版权声明:本文为博主原创文章,未经博主允许不得转载。作为分享主义者(sharism),本人所有互联网发布的图文均采用知识共享署名 4.0 国际许可协议(https://creativecommons.org/licenses/by/4.0/)进行许可。转载请保留作者信息并注明作者Jie Qiao专栏:http://blog.csdn.net/a358463121。商业使用请联系作者。 https://blog.csdn.net/a358463121/article/details/79543198
变分自编码器(VAE)
从EM到变分推断
我们假设有一个隐变量z,我们的样本
x(i)是从
pθ(x∣z)中产生,因为有隐变量的存在,通常
pθ(x)=∫pθ(z)pθ(x∣z)dz的边缘分布是没法算的。
所以传统来说,我们会构造出一个下界:
logp(x)=ELOB
Ez∼q(z)(logp(x,z))−H(q)+KL(q(z)∣∣p(z∣x))
因此当我们最大化下界(ELOB)时,就相当于在最小化
KL(q(z)∣∣p(z∣x))
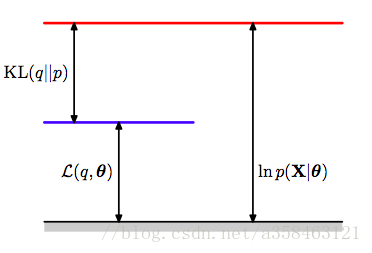
而EM算法,就是通过精心选择这个下界中的q,从而使得下界最大化,也就是计算
q(z)=p(z∣x)来近似该模型的似然度。进一步可以参考我之前写的文章《带你理解EM算法》
然而如果我们令
q(z)=p(z∣x)=pθ(x)pθ(x∣z)pθ(z)也是不可计算的呢,比如你的z有很多很多维,那么你在算那个期望的时候就会出现一堆积分,这是非常难算的。
此时我们可以使用变分推断的方法,那就是,我们不直接令
q(z)=p(z∣x)了,而是选一个相对简单的分布
q(z)去近似
p(z∣x),(注意,这个q不一定是q(z)还可以是q(z|x),这种情况称为amortized variational),这个“近似”的数学形式写作
minqKL(q(z)∥p(z∣x))或
minqKL(q(z∣x)∥p(z∣x))。那么简单的q怎么来?最常用的就是对q作平均场(mean-field)假设,即,我们可以认为:
q(z)=i∏qi(zi)
这个假设的意思是,虽然你的z有很多维,但是他们都是相互独立的,也就是说,你算很多很多积分的时候,每个
zi可以分别积分,所以一个联合积分的问题就简化成了仅需一个积分的问题,于是我们在优化ELOB的时候,只需分别优化
qi就可以了。将平均场假设代进ELOB中,化简可以得到
ELOB=∫zjqj(zj)⎣⎢⎡zi̸=j∫…∫q(z)logp(x,z)dzi⎦⎥⎤dzj−i∑∫ziqi(zi)logqi(zi)dzi=∫zjqj(zj)Ei̸=j[logp(x,z)]dzj−∫zjqj(zj)logqj(zj)dzj−Const for j
i̸=j∑∫ziqi(zi)logqi(zi)dzi=∫zjqj(zj)logqj(zj)Ei̸=j[logp(x,z)]dzj−Const for j
