一、HDFS原理
1->HDFS 架构
HDFS是一个分布式文件系统。一个HDFS集群主要由一个 NameNode ,一个Secondary NameNode 和多个 Datanode 组成:Namenode管理文件系统的元数据,Datanode存储数据。

2->HDFS各个节点的功能
NameNode:Master节点,是领导。管理数据块映射;处理客户端的读写请求;监控nanmenode的健康状态;管理HDFS的名称空间。
注意:namenode内存中存储的是=fsimage+edits。

SecondaryNameNode:是秘书,分担领导namenode的工作量;是NameNode的冷备份;SecondaryNameNode负责定时默认1小时,从namenode上,获取fsimage和edits来进行合并,然后再发送给namenode。减少namenode的工作量。( 其中:fsimage:元数据镜像文件(文件系统的目录树。)edits:元数据的操作日志(针对文件系统做的修改操作记录))


3->HDFS读写数据原理

(2)读数据原理
客户端将要读取的文件路径发送给namenode,namenode获取文件的元信息(主要是block的存放位置信息)返回给客户端,客户端根据返回的信息找到相应datanode逐个获取文件的block并在客户端本地进行数据追加合并,从而获得整个文件

4->HDFS优缺点
*优点
(1) 适合大数据处理(支持GB,TB,PB级别的数据存储,支持百万规模以上的文件数量)
(2) 适合批处理(支持离线的批量数据处理,支持高吞吐率)
(3) 高容错性(以数据块存储,可以保存多个副本,容易实现负载均衡)
*缺点
(1) 小文件存取(占用namenode大量内存,浪费磁盘空间)
(2) 不支持并发写入(同一时刻只能有一个进程写入,不支持随机修改)
5->HDFS回收站
当删除某个文件时,这个文件并没有立刻从HDFS中删除。实际上,HDFS会将这个文件重命名转移到/trash目录。只要文件还在/trash目录中,该文件就可以被迅速地恢复。文件在/trash中保存的时间是可配置的,当超过这个时间时,Namenode就会将该文件从名字空间中删除。删除文件会使得该文件相关的数据块被释放。注意,从用户删除文件到HDFS空闲空间的增加之间会有一定时间的延迟。
二、mapreduce原理
MR有两个阶段组成:Map和Reduce,只需实现map()和reduce()两个函数,即可实现分布式计算
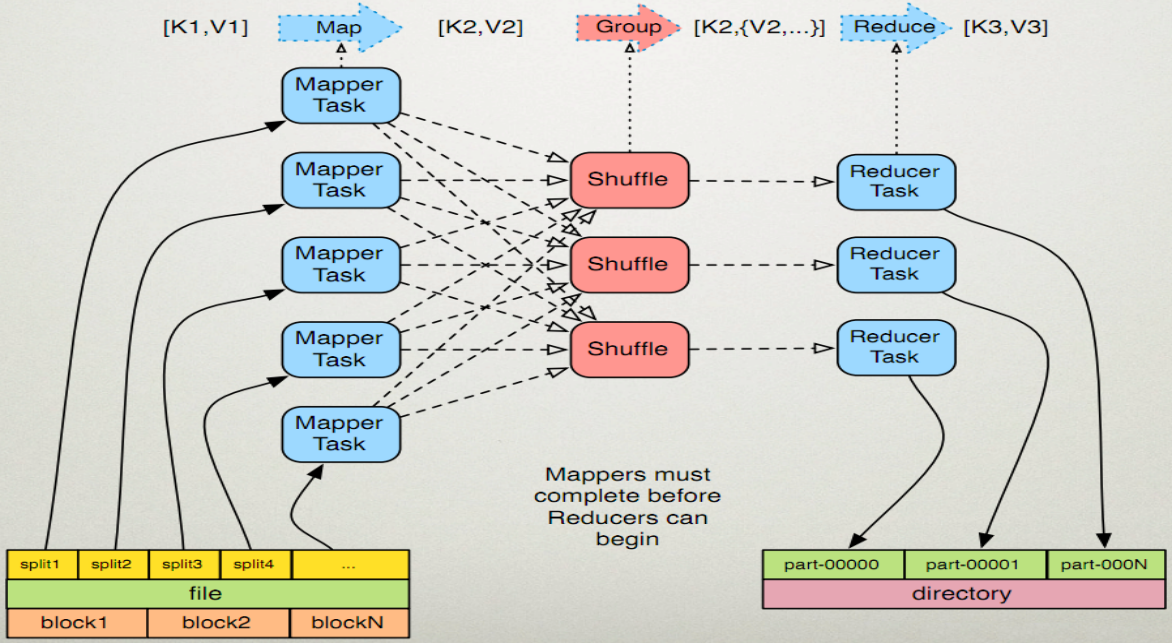
1->shuffle原理
MapReduce计算模型一般包括两个重要的阶段:Map是映射,负责数据的过滤分发;Reduce是规约,负责数据的计算归并。Reduce的数据来源于Map,Map的输出即是Reduce的输入,Reduce需要通过Shuffle来获取数据。从Map输出到Reduce输入的整个过程可以广义地称为Shuffle。Shuffle横跨Map端和Reduce端,在Map端包括Spill过程,在Reduce端包括copy和sort过程,如图所示:

2->执行过程
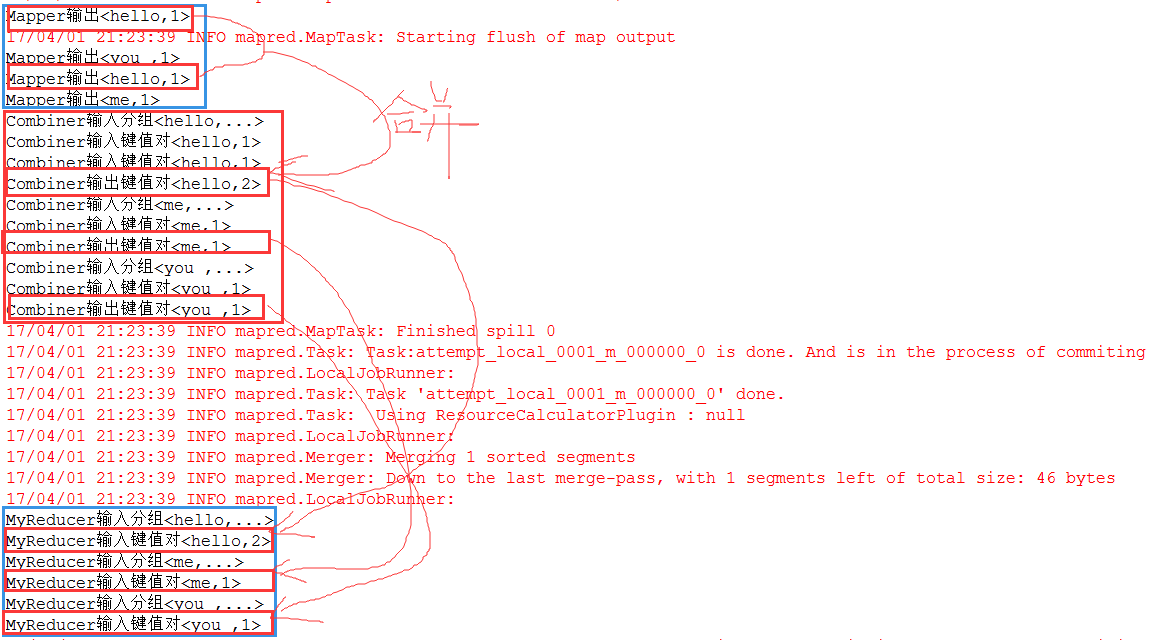
1、Map任务处理
1.1 读取HDFS中的文件。每一行解析成一个<k,v>。每一个键值对调用一次map函数。
<0,hello you> <10,hello me>
1.2 覆盖map(),接收1.1产生的<k,v>,进行处理,转换为新的<k,v>输出。
<hello,1> <you,1> <hello,1> <me,1>
1.3 对1.2输出的<k,v>进行分区。默认分为一个区。
1.4 对不同分区中的数据进行排序(按照k)、分组。分组指的是相同key的value放到一个集合中。
排序后:<hello,1> <hello,1> <me,1> <you,1> 分组后:<hello,{1,1}><me,{1}><you,{1}>
1.5 (可选)对分组后的数据进行归约:Combiner。
2、Reduce任务处理
2.1 多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点上。
2.2 对多个map的输出进行合并、排序。覆盖reduce函数,接收的是分组后的数据,实现自己的业务
逻辑,<hello,2> <me,1> <you,1>处理后,产生新的<k,v>输出。
2.3 对reduce输出的<k,v>写到HDFS中。
代码实现:
1 package combine; 2 3 import java.net.URI; 4 5 import org.apache.hadoop.conf.Configuration; 6 import org.apache.hadoop.fs.FileSystem; 7 import org.apache.hadoop.fs.Path; 8 import org.apache.hadoop.io.LongWritable; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.mapreduce.Job; 11 import org.apache.hadoop.mapreduce.Mapper; 12 import org.apache.hadoop.mapreduce.Reducer; 13 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 14 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 15 16 /** 17 * 问:为什么使用Combiner? 18 * 答:Combiner发生在Map端,对数据进行规约处理,数据量变小了,传送到reduce端的数据量变小了,传输时间变短,作业的整体时间变短。 19 * 20 * 问:为什么Combiner不作为MR运行的标配,而是可选步骤呢? 21 * 答:因为不是所有的算法都适合使用Combiner处理,例如求平均数。 22 * 23 * 问:Combiner本身已经执行了reduce操作,为什么在Reducer阶段还要执行reduce操作呢? 24 * 答:combiner操作发生在map端的,处理一个任务所接收的文件中的数据,不能跨map任务执行;只有reduce可以接收多个map任务处理的数据。 25 * 26 */ 27 public class WordCountApp { 28 static final String INPUT_PATH = "hdfs://chaoren:9000/hello"; 29 static final String OUT_PATH = "hdfs://chaoren:9000/out"; 30 31 public static void main(String[] args) throws Exception { 32 Configuration conf = new Configuration(); 33 final FileSystem fileSystem = FileSystem.get(new URI(INPUT_PATH), conf); 34 final Path outPath = new Path(OUT_PATH); 35 if(fileSystem.exists(outPath)){ 36 fileSystem.delete(outPath, true); 37 } 38 39 final Job job = new Job(conf , WordCountApp.class.getSimpleName()); 40 //1.1指定读取的文件位于哪里 41 FileInputFormat.setInputPaths(job, INPUT_PATH); 42 //指定如何对输入文件进行格式化,把输入文件每一行解析成键值对 43 //job.setInputFormatClass(TextInputFormat.class); 44 45 //1.2 指定自定义的map类 46 job.setMapperClass(MyMapper.class); 47 //map输出的<k,v>类型。