一种进程间通信方式。它允许程序调用另一个地址空间(通常是共享网络的另一台机器上)的过程或函数,而不用程序员显式编码这个远程调用的细节。即程序员无论是调用本地的还是远程的,本质上编写的调用代码基本相同。
RPC 起源

Bruce Jay Nelson
Bruce Nelson graduated from Harvey Mudd College in 1974, and went on to earn a master’s in computer science from Stanford University in 1976, and a Ph.D. in computer science from Carnegie Mellon University in 1982. While pursuing his Ph.D., he worked at Xerox PARC where he developed the concept of Remote Procedure Call (RPC). He and his collaborator Andrew Birrell were awarded the 1994 Association for Computing Machinery (ACM) Software System Award for the work on RPC. In 1996 he joined Cisco Systems as Chief Science Officer。
布鲁斯·纳尔逊1974年毕业于哈维·穆德学院,1976年在斯坦福大学获得计算机科学硕士学位,1982年在卡内基梅隆大学获得计算机科学博士学位。在追求博士学位时,他开发了远程过程调用(RPC)的概念。他和他的合作者安德鲁·伯雷尔因在RPC方面的工作而获得了1994年ACM软件系统奖。1996他加入思科系统担任首席科学官。
在 Nelson 的论文 《Implementing Remote Procedure Calls》 中他提到了几点:
- 简单:RPC 概念的语义十分清晰和简单,这样建立分布式计算就更容易。
- 高效:过程调用看起来十分简单而且高效。
- 通用:在单机计算中过程往往是不同算法部分间最重要的通信机制。 通俗一点说,就是一般程序员对于本地的过程调用很熟悉,那么我们在通过网络做远程通信时,通过RPC 把远程调用做得和本地调用完全类似,那么就更容易被接受,使用起来也就毫无障碍。今天我们使用的 RPC 框架基本就是按这个目标来实现的。
RPC架构
The program structure we use for RPC is similar to that proposed in Nelson’s
thesis.It isbased on the concept of stubs.When making a remote call,fivepieces
of program are involved: the user, the user-stub, the RPC communications
package (known as RPCRuntime), the server-stub,and the server.Their relatidnship is shown in Figure 1. The user,the user-stub,and one instance of RPCRuntime execute in the caller machine; the server, the server-stub and another instance of RPCRuntime execute in the callee machine. When the user wishes to make a remote call.
it actually makes a perfectly normal local call which invokes a corresponding procedure in the user-stub. The user-stub is responsible for placing a specificationof the target procedure and the arguments into one or more packets and asking the RPCRuntime to transmit these reliablyto the callee machine. On receipt of these packets, the RPCRuntime in the callee machine passes them to the server-stub,The server-stub unpacks them and again makes a perfectly normal local call,which invokes the appropriate procedure in the server.Meanwhile, the callingprocess in the callermachine issuspended awaiting a result packet. When the callin the server completes, it returns to the serverstub and the results are passed back to the suspended process in the caller
machine. There they are unpacked and the user-stub returns them to the user
RPCRuntime is responsible for retransmissions, acknowledgments, packet routing, and encryption. Apart from the effects of multimachine binding and of
machine or communication failures, the call happens just as if the user had invoked the procedure in the server directly. Indeed, if the user and server code
were brought into a single machine and bound directly together without the
stubs, the program would still work.