i̸=j∑M∫ziqi(zi)logqi(zi)dzi=−KL(Ei̸=j[logp(x,z)∣∣qj(zj)])+const
因为每个
zj都是相互独立,于是,只需分别最大化每个
zj的ELOB就可以实现ELOB最大化,而其他的项都视作了常数,此时,ELOB就简单地变成了一个负的KL距离,所以,想要最大化这个ELOB,我们只需要令
qj(zj)=Ei̸=j[logp(x,z)]
就可以了。这实际上是一个迭代的问题,因为在constant中,包含了其他的项的q,所以,我们只需不断地更新各个元素q的分布直到收敛就可以了。
从变分推断到VAE
但是,如果即使用了平均场假设也没法算,而使用MCMC又太慢怎么办?为了解决这个问题,我们回到最初的那个下界的表达式中
logp(x∣θ)=ELOB
Ez∼q(z)(logp(x,z))−H(q)+KL(q(z)∣∣p(z∣x))
实际上ELOB有几种不同的,但是等价的表达方式:
KL form :
L(θ;x)=Ez∼q(z)(logpθ(x∣z))−KL(q(z)∣∣pθ(z))
Entropy form:
L(θ;x)=Ez∼q(z)(logpθ(x,z))−H(q)
Fully Monte Carlo(FMC) form:
L(θ;x)=Ez∼q(z)[logpθ(x,z)−logq(z)]
其中q是一个任意的分布,那么现在,我们令
q(z)≜qϕ(z∣x),用KL形式的下界可以得到:
L(θ,ϕ;x)=Ez∼qϕ(z∣x)(logpθ(x∣z))−KL(qϕ(z∣x)∣∣pθ(z))
现在引入了一个带参数的
qϕ来表示这个上界,如果要最大化这个上界,我们只要用梯度上升不断更新参数$\phi
就可以了。一般情况下,KL距离的那一项是有解析解的,所以梯度很好求。然而对第一项求梯度则没那么简单,一个常用的方法是\nabla {\phi } E{z\sim q_{\phi }( z)}( f( z)) =E_{z\sim q_{\phi }( z)}[ f( z) \nabla {\phi }\log q{\phi }( z)] \simeq \frac{1}{L}\sum ^{L}_{l=1} f\left( z^{l}\right) \nabla {\phi }\log q{\phi }\left( z^{l}\right)$,但是这么做的方差太高。
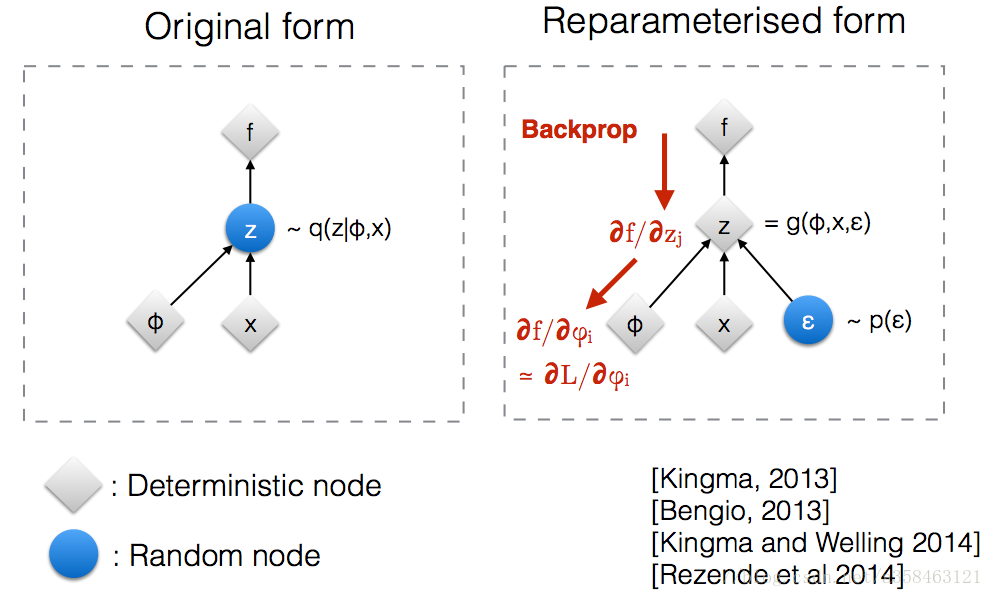
如上图,我们可以用reparameterize trick来解决这个问题,这时z对于x来说就是一个固定的值,只要我们从
ϵ中抽样后,固定住就可以了,设
z=gϕ(ϵ,x),ϵ∼p(ϵ)
其中$\epsilon $是一个已知的简单分布,比如说标准正态分布,次数z的产生就变成了从某个固定的标准分布中采样,于是下界中的期望那一项可以改写成:
Ez∼qϕ(z∣x)(logpθ(x∣z))=Eϵ∼p(ϵ)(logpθ(x∣gϕ(ϵ,x)))≃L1l=1∑Llogpθ(x∣gϕ(ϵ,x))
于是对于一个样本
x(i)的下界可以写作:
L(θ,ϕ;x(i))=L1l=1∑Llogpθ(x(i)∣z(i,l))−KL(qϕ(z(i)∣x(i))∣∣pθ(z(i)))
其中
z(i,l)=gϕ(ϵ(i,l),x(i)),ϵ(l)∼p(ϵ)
在这里,如果我们用一个MLP来表示
pθ和
qϕ和就可以对用这个目标函数求梯度来最大化了,注意产生z的分布
qϕ其实是由一个标准正态分布的$\epsilon
和一个用MLP表示的映射函数g_{\phi }
构成的,所以训练过程实际上是更新p_{\theta }
和g_{\phi }
这两个MLP的参数,我们称p_\theta
为encodernetwork,q_{\phi }
为decodernetwork。而z的产生则是从p( \epsilon )
抽一个样本,然后经过一个确定性g_{\phi }$来产生。
更直观一点,如果我们假设先验分布
p(z),
p(ϵ)服从标准正态分布,
z=qϕ(z∣x)=gϕ(ϵ,x)=μϕ(x)+Σϕ1/2(x)ϵ
也就是说,
qϕ(z∣x)∼N(μϕ(x),Σϕ1/2(x))也是正态分布,不过其参数由x决定。于是对于两个正态分布的KL距离,对于有J个维度的z,我们完全可以算出其解析解:
−KL(qϕ(z∣x)∣∣pθ(z))=−KL(N(μϕ,σϕ)∣∣N(0,I))=21j=1∑J((1+logσj2)−μj2−σj2)
接下来我们看看这个网络的架构

encoder network将一只喵星人映射成一个均值和一个方差,然后产生一个z样本,通过decoder network再变成一只喵~
然而VAE对比GAN确实存在一些问题。
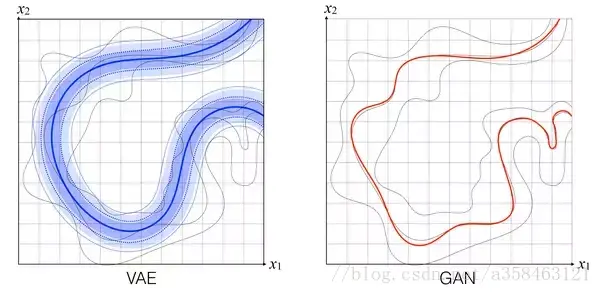
可以看到VAE的“拟合”能力没有GAN的强,VAE会趋于平滑而GAN则不会。而且VAE产生的图像会比较模糊,这似乎所有优化对数似然的目标函数
KL(pdata∣∣pmodel)都有这问题(《Deep learning》),这一点,或许与KL距离的性质有关系,可以看我的另外一篇文章,《正向跟反向KL距离到底有什么区别?》
参考资料
Auto-encoding variational bayes
Tutorial on variational autoencoders
How does the reparameterization trick for VAEs work and why is it important?
Variational Autoencoders Explained
Deep learning
徐亦达机器学习课程
带你理解EM算法
作为分享主义者(sharism),本人所有互联网发布的图文均遵从CC版权,转载请保留作者信息并注明作者Jie Qiao专栏:http://blog.csdn.net/a358463121,如果涉及源代码请注明GitHub地址:https://github.com/358463121/。商业使用请联系作者。