文章目录
第5章:hadoop2.X分布式集群部署
hadoop2.x版本下载和安装
下载地址主要是这两个:
- https://archive.apache.org/dist 官网
- http://archive.cloudera.com/cdh5/ (推荐:版本稳定、各个框架之间的版本集成。企业中一般采用cdh的下载。因为cdh中提供了源码,且对各个框架进行了集成,所以除非有时候需要更高的版本去apache官网下载之外,企业最好用cdh下载)
hadoop2.x分布式集群配置-hdfs
(在hadoop中主要有两方面的配置:hdfs和yarn)
说明:
-
具体请根据官网文档配置 (http://hadoop.apache.org/docs/r2.5.2/hadoop-project-dist/hadoop-common/SingleCluster.html),下文只是大概概括一下实验中的配置
-
此实验配置机器1(namenode节点)的namenode,datanode;配置2,3机器(datenode)的datanode
相关步骤:
1.hadoop-env.sh
配置JAVA_HOME
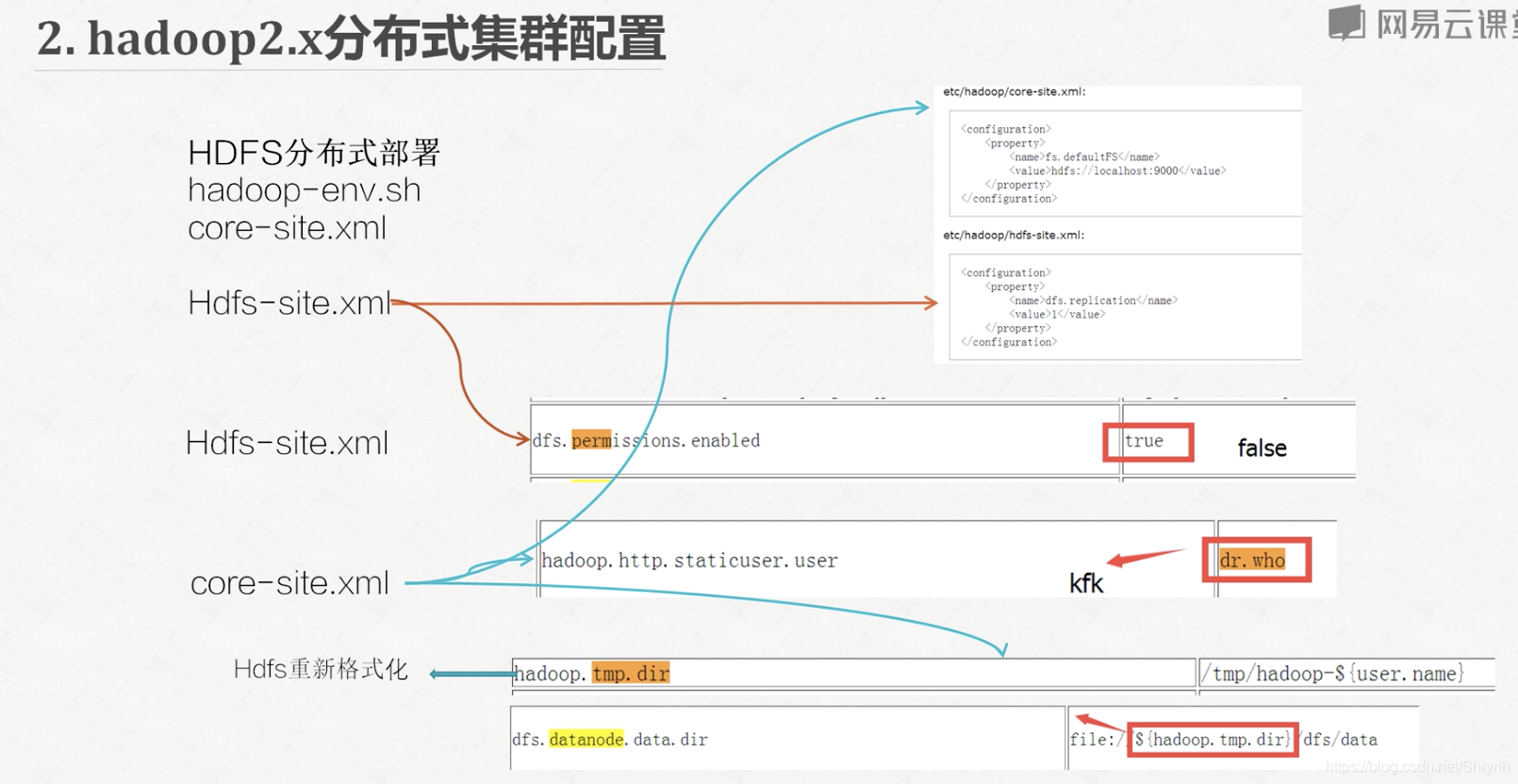
2.core-site.xml
配置namenode
http访问页面时显示的用户名
hadoop.tmp.dir //hdfs重新格式化
dfs.datanode.data.dir
3.hdfs-site.xml
文件副本数
dfs访问权限
4.slave从节点配置
配置目录下新建slaves文件,写入从节点
bigdata-pro01.ynh.com
bigdata-pro02.ynh.com
bigdata-pro03.ynh.com
补充:
-
课件截图
-
解压hadoop文件目录结构概览:
sbin-服务启动的脚本文件
bin-客户使用的命令
etc-所有hadoop配置文件 -
给解压后的hadoop文件瘦身:删掉
- ./share/doc
- ./etc/hadoop/*.cmd文件(这是在windows系统下的命令,linux不需要)
-
常用命令:
- sbin/hadoop-daemon.sh start/stop namenode
- sbin/hadoop-daemon.sh start/stop datanode
- bin/hdfs dfs -put file_source file_target
- bin/hdfs dfs -text file //可以以文本形式展示hdfs上的文件
- bin/hdfs namenode -format
测试运行:
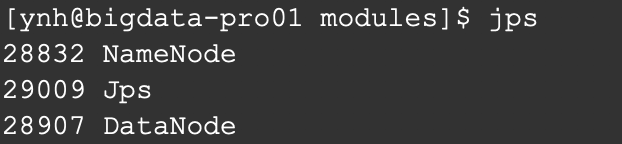
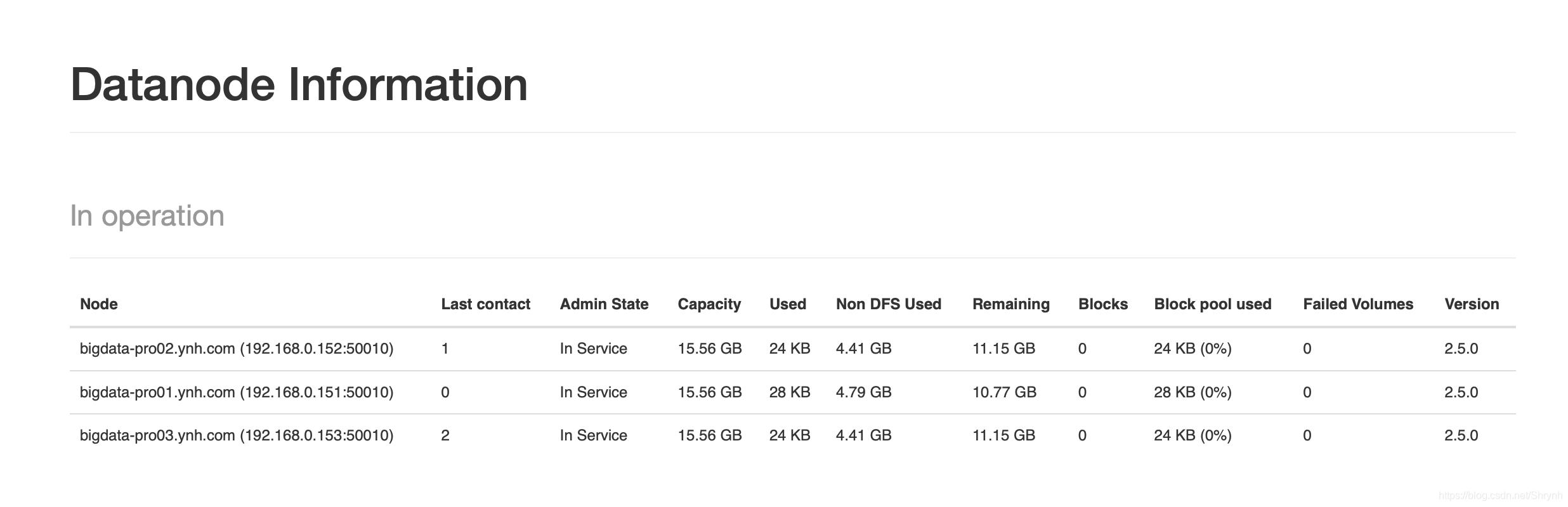
访问dfs的web界面,可以查看namenode和datanode信息
hadoop2.x分布式集群配置-yarn
说明:
- 此实验配置机器1的resourcemanager,
机器2,3的nodemanager - 配置hadoop.tmp.dir之后,hdfs默认配置里的引用${hadoop.tmp.dir}也会变化,所以要重启服务
- 停掉rm
停掉nm
停掉jobhistory
停掉namenode
停掉datanode
- 停掉rm
步骤:
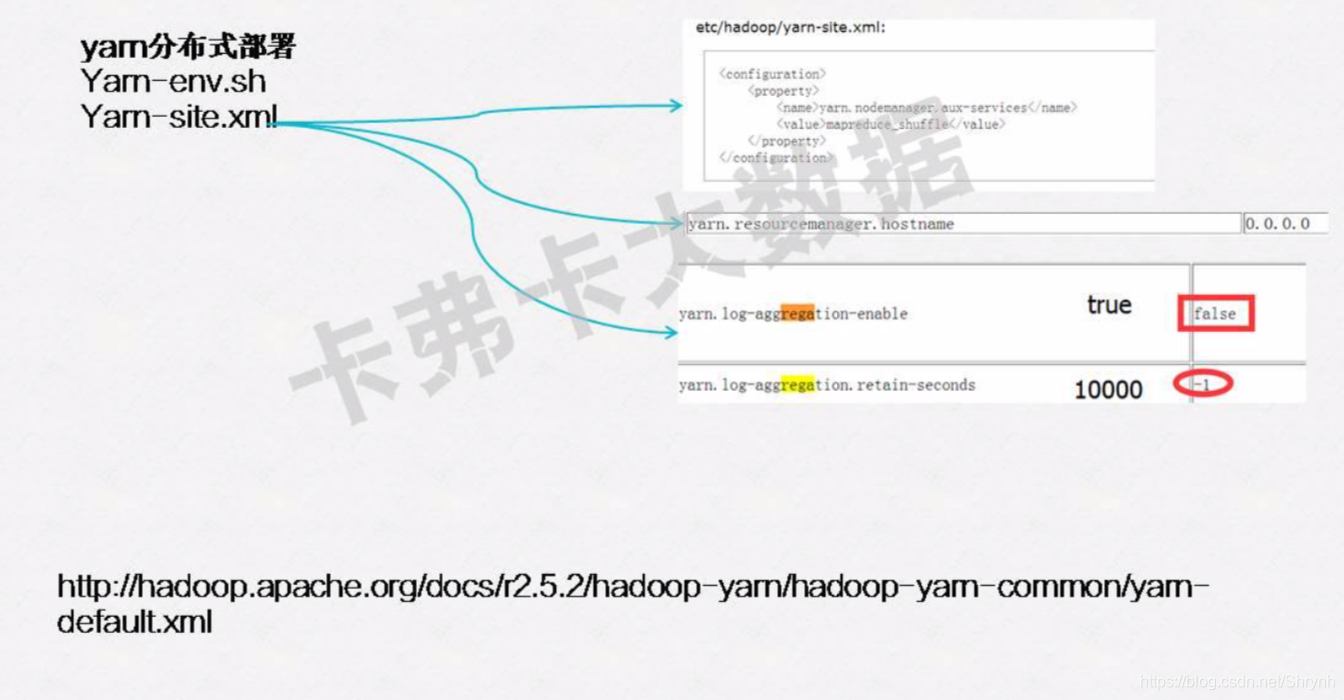
1.yarn-env.sh
配置JAVA_HOME
2.yarn-site.xml
3.mapreduce部署

总结<配置hdfs和yarn>:
具体配置可以参考参数官网给出的default文件http://hadoop.apache.org/docs/r2.5.2/hadoop-project-dist/hadoop-common/ClusterSetup.html
-
env配置
-
hdfs
- core-site.xml
- hdfs-site.xml
-
mapred
- mapred-site.xml:
-
slaves:
- slaves:从节点
-
yarn:
- yarn-site.xml
hadoop2.x分布式集群配置-取消授权
分发到其他各个及节点
scp -r hadoop-2.5.0/ [email protected]
scp -r hadoop-2.5.0/ [email protected]
hdfs启动集群运行测试
1.格式化namenode
bin/HDFS namenode -format
2.启动各个节点机器服务
namenode
datanode
resourcemanager
nodemanager
Jobhistoryserver historyserver
结果:
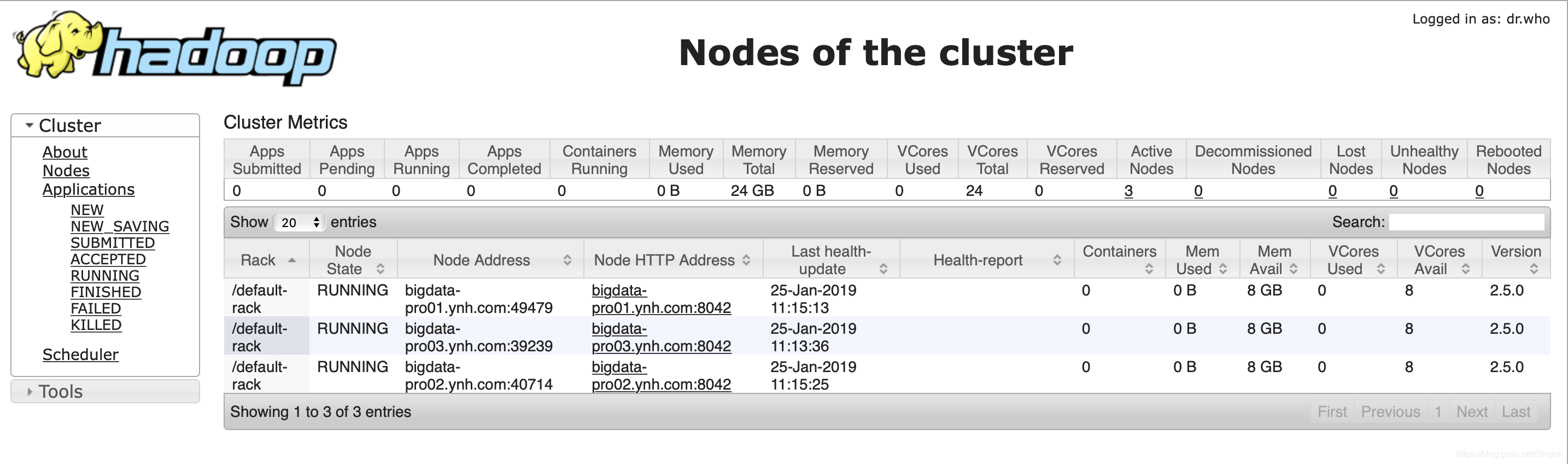
启动jobhistory (启动之后,hdfs上会有一个tmp目录,存放日志)
yarn集群运行mapreduce程序测试
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount data_source file_target
配置集群中主节点到各个机器的ssh无秘钥登录
说明:
集群中的主节点(namenode节点、RM节点)都要配置。此例中因为RM和namenode都在pro1,所以只配一台。
步骤:
(主机1:)
1.清空此机的.ssh目录(如果之前没有配置ssh无秘钥登录)
2.生成一对公钥与秘钥
ssh-keygen -t rsa
3.拷贝公钥到各个机器上
ssh-copy-id bigdata-pro01.ynh.com
ssh-copy-id bigdata-pro02ynh.com
ssh-copy-id bigdata-pro03.ynh.com
4.测试ssh连接
ssh bigdata-pro01.ynh.com
ssh bigdata-pro02ynh.com
ssh bigdata-pro03.ynh.com
5.测试hdfs
sbin/stop-dfs.sh
(之后,可以直接使用sbin/start-dfs.sh 和sbin/start-yarn.sh命令来启动/停止hdfs和yarn相关的服务)
配置集群内机器时间同步(使用Linux ntp进行)
步骤:
1.启动集群机器的ntpd服务
sudo rpm -qa|grep ntp //查看是否安装ntp服务
sudo service ntpd start //启动
sudo service ntpd status //检测是否启动
2.找一台机器作为时间服务器 bigdata-pro01.ynh.com
修改配置文件:
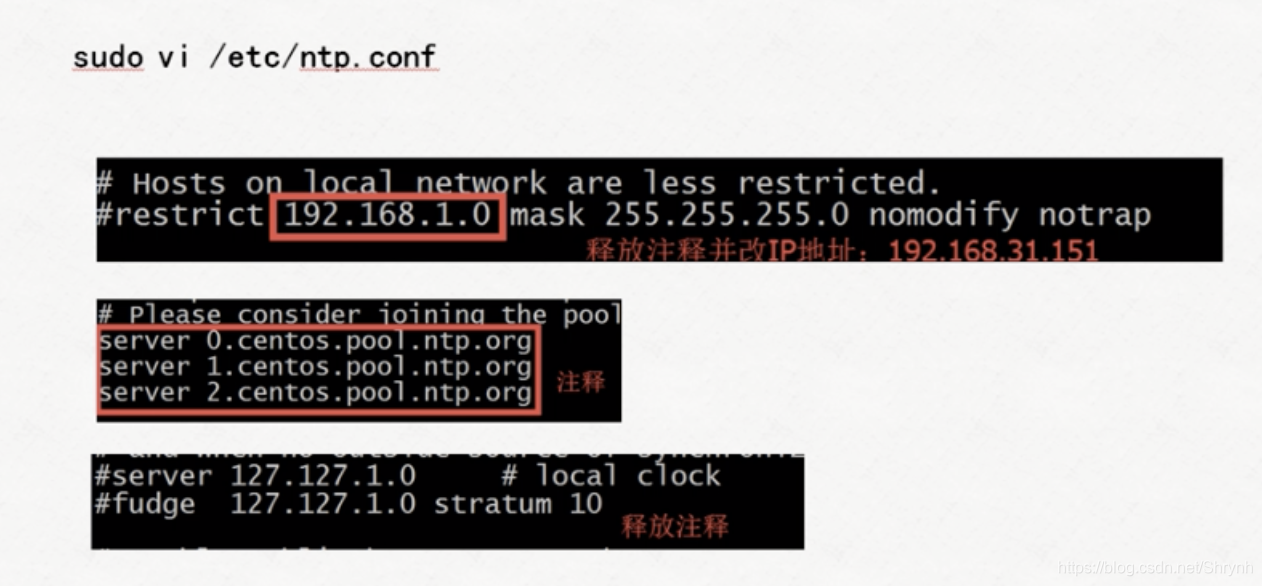 重启服务
重启服务
sudo service ntpd restart
调整时间服务器的时间
date -s YYYY-MM-dd HH:mm:ss //设置时间
3.设置时间服务器的ntpd服务随机器启动
sudo chkconfig ntpd on
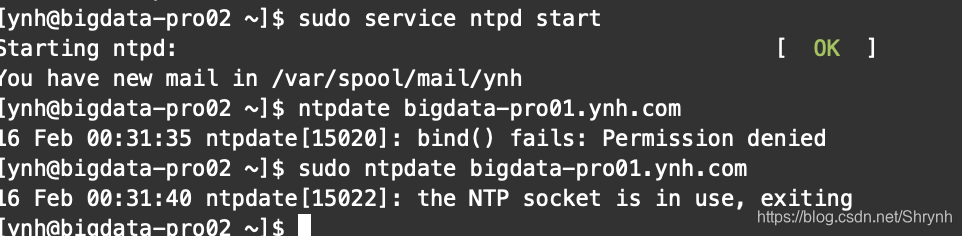
4.集群内机器同步时间服务器的时间值(手动)
ntpdate bigdata-pro01.ynh.com
5.其他机器
关闭ntpd服务
sudo service ntpd stop
否则会提示以下错误,导致接下来的定时任务脚本无法正确执行,进而导致后面章节中的HBase(时间敏感度很高)服务无法正常启动:
写定时任务,每过一段时间与时间服务器进行时间同步
which ntpdate
切换到root用户
编写脚本:
crontab -e
添加内容:
0-59/10 * * * * /usr/sbin/ntpdate bigdata-pro01.ynh.com
6.补充:保证机器与bios时间同步(可选)
vi /etc/sysconfig/ntpd
文件首行添加:
SYNC_HWCLOCK=yes