用于RPC的程序结构类似于罗伊·尼尔森提出的程序结构。论文是基于存根的概念,涉及的模块有:
1)用户(User)
2)用户存根(User-Stub)
3)RPC通信包(称为RPCRuntime)
4)服务器存根(Server-Stub)
5)服务器(Server)
它们的关系如图所示。

当用户发起一个远程CALL时,过程如下:
1)服务消费方(User)调用以本地调用方式调用服务;
2)User-stub接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体,并交给RPCRuntime模块。
3)RPCRuntime找到服务地址,并将消息发送到服务端。
4)服务端的RPCRuntime收到消息后,传给Server-stub。
5)server stub根据解码结果调用本地的服务。
6)本地服务执行并将结果返回给server stub。
7)server stub将返回结果打包成消息并发送至消费方;
8)client stub接收到消息,并进行解码;
9)服务消费方得到最终结果
RPC调用细节
一、接口方式的调用
通过之前的介绍,以及上图的分析,我们知道,RPC设计的目的在于可以让调用者可以像以本地调用方式一样调用远程服务。具体实现的方式是调用接口的方式来调用。如果我们用的是java语言,则底层通过jdk动态代理方式生成接口的代理类,代理类中封装了与远程服务通信的细节。这些细节包括:
客户端的请求消息结构一般需要包括以下内容:
1)接口名称,如果不传,服务端就不知道调用哪个接口了;
2)方法名,一个接口内可能有很多方法,如果不传方法名服务端也就不知道调用哪个方法;
3)参数类型以及相应的参数值
4)requestID,标识唯一请求id
服务端返回的消息结构一般包括以下内容:
1)返回值
2)requestID
二、序列化
一旦确定了消息的数据结构后,下一步就是要考虑序列化与反序列化了。序列化就是将数据结构或对象转换成二进制串的过程,也就是编码的过程。反序列化将在序列化过程中所生成的二进制串转换成数据结构或者对象的过程。
目前国内各大互联网公司广泛使用hessian、protobuf、thrift、avro等成熟的序列化解决方案来搭建RPC框架,这些都是久经考验的解决方案。
三、通信
消息数据结构被序列化为二进制串后,下一步就要进行网络通信了。目前有两种IO通信模型:
1)BIO
2)NIO
一般RPC框架都是基于NIO来通信。
1)使用java nio方式自研,这种方式较为复杂,而且很有可能出现隐藏bug,很少有互联网公司使用这种方式。
2)基于mina,mina在早几年比较火热,不过这些年版本更新缓慢,已淡出视野。
3)基于netty,现在很多RPC框架都直接基于netty这一通信框架,比如阿里巴巴的HSF、dubbo,Twitter的finagle,以及AVRO等。
主流的RPC框架
Thrift
facebook的开源RPC框架,现在贡献给apache。支持多语言之间的RPC通信,facebook当时在开发Thrift的时候,目的就是为了实现facebook系统内之间的各语言通信。2007年贡献给apache。
Protocol Buffer
是Google开源的RPC框架,可以跨平台使用,目前支持的语言:C++,java,python。(没有thrift多)。
Apache Avro
RPC框架具有的特点:
1.基于RPC的进程通信方式
2.有自定义的一套序列化和反序列的机制
3.客户端通过代理机制调用远程方法
4.服务端通过回调机制执行方法及返回结果
课外阅读:OSI 七层
OSI七层架构图
OSI模型,即开放式通信系统互联参考模型(Open System Interconnection,OSI/RM,Open Systems Interconnection Reference Model),是国际标准化组织(ISO)提出的一个试图使各种计算机在世界范围内互连为网络的标准框架,简称OSI。
这是一种事实上被TCP/IP 4层模型淘汰的协议。在当今世界上没有大规模使用。

来自于百度百科的介绍
1.物理层
(Physical Layer)
O S I 模型的最低层或第一层,该层包括物理连网媒介,如电缆连线连接器。物理层的协议产生并检测电压以便发送和接收携带数据的信号。在你的桌面P C 上插入网络接口卡,你就建立了计算机连网的基础。换言之,你提供了一个物理层。尽管物理层不提供纠错服务,但它能够设定数据传输速率并监测数据出错率。网络物理问题,如电线断开,将影响物理层。 用户要传递信息就要利用一些物理媒体,如双绞线、同轴电缆等,但具体的物理媒体并不在OSI的7层之内,有人把物理媒体当做第0层,物理层的任务就是为它的上一层提供一个物理连接,以及它们的机械、电气、功能和过程特性。如规定使用电缆和接头的类型、传送信号的电压等。在这一层,数据还没有被组织,仅作为原始的位流或电气电压处理,单位是比特。
2.数据链路
(Datalink Layer)
O S I 模型的第二层,它控制网络层与物理层之间的通信。它的主要功能是如何在不可靠的物理线路上进行数据的可靠传递。为了保证传输,从网络层接收到的数据被分割成特定的可被物理层传输的帧。帧是用来移动数据的结构包,它不仅包括原始数据,还包括发送方和接收方的物理地址以及纠错和控制信息。其中的地址确定了帧将发送到何处,而纠错和控制信息则确保帧无差错到达。如果在传送数据时,接收点检测到所传数据中有差错,就要通知发送方重发这一帧。 数据链路层的功能独立于网络和它的节点和所采用的物理层类型,它也不关心是否正在运行 Wo r d 、E x c e l 或使用I n t e r n e t。有一些连接设备,如交换机,由于它们要对帧解码并使用帧信息将数据发送到正确的接收方,所以它们是工作在数据链路层的。 数据链路层(DataLinkLayer):在物理层提供比特流服务的基础上,建立相邻结点之间的数据链路,通过差错控制提供数据帧(Frame)在信道上无差错的传输,并进行各电路上的动作系列。 数据链路层在不可靠的物理介质上提供可靠的传输。该层的作用包括:物理地址寻址、数据的成帧、流量控制、数据的检错、重发等。 数据链路层协议的代表包括:SDLC、HDLC、PPP、STP、帧中继等。
