YOLO9000: Better, Faster, Stronger
(一)论文地址:
https://arxiv.org/abs/1612.08242
(二)核心思想:
作者在 YOLO 的基础上,使用了批量标准化(Batch Normalization)、高分辨率分类器(High Resolution Classifier)和预选框(Anchor Boxes)等方法,提出了一个更为高效的 YOLO v2;
并在此基础上,使用联合训练(Joint Training)算法,能够在有大量分类的图像识别数据集训练目标检测任务,由此训练出的 YOLO 9000 能够识别 9000 个物体;
(三)YOLO 的不足:
- 采用了直接回归坐标的方式,对于精准预测不够准确;
- 具有较低的召回率(recall);
(四)Batch Normalization:
Batch Normalization(批量标准化)是 Google 团队在 Inception V2 中提出的方法,核心是使用一个线性变换,将批量数据规范到均值为 0、方差为 1 的正态分布上,从而解决了随着网络层数不断加深,造成的梯度消失的问题,并且还具有正则化的效果;

作者因此在 YOLO 中大量使用了 Batch Normalization,使得原来的 mAP 上升了 2%,并且无需再使用 Dropout;
(五)High Resolution Classifier:
以前的目标检测网络通常都是,将 Backbone 在 ImageNet 上通过分辨率小于 的分类图片进行预训练,这就意味着 Backbone 在参与目标检测任务的训练时,需要向检测任务和高分辨率图片做转换;
作者提出使用相同分辨率的图像( )预训练 Backbone,并只在 ImageNet 上训练 10 个 Epoch,由此使得 mAP 上升了 4%;
(六)Convolutional With Anchor Boxes:
为了解决预测框不准确的问题,作者不再使用 YOLO 采用全连接层直接预测预测框坐标的方法,而是采用了跟 Faster-RCNN 相似的预选框的方法;
作者移除了 YOLO 中的全连接层和一个 max pooling 层,来最终得到一个较大的卷积层;
并且为了使图像最后的预测具有单中心网格,作者使用了 大小作为输入,下采样参数为 (即 ),最后得到了一个 大小的特征层;
在使用 Anchor Boxes 之后,虽然 mAP 下降了 0.3%,但是召回率从 81% 上升到了 88%,因此 YOLO v2 还有很大的改进空间;