如果<k3,v3>的类型与<k2,v2>类型一致,则可以省略 48 //job.setMapOutputKeyClass(Text.class); 49 //job.setMapOutputValueClass(LongWritable.class); 50 51 //1.3 分区 52 //job.setPartitionerClass(HashPartitioner.class); 53 //有一个reduce任务运行 54 //job.setNumReduceTasks(1); 55 56 //1.4 TODO 排序、分组 57 58 //1.5 规约 59 job.setCombinerClass(MyCombiner.class); 60 61 //2.2 指定自定义reduce类 62 job.setReducerClass(MyReducer.class); 63 //指定reduce的输出类型 64 job.setOutputKeyClass(Text.class); 65 job.setOutputValueClass(LongWritable.class); 66 67 //2.3 指定写出到哪里 68 FileOutputFormat.setOutputPath(job, outPath); 69 //指定输出文件的格式化类 70 //job.setOutputFormatClass(TextOutputFormat.class); 71 72 //把job提交给JobTracker运行 73 job.waitForCompletion(true); 74 } 75 76 /** 77 * KEYIN 即k1 表示行的偏移量 78 * VALUEIN 即v1 表示行文本内容 79 * KEYOUT 即k2 表示行中出现的单词 80 * VALUEOUT 即v2 表示行中出现的单词的次数,固定值1 81 */ 82 static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ 83 protected void map(LongWritable k1, Text v1, Context context) throws java.io.IOException ,InterruptedException { 84 final String[] splited = v1.toString().split("\t"); 85 for (String word : splited) { 86 context.write(new Text(word), new LongWritable(1)); 87 System.out.println("Mapper输出<"+word+","+1+">"); 88 } 89 }; 90 } 91 92 /** 93 * KEYIN 即k2 表示行中出现的单词 94 * VALUEIN 即v2 表示行中出现的单词的次数 95 * KEYOUT 即k3 表示文本中出现的不同单词 96 * VALUEOUT 即v3 表示文本中出现的不同单词的总次数 97 * 98 */ 99 static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable>{ 100 protected void reduce(Text k2, java.lang.Iterable<LongWritable> v2s, Context ctx) throws java.io.IOException ,InterruptedException { 101 //显示次数表示redcue函数被调用了多少次,表示k2有多少个分组 102 System.out.println("MyReducer输入分组<"+k2.toString()+",...>"); 103 long times = 0L; 104 for (LongWritable count : v2s) { 105 times += count.get(); 106 //显示次数表示输入的k2,v2的键值对数量 107 System.out.println("MyReducer输入键值对<"+k2.toString()+","+count.get()+">"); 108 } 109 ctx.write(k2, new LongWritable(times)); 110 }; 111 } 112 113 114 static class MyCombiner extends Reducer<Text, LongWritable, Text, LongWritable>{ 115 protected void reduce(Text k2, java.lang.Iterable<LongWritable> v2s, Context ctx) throws java.io.IOException ,InterruptedException { 116 //显示次数表示redcue函数被调用了多少次,表示k2有多少个分组 117 System.out.println("Combiner输入分组<"+k2.toString()+",...>"); 118 long times = 0L; 119 for (LongWritable count : v2s) { 120 times += count.get(); 121 //显示次数表示输入的k2,v2的键值对数量 122 System.out.println("Combiner输入键值对<"+k2.toString()+","+count.get()+">"); 123 } 124 125 ctx.write(k2, new LongWritable(times)); 126 //显示次数表示输出的k2,v2的键值对数量 127 System.out.println("Combiner输出键值对<"+k2.toString()+","+times+">"); 128 }; 129 } 130 }
三、YARN原理
1->什么是YARN
YARN是Hadoop2.0版本引进的资源管理系统,直接从MR1演化而来。
核心思想:将MR1中的JobTracker的资源管理和作业调度两个功能分开,分别由ResourceManager和ApplicationMaster进程实现。
ResourceManager:负责整个集群的资源管理和调度
ApplicationMaster:负责应用程序相关事务,比如任务调度、任务监控和容错等。
YARN的出现,使得多个计算框架可以运行在同一个集群之中。
2->YARN架构