3.网络层
(Network Layer)
O S I 模型的第三层,其主要功能是将网络地址翻译成对应的物理地址,并决定如何将数据从发送方路由到接收方。 网络层通过综合考虑发送优先权、网络拥塞程度、服务质量以及可选路由的花费来决定从一个网络中节点A 到另一个网络中节点B 的最佳路径。由于网络层处理路由,而路由器因为即连接网络各段,并智能指导数据传送,属于网络层。在网络中,“路由”是基于编址方案、使用模式以及可达性来指引数据的发送。 网络层负责在源机器和目标机器之间建立它们所使用的路由。这一层本身没有任何错误检测和修正机制,因此,网络层必须依赖于端端之间的由D L L提供的可靠传输服务。 网络层用于本地L A N网段之上的计算机系统建立通信,它之所以可以这样做,是因为它有自己的路由地址结构,这种结构与第二层机器地址是分开的、独立的。这种协议称为路由或可路由协议。路由协议包括I P、N o v e l l公司的I P X以及A p p l e Ta l k协议。 网络层是可选的,它只用于当两个计算机系统处于不同的由路由器分割开的网段这种情况,或者当通信应用要求某种网络层或传输层提供的服务、特性或者能力时。例如,当两台主机处于同一个L A N网段的直接相连这种情况,它们之间的通信只使用L A N的通信机制就可以了(即OSI 参考模型的一二层)。
4.传输层
(Transport Layer)
O S I 模型中最重要的一层。传输协议同时进行流量控制或是基于接收方可接收数据的快慢程度规定适当的发送速率。除此之外,传输层按照网络能处理的最大尺寸将较长的数据包进行强制分割。例如,以太网无法接收大于1 5 0 0 字节的数据包。发送方节点的传输层将数据分割成较小的数据片,同时对每一数据片安排一序列号,以便数据到达接收方节点的传输层时,能以正确的顺序重组。该过程即被称为排序。 工作在传输层的一种服务是 T C P / I P 协议套中的T C P (传输控制协议),另一项传输层服务是I P X / S P X 协议集的S P X (序列包交换)。
5.会话层
(Session Layer)
负责在网络中的两节点之间建立、维持和终止通信。会话层的功能包括:建立通信链接,保持会话过程通信链接的畅通,同步两个节点之间的对 话,决定通信是否被中断以及通信中断时决定从何处重新发送。 你可能常常听到有人把会话层称作网络通信的“交通警察”。当通过拨号向你的 I S P (因特网服务提供商)请求连接到因特网时,I S P 服务器上的会话层向你与你的P C 客户机上的会话层进行协商连接。若你的电话线偶然从墙上插孔脱落时,你终端机上的会话层将检测到连接中断并重新发起连接。会话层通过决定节点通信的优先级和通信时间的长短来设置通信期限。
6.表示层
(Presentation Layer)
应用程序和网络之间的翻译官,在表示层,数据将按照网络能理解的方案进行格式化;这种格式化也因所使用网络的类型不同而不同。 表示层管理数据的解密与加密,如系统口令的处理。例如:在 Internet上查询你银行账户,使用的即是一种安全连接。你的账户数据在发送前被加密,在网络的另一端,表示层将对接收到的数据解密。除此之外,表示层协议还对图片、视频、文本等文件格式信息进行解码和编码,例如MPEG和JPEG。
7.应用层
(Application Layer)
负责对软件提供接口以使程序能使用网络服务。术语“应用层”并不是指运行在网络上的某个特别应用程序 ,应用层提供的服务包括文件传输、文件管理以及电子邮件的信息处理。
Avro Schema
Schemas
Avro relies on schemas. When Avro data is read, the schema used when writing it is always present. This permits each datum to be written with no per-value overheads, making serialization both fast and small. This also facilitates use with dynamic, scripting languages, since data, together with its schema, is fully self-describing.
When Avro data is stored in a file, its schema is stored with it, so that files may be processed later by any program. If the program reading the data expects a different schema this can be easily resolved, since both schemas are present.
When Avro is used in RPC, the client and server exchange schemas in the connection handshake. (This can be optimized so that, for most calls, no schemas are actually transmitted.) Since both client and server both have the other’s full schema, correspondence between same named fields, missing fields, extra fields, etc. can all be easily resolved.
Avro schemas are defined with JSON . This facilitates implementation in languages that already have JSON libraries.
Avro是依赖于模式(schema),模式文件是用json格式来表示的。
如果是想利用avro实现序列化或rpc通信,需要遵守schema的格式要求。
基于模式的好处是使得序列化快速而又轻巧。
Avro简单格式列表(8种)
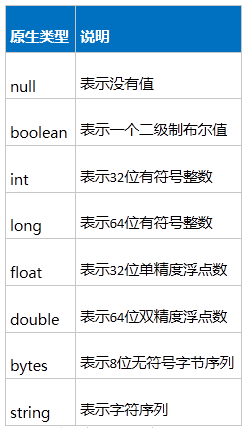
Avro复杂格式列表(6种)
只需掌握:record

Test.avsc文件 所有格式示例
说明:Test.avsc文件,利用avro的插件可生成对应的Test 类,这个类可以利用avro的API序列化和反序列化)
{"namespace": "avro.domain",
"type": "record",
"name": "Test",
"fields": [
{"name": "stringVar", "type": "string"},
{"name": "bytesVar", "type": ["bytes", "null"]},
{"name": "booleanVar", "type": "boolean"},
{"name": "intVar", "type": "int", "order":"descending"},
{"name": "longVar", "type": ["long", "null"], "order":"ascending"},
{"name": "floatVar", "type": "float"},
{"name": "doubleVar", "type": "double"},
{"name": "enumVar", "type": {"type": "enum", "name": "Suit", "symbols" : ["SPADES", "HEARTS", "DIAMONDS", "CLUBS"]}},
{"name": "strArrayVar", "type": {"type": "array", "items": "string"}},
{"name": "intArrayVar", "type": {"type": "array", "items": "int"}},
{"name": "mapVar", "type": {"type": "map", "values": "long"}},
{"name": "fixedVar", "type": {"type": "fixed", "size": 16, "name": "md5"}}
]
}
AVRO pom坐标
坐标
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.6.4</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-ipc</artifactId>
<version>1.7.5</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
</plugin>
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.7.5</version>
<executions>
<execution>
<id>schemas</id>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
<goal>protocol</goal>
<goal>idl-protocol</goal>
</goals>
<configuration>
<sourceDirectory>${project.basedir}/src/main/avro/</sourceDirectory>
<outputDirectory>${project.basedir}/src/main/java/</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
模式定义avsc文件
Avro通过avsc文件,会生成对应的java类,这个java类专门用来被avro实现序列化和反序列化。
实现步骤:
1.在工程下创建src\main\avro 的maven目录
2.在此目录下建立Xxx.avsc的文件
3.根据avro的schema格式,定义文件avsc文件
4.引入avro及其依赖插件的pom坐标
5.在项目上右键=》run as=>generate source 生成avsc文件对应的java对象
maven的相关知识:
maven对构建(build)的过程进行了抽象和定义,这个过程被称为构建的生命周期(lifecycle)。生命周期(lifecycle)由多个阶段(phase)组成,每个阶段(phase)会挂接一到多个goal。goal是maven里定义任务的最小单元,goal分为两类,一类是绑定phase的,就是执行到某个phase,那么这个goal就会触发,另外一类不绑定,就是单独任务,这就相当于ant里的target。
1。以phase来构建
例如:
mvn clean
mvn compile
mvn test
mvn package
表明maven会执行到某个生命周期(lifecycle)的某个阶段(phase)
这个phase以及它前面所有phase绑定的目标(goal)都会执行, 每个phase都会邦定maven默认的goal或者没有goal, 或者自定义的goal。
也可以通过传入参数跳过(skip)某些phase,例如:
mvn install -Dmaven.test.skip=true
user.avsc代码:
{"namespace": "example.avro", //生成User对象后,所在的包路径
"type": "record",
"name": "User", //类名,User
"fields": [
{"name": "name", "type": "string"}, //私有属性名 name ,类型 String
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
}
AVRO实现对象的序列化和反序列化
实现步骤:
1.创建maven工程
2.引入avro依赖的jar包
3.根据pom.xml文件的配置,在工程下建立src\main\avro 源目录
4.定义User类模式文件,user.avsc,(avro的所有schema文件都放在src\main\avro目录下)便于管理
5.利用maven的阶段指令(phase)generate-sources,avro的插件会扫描src\main\avro目录下的所有schema文件,此时user.avsc生成对应的User对象
6.利用AVRO的API实现对象的序列化和反序列化
具体实现:
1.创建maven工程(普通java工程),如图:
2.avro依赖jar包的pom坐标:
坐标:
<dependencies>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-ipc</artifactId>
<version>1.7.5</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.6.4</version>
<scope>compile</scope>
</dependency>
</dependencies>
3.定义avro编译插件
pom.xml代码:
<build>
<plugins>
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.7.5</version>
<executions>
<execution>
<id>schemas</id>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
<goal>protocol</goal>
<goal>idl-protocol</goal>
</goals>
<configuration>
//这行配置的意思是让maven去src/main/resources/目录下去找avro相关的文件
<sourceDirectory>${project.basedir}/src/main/resources/</sourceDirectory>
//这样配置的意思是maven生成的对应的java文件放在/src/main/java/
<outputDirectory>${project.basedir}/src/main/java/</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.6</source>
<target>1.6</target>
</configuration>
</plugin>
</plugins>
</build>
提示:标红的配置可以不加,如果不加,maven也会自动去扫描avro的文件,生成的java文件会放在target目录下
4.定义User类消息文件,user.avsc(就是一个file类型的文件)
user.avsc代码:
{"namespace": "example.avro", //生成User对象后,所在的包路径
"type": "record",
"name": "User", //类名,User
"fields": [
{"name": "name", "type": "string"}, //私有属性名 name ,类型 String
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
}
5.利用maven,根据user.avsc生成对应的User对象,操作如下:
项目右键=》run as=>maven generate sources
补充:如果不用maven来生成,需要手动来处理,操作如下:
①下载这4个jar包,并放在同一目录下
②把user.avsc文件放在此目录下
③在此目录下进入cmd命令窗口
④执行:java -jar avro-tools-1.7.4.jar compile schema Person.avsc ./
6.利用AVRO的API实现对象的序列化和反序列化
avro创建对象的三种形式:
@Test
public void testCreateUser(){
User u1=new User();
u1.setName("tom");
u1.setAge(23);
User u2=new User("jary", 25);
User u3=new User();
//利用newBuilder(Obeject).setXxx().build()的方式来创建User,更加灵活
//即可以基于某一个对象来创建一个新的对象,如果不做任何修改,就相当于复制这个对象。此外,也可以针对某一个值进行修改
User u4=User.newBuilder(u2).setAge(26).build();
System.out.println(u4);
}
序列化代码示例一(单个对象最简形式):
/*
* 这个方法是测试利用avro将User对象序列化为本地文件
* 需要掌握:
* 1.DatumWrite,DataFileWriter及DataFileWrite.create()的用法
*/
@Test
public void testAvroSerialize01() throws Exception{
User user=new User();
user.setName("jary");
user.setFavoriteNumber(1);
user.setFavoriteColor("green");
DatumWriter<User> dw=new SpecificDatumWriter<User>(User.class);
DataFileWriter<User> dfw=new DataFileWriter<User>(dw);
File file=new File("user.data");
//user.getSchem()相当于得到的是user.avsc文件里定义的数据结构
dfw.create(user.getSchema(), file);
//追加要序列化的对象信息
dfw.append(user);
dfw.close();
}
序列化代码示例二(多个对象):
/*
* 这个方法是测试利用多种方法来创建User对象,
* 需要掌握:
* 1.通过构造方法创建对象
* 2.通过newBuilder()方法创建对象
* 3.将多个对象序列化到本地文件中
*/
@Test
public void testAvroSerialize02() throws Exception{
User user1=new User();
user1.setName("jary");
user1.setFavoriteNumber(2);
user1.setFavoriteColor("green");
//也可以通过提供的构造方法来创建对象
User user2=new User("tom",3,"red");
//可以通过newBuilder()的方法来创建对象
User user3=User.newBuilder().
setName("rose").
setFavoriteNumber(3).
setFavoriteColor("black").build();
DatumWriter<User> dw=new SpecificDatumWriter<>(User.class);
DataFileWriter<User> dfw=new DataFileWriter<User>(dw);
File file=new File("user.data");
dfw.create(user1.getSchema(), file);
dfw.append(user1);
dfw.append(user2);
dfw.append(user3);
dfw.close();
}
反序列化代码( GenericDatumReader):
/*
* 此方法用于测试avro的反序列化
* 需要掌握:
* 1.DatumReader
* 2.DataFileReader
* 3.GenericRecord数据类型
*/
@Test
public void testDeSerialize() throws Exception{
//要读取的序列化文件路径
File file=new File("user.data");
DatumReader<GenericRecord> dr = new GenericDatumReader<GenericRecord>(new User().getSchema());
DataFileReader<GenericRecord> dfr= new DataFileReader<GenericRecord>(file,dr);
while (dfr.hasNext()) {
GenericRecord user=dfr.next();
System.out.println(user);
}
}
反序列化代码(pecificDatumReader)此方法重点掌握:
/*
* 此方法是用来测试反序列的
* 重点掌握:
* 1.SpecificDatumReader的用法
* 因为通过这个类,可以直接拿到User对象,而GenericDatumReader只能拿到GenericRecord对象
*/
@Test
public void testDeSerialize02() throws Exception{
File file=new File("user.data");
DatumReader<User> dr=new SpecificDatumReader<>(User.class);
DataFileReader<User> dfr=new DataFileReader<>(file, dr);
while(dfr.hasNext()){
User user=dfr.next();
System.out.println(user.getName()+":"+user.getFavoriteNumber()+":"+user.getFavoriteColor());
}
}
RPC框架
概念
在理解什么是RPC框架之前,首先要了解什么是RPC 。
