Scrapy初识
1.0 为什么要学习scrapy
首先,requests+selenium就可以解决90%的爬虫需求,但是scrapy的出现不是能更好的99%解决爬虫需求.
而是为了让爬虫更快,更强
2.0 什么是scrapy
Scrapy 是一个为了抓取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量的代码,就能够快速的抓取
Scrapy 使用了Twisted['twistid] 异步网络框架,可以加快我们的下载速度
3.0 scrapy 的流程:
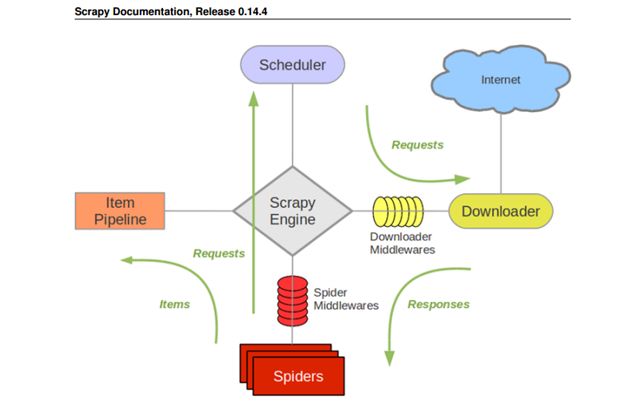
- Spiders(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)
处理引擎发来的response,提取数据,提取url,并交给引擎。【需要手写】
- Engine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
总指挥:负责数据与信号在不同的模块的传递工作。【不要手写】
- Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
一个队列,存放引擎发过来的requests请求。【不要手写】
- Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理
下载把引擎发过来的requests请求,并返回给引擎。【不要手写】
- ItemPipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
处理引擎传来的数据,比如存储 【需要手写】
- Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
可以自定义的下载扩展,比如设置代理。【一般不要手写】
- Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
可以自定义requests的请求和进行的requests过滤。【一般不要手写】
4.0 如何进行简单的应用
4.0.1 创建一个 scrapy项目
scrapy startproject mySpider
4.0.2 生成一个爬虫
scrapy genspider itcast "itcast.cn"
4.0.3 提取数据
完善spider,使用xpath or css提取
4.0.4 保存数据
pipeline 中保存
4.0.5 启动
scrapy crawl itcast
5.0 简单的实例
spiders
import scrapy class ItcastSpider(scrapy.Spider): name = 'itcast' #爬虫名 allowed_domains = ['itcast.cn'] #爬虫的范围 start_urls = ['http://www.itcast.cn/channel/teacher.shtml'] #爬虫的起始页,URL对应的响应response有想要的数据 def parse(self, response): #parse这个方法是strat_urls地址对应的响应(response) #parse这个函数名不能变,特定的 # ret = response.xpath("//div[@class='tea_con']//h3/text()").extract() # selector 对象有extract()方法,extract_first()提取第一个 # print(ret) #分组一下 li_list = response.xpath("//div[@class='tea_con']//li") for li in li_list: item = {} item["name"] = li.xpath(".//h3/text()").extract_first().strip() #strip 去掉空格 item["title"] = li.xpath(".//h4/text()").extract_first().strip() yield item #这个地方就是把item 发到pipelines 去处理,yield 是一个生成器,减少内存的占用 #同时seting 里面要把pipelines 开启才能处理 #yield 只能是Requests,BaseItem,dict or None的类型,list类型不行
pipelines
class MyspiderPipeline(object): def process_item(self, item, spider): #process_item 这个函数名不能变,这个是特定的 #to do somthing item["hello"] = ["world"] # print(item) return item #前一个pipelin必须要有return item,不然就是空值了 class MyspiderPipeline2(object): def process_item(self, item, spider): # process_item 这个函数名不能变,这个是特定的 # to do somthing print(item) return item
settings
BOT_NAME = 'myspider' SPIDER_MODULES = ['myspider.spiders'] NEWSPIDER_MODULE = 'myspider.spiders' LOG_LEVEL = "WARNING" #五个等级,设置一下 # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'myspider (+http://www.yourdomain.com)' # Obey robots.txt rules ROBOTSTXT_OBEY = True # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs #DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: #DEFAULT_REQUEST_HEADERS = { # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', # 'Accept-Language': 'en', #} # Enable or disable spider middlewares # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # 'myspider.middlewares.MyspiderSpiderMiddleware': 543, #} # Enable or disable downloader middlewares # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html # DOWNLOADER_MIDDLEWARES = { # 'myspider.middlewares.MyspiderDownloaderMiddleware': 543, # Enable or disable extensions # See https://doc.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, #} # Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'myspider.pipelines.MyspiderPipeline': 300, 'myspider.pipelines.MyspiderPipeline2': 302, #这个地方是路径加middleweares名 #300 表示引擎的远近,数据越小,越新处理 } # Enable and configure the AutoThrottle extension (disabled by default) # See https://doc.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = 'httpcache' #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'