从 YARN 的架构图来看,它主要由ResourceManager、NodeManager、ApplicationMaster和Container等以下几个组件构成。
1、 ResourceManager(RM)
YARN 分层结构的本质是 ResourceManager。这个实体控制整个集群并管理应用程序向基础计算资源的分配。ResourceManager 将各个资源部分(计算、内存、带宽等)精心安排给基础 NodeManager(YARN 的每节点代理)。ResourceManager 还与 ApplicationMaster 一起分配资源,与 NodeManager 一起启动和监视它们的基础应用程序。在此上下文中,ApplicationMaster 承担了以前的 TaskTracker 的一些角色,ResourceManager 承担了 JobTracker 的角色。
总的来说,RM有以下作用
1)处理客户端请求
2)启动或监控ApplicationMaster
3)监控NodeManager
4)资源的分配与调度
2、 ApplicationMaster(AM)
ApplicationMaster 管理在YARN内运行的每个应用程序实例。ApplicationMaster 负责协调来自 ResourceManager 的资源,并通过 NodeManager 监视容器的执行和资源使用(CPU、内存等的资源分配)。请注意,尽管目前的资源更加传统(CPU 核心、内存),但未来会带来基于手头任务的新资源类型(比如图形处理单元或专用处理设备)。从 YARN 角度讲,ApplicationMaster 是用户代码,因此存在潜在的安全问题。YARN 假设 ApplicationMaster 存在错误或者甚至是恶意的,因此将它们当作无特权的代码对待。
总的来说,AM有以下作用
1)负责数据的切分
2)为应用程序申请资源并分配给内部的任务
3)任务的监控与容错
3、 NodeManager(NM)
NodeManager管理YARN集群中的每个节点。NodeManager 提供针对集群中每个节点的服务,从监督对一个容器的终生管理到监视资源和跟踪节点健康。MRv1 通过插槽管理 Map 和 Reduce 任务的执行,而 NodeManager 管理抽象容器,这些容器代表着可供一个特定应用程序使用的针对每个节点的资源。
总的来说,NM有以下作用
1)管理单个节点上的资源
2)处理来自ResourceManager的命令
3)处理来自ApplicationMaster的命令
4、 Container
Container 是 YARN 中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示的。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。
1)任务运行资源(节点、内存、CPU)
2) 任务启动命令
3)任务运行环境