RPC的翻译是:Remote Procedure Call Protocol——远程过程调用协议。
应用场景:基于RPC,我们可以让一台计算机通过网络通信从远程计算机(另一台计算机)上请求服务,并得到远程计算机返回的结果。
所以,使用RPC的目的就是无法在一个进程内,甚至一个计算机内通过本地调用的方式完成的需求,比如不同的系统间的通讯,甚至不同的组织间的通讯。由于计算能力需要横向扩展,需要在多台机器组成的集群上部署应用,
最常见应用于分布式集群环境中,集群里各节点(计算机)之间的网络通信。

两台服务器A,B,一个应用部署在A服务器上,A想要调用B服务器上应用提供的函数/方法,由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语义和传达调用的数据。
比如说,一个方法可能是这样定义的:
int add(int a,in b)
那么:
首先,要解决通讯的问题,主要是通过在客户端和服务器之间建立TCP连接,远程过程调用的所有交换的数据都在这个连接里传输。
第二,要解决寻址的问题,也就是说,A服务器上如何连接到B服务器(如主机或IP地址)以及特定的端口,方法的名称名称是什么,这样才能完成调用。
第三,当A服务器上的应用发起远程过程调用时,方法的参数需要通过底层的网络协议如TCP传递到B服务器,由于网络协议是基于二进制的,所以需要将数据进行序列化后发送给B服务器。
第四,B服务器收到请求后,需要对参数进行反序列化(序列化的逆操作),恢复数据。然后找到对应的方法进行本地调用,然后得到返回值。
第五,返回值还要发送回服务器A上的应用,也要经过序列化的方式发送,服务器A接到后,再反序列化,恢复为内存中的表达方式,交给A服务器上的应用。
主流的RPC框架
Thrift
facebook的开源RPC框架,现在贡献给apache。支持多语言之间的RPC通信,facebook当时在开发Thrift的时候,目的就是为了实现facebook系统内之间的各语言通信。2007年贡献给apache。
Protocol Buffer
是Google开源的RPC框架,可以跨平台使用,目前支持的语言:C++,java,python。(没有thrift多)。
Apache Avro
RPC框架具有的特点:
1.基于rpc协议
2.有自定义的一套序列化和反序列的机制
3.客户端通过代理机制调用远程方法
4.服务端通过回调机制执行方法及返回结果
模式定义avdl文件
avdl文件用于avro生成协议方法的。
实现步骤:
1.在src\main\avro目录下新建一个后缀为avdl的文件,比如AddService.avdl文件
2.根据avro格式要求以及业务要求编辑这个文件
3.利用maven -run as -generate sources 生成协议方法类
AddService.avdl代码:
@namespace(“rpc.service”)
protocol AddService{
int add(int i,int y);
}
协议方法里想传递某个avsc对象的代码
@namespace(“rpc.service”)
protocol AddService{
import schema “User.avsc”;
int add(int i,int y);
void parseUser(avro.domain.User user);
}
协议方法里想传递一个map,并且map里包含一个对象的代码:
@namespace(“rpc.service”)
protocol AddService{
import schema “User.avsc”;
int add(int i,int y);
void parseUser(avro.domain.User user);
void parseUserMap(map<avro.domain.User> userMap);
}
AVRO—实现RPC加法运算

@namespace(“contract.service”)
protocol AddService{
int add(int i,int y);
}
avro-add-contract工程pom.xml文件:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<compiler-plugin.version>2.3.2</compiler-plugin.version>
<avro.version>1.7.5</avro.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.6.4</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-ipc</artifactId>
<version>1.7.5</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>${compiler-plugin.version}</version>
</plugin>
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.7.5</version>
<executions>
<execution>
<id>schemas</id>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
<goal>protocol</goal>
<goal>idl-protocol</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>

Maven 由于goals标签报错解决办法