(七)Dimension Clusters
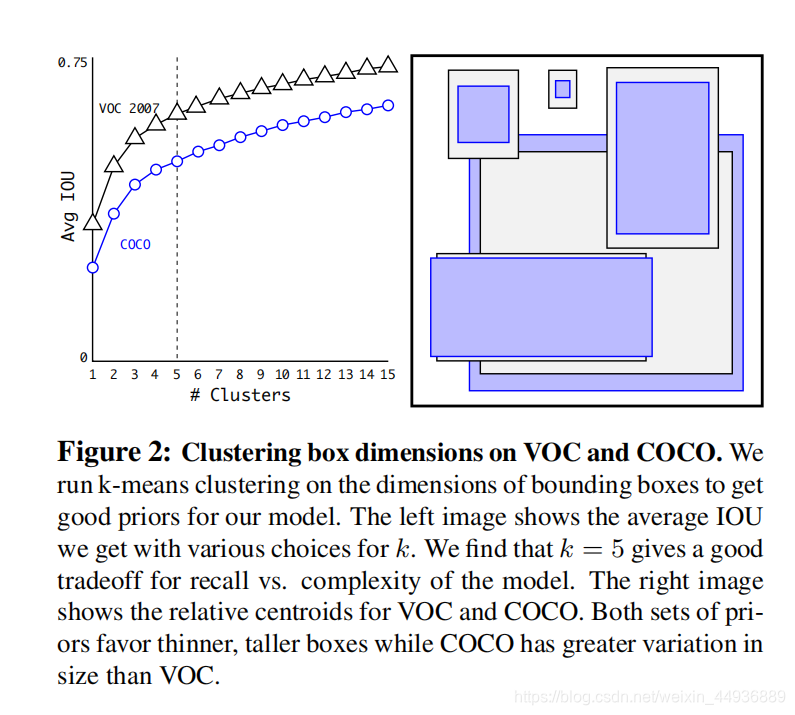
由于 Faster-RCNN 和 SSD 的先验框大小都是手动设定的,可能并不能很好地表征目标,因此作者在这里采用了 K-means 聚类算法选取合适的先验框数;
距离指标为:
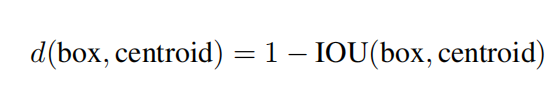
综合考虑模型复杂度和召回率,最终选定
;
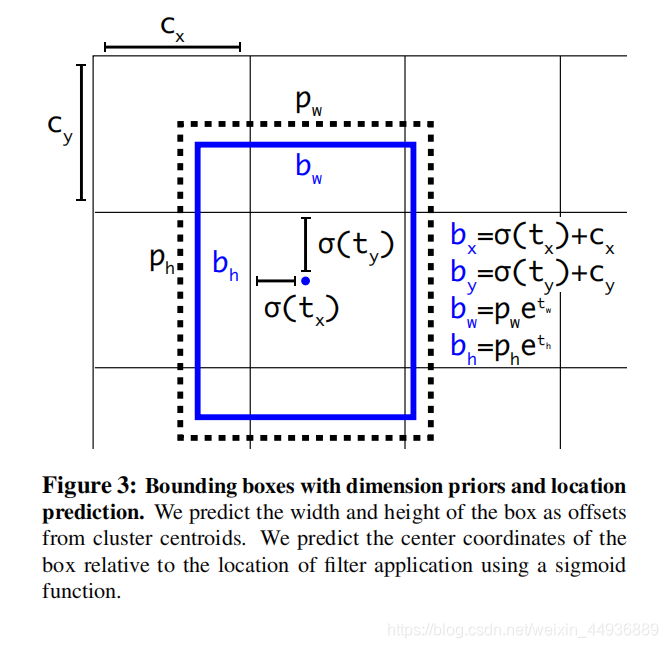
对于最后的特征层(大小为
),每个网格预测 5 个坐标信息
,则有: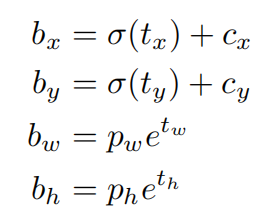
其中
就是最后的预测框坐标,
是 Anchor Box 的坐标;
并且使用 作为置信度;
(八)Fine-Grained Features:
作者为了融合 low-level 的特征设计了 passthrough 层,即取出了最后一个池化层的特整层(大小为 ),将每个 局部空间区域转换成 channel 特征,就得到了一个 的用于预测的特征层;
(九)Multi-Scale Training:
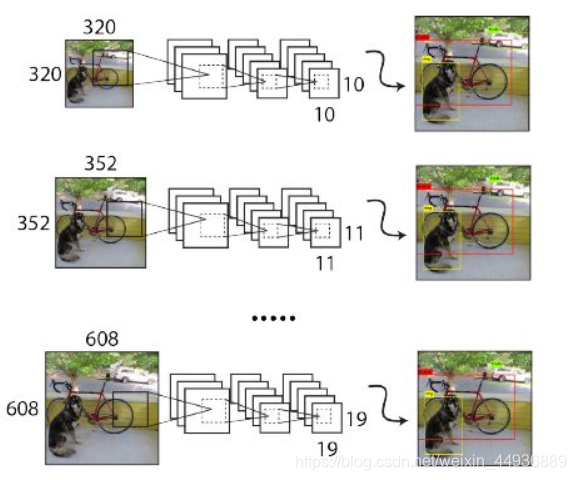
由于 YOLO v2 只使用了卷积层和池化层,因此可以接收不同大小的图像输入参与训练,从而使得 YOLO v2 对不同大小的图像都具有鲁棒性;
作者在训练时采用了 32 倍数的输入大小为,分别为: ,每 10 个 epoch 重新随机选取一个输入大小;
(十)Darknet-19:
作者还为 YOLO v2 设计了一个 Backbone,大致与 VGG 相同,但大量使用了 1×1 卷积降维,并在最后使用了一个 Global Pooling:
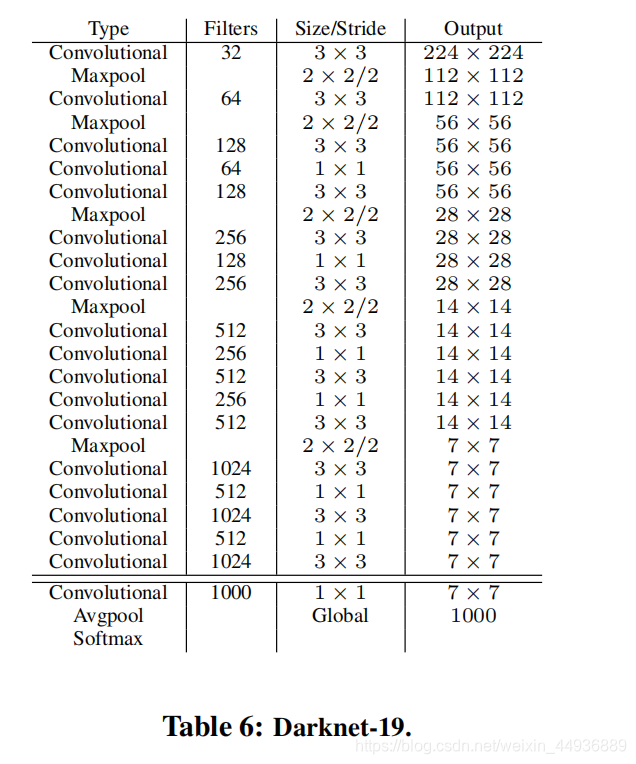
(十一)Joint Training:
这里既使用了目标检测的数据集,也使用了图像识别的数据集,其中用于图像识别的数据,在反向传播时只是用了分类 Loss,并使用了层级分类标签:
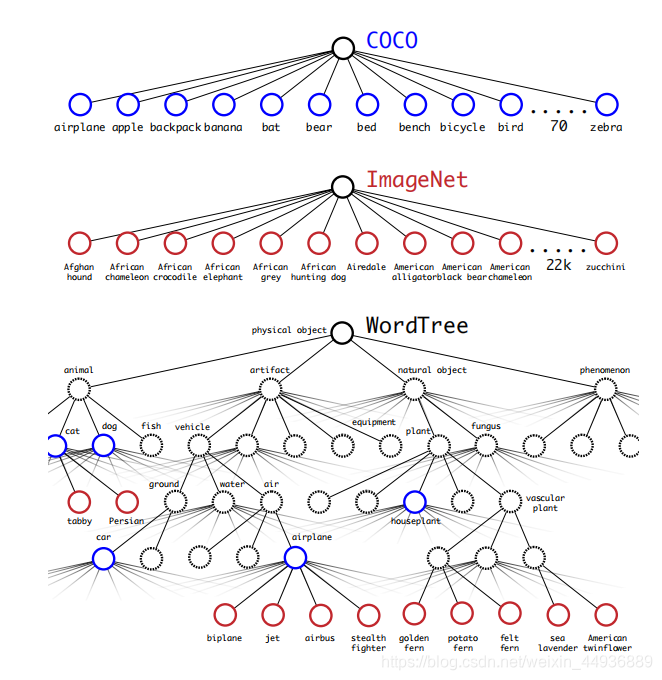
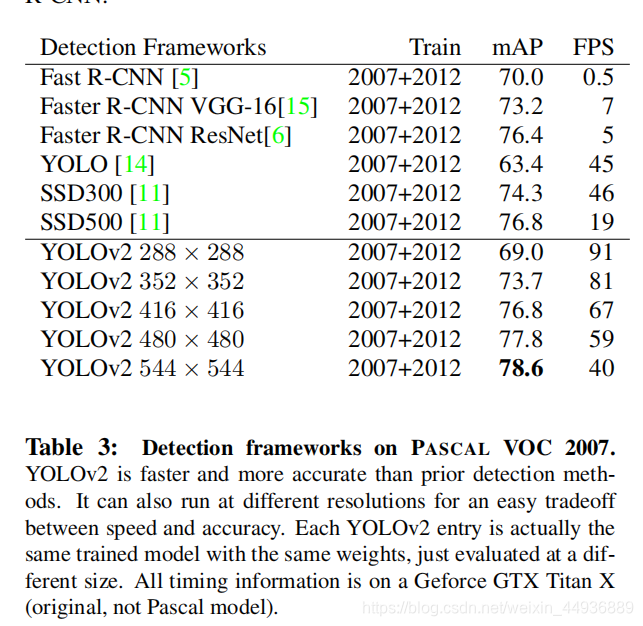
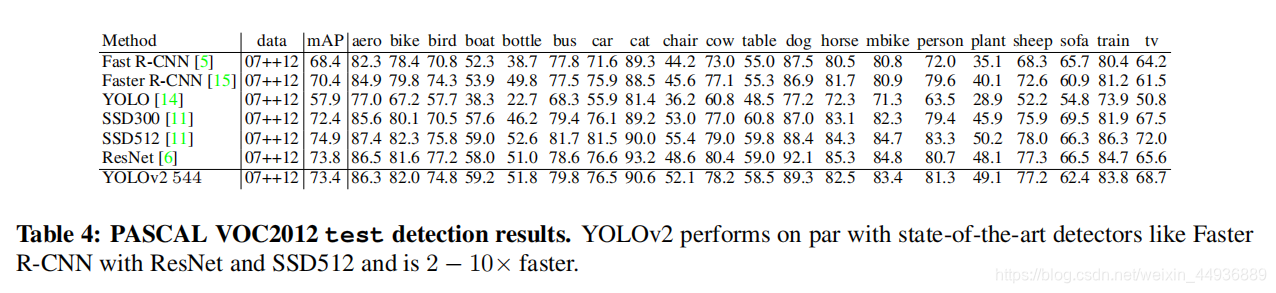
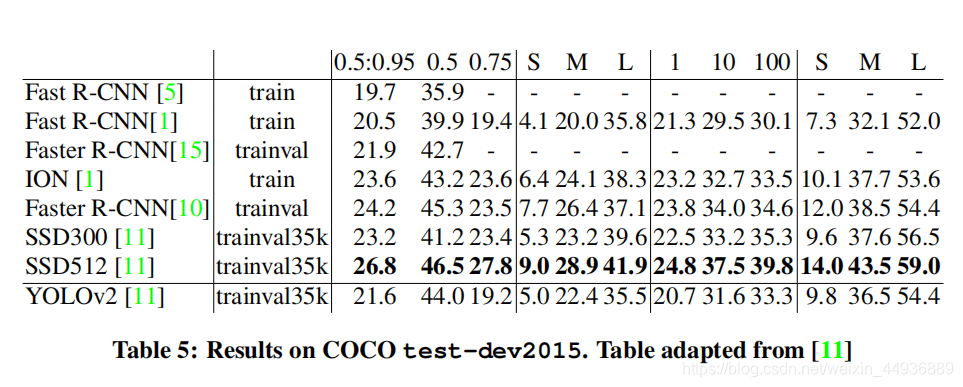
(十二)实验结果: