代码实现: 基于tensorflow2.2实现,代码见github。
参考文献
1. Auto-Encoding Variational Bayes
2. 变分自编码器VAE:原来是这么一回事 | 附开源代码
基于潜变量的生成模型
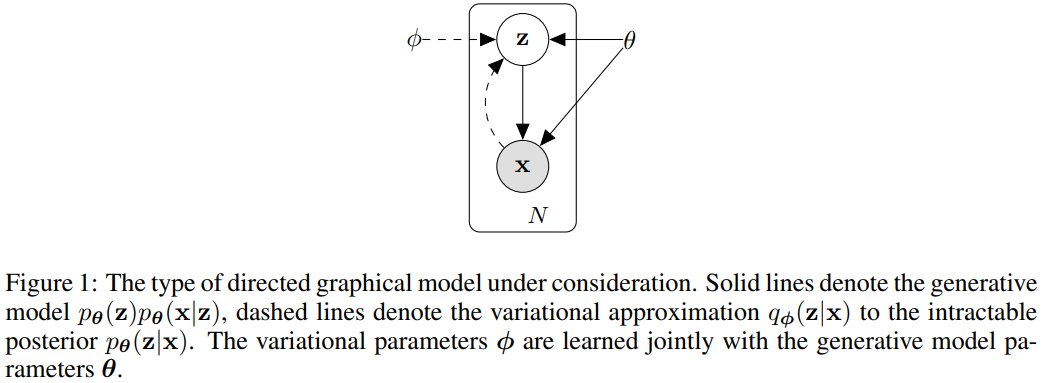
模型联合概率分布可表示为
pθ(x,z)=pθ(x∣z)pθ(z),模型的生成过程为
z∼pθ(z)⟹x∼pθ(x∣z)
考虑一个独立同分布数据集
X={x(i)}i=1N,我们假设数据的生成过程为:
- 基于先验分布
pθ(z)生成随机变量
z;
- 基于条件概率分
pθ(x∣z)生成样本
x;
然而,我们很难获取因变量
z的分布,如先验概率分布
pθ(z∣x)=pθ(x∣z)pθ(z)/pθ(x)难以计算。
使用后验概率分布
qϕ(z∣x)作为真实后验概率分布
pθ(z∣x)的近似,将
qϕ(z∣x)可作为编码器,即给定样本
x下,生成包含所有可能的编码
z,并可通过编码
z重新生成样本
x。同样地,将
pθ(x∣z)作为解码器,即给定编码
z,生成与
x对应的分布。
再看一下,传统高斯混合模型的生成思想:
p(x)=z∑p(z)p(x∣z)
式中
p(z)∼N(0,I),
p(x∣z)∼N(μ(z),σ(z))。
我们从标准正太分布中采样一个
z,再根据
z计算对应各高斯混合基模型的均值和方差,就可以利用高斯混合模型生成
x。但是这种模型显然没有利用到监督样本数据,即如何将采样
z对应到
x?模型的损失函数是什么?
VAE的思想是,每个样本都有自己特定的正太分布
q(z∣x),我们有理由学习一个解码器/生成器,把从特定正太分布采样的
z还原为
x。 我们可从特定分布
q(z∣x)中随机采样,生成各式各样与
x类似的样本,为了使模型具备通用生成能力(不根据真实样本),我们希望所有的
q(z∣x)都近似于标准正太分布,这样我们就可以从标准正太分布中采样,生成随机样本。
变分边界与目标函数
独立同分布数据集对数似然为
logpθ(x(1),⋯,x(N))=x∑logpθ(x)
对于单个样本
logpθ(x)=∫zqϕ(z∣x)logpθ(x)dz=∫zqϕ(z∣x)log(qϕ(z∣x)pθ(z,x)pθ(z∣x)qϕ(z∣x))dz=∫zqϕ(z∣x)log(qϕ(z∣x)pθ(x∣z)pθ(z))dz+∫zqϕ(z∣x)log(pθ(z∣x)qϕ(z∣x))dz=Lb+DKL(qϕ(z∣x)∣∣∣∣pθ(z∣x))=−DKL(qϕ(z∣x)∣∣∣∣pθ(z))+Eqϕ(z∣x)[logpθ(x∣z)]+DKL(qϕ(z∣x)∣∣∣∣pθ(z∣x))
因为KL散度为不小于0的距离度量,因此
Lb为目标函数下界。因为目标函数值与
qϕ(z∣x)无关,调整
qϕ(z∣x)最大化
Lb,目标函数值不改变,但目标函数第二项KL散度趋近于0,若继续调整
pθ(x∣z)以最大化
Lb,则目标函数值很有可能增加。因此,最大化目标函数的下界
Lb即可,第三项KL散度可忽略。

VAE模型结构

训练过程中,编码器为每个样本
x生成对应正太分布的均值和方差,表示样本来自于
N(μ(z),σ(z)),解码器将从
N中的采样,重构回对应的样本
x。
同一样本在不同mini-batch中对应不同的分布,模型为了更好重构,倾向于将编码器输出方差至为0,这样就丧失了随机性,即模型丧失样本生成能力,退化为普通的AutoEncoder。因此,VAE约束所有编码向量服从标准正太分布,从而防止噪声为零。
由于
−DKL(N(μ,σ2∣∣∣∣N(0,1)))=21(logσ2−μ2−σ2+1)
如果,我们强制令
pθ(z)服从标准正太分布,最大化目标函数等价于最大化
21(−logσ2+μ2+σ2−1)+Eqϕ(z∣x)[logpθ(x∣z)]
其中,第一项为 正则化损失,它有助于学习具有良好结构的潜在空间;第二项为 重构损失,它迫使解码后的样本匹配初始输入,如mnist数据集规范化为[0, 1]区间,解码器使用sigmoid输出,则此项为交叉熵。
此外,采样操作不可导,模型实现使用 重参数技巧:
ϵ∼N(0,1)⟹μ+ϵ×σ∼N(μ,σ2)
根据编码器生成样本的均值和方差,但是我们不能直接生成对应的正太分布,再从中采样作为编码器输出,因为采样过程不可导。换种思路,从标准正太分布中采样数据(作为样本数据不参与求导),根据编码器输出将其变换到对应的正太分布,再作为编码器输出。
神经网络实现VAE
