Hadoop2.X MR作业流
情景概述:作为HFDS的高层建筑,MR被设计与在大型分布式文件系统之上的离线数据运算,在对一些运算时效性要求不高的场景中更适合于MR作业,MR在ETL流不同阶段可扮演不同的角色,甚至在某些场景下基于MR的链式操作可完成ETL的整个流程.
MR概述:Hadoop MR(Mapper Reduce) 是一个软件架构的实现,用户处理大批量的的离线数据作业,运行于大型集群中,硬件可靠和容错.MR核心思想将作业的输入转化为多个并行的Map程序,然后进行Reduce输出运算结果.作业的输入和输出都存储于文件系统,由MR 框架负责作业的调度,监控和失败重试.
| 基于基于计算优于移动数据的设计,MR运算节点与数据节点通常是同一个节点.
| MR框架有一个ResourceManager主节点每一个集群节点上有一个NodeManager每一个应用程序有一个MRAppMaster
| 一个MR程序至少应该有 输入/输出,输入Map以及 Reduce函数,通常由实现适当的接口或者抽象类而来. 还应该有其它的作业参数包括作业的配置参数
| Hadoop作业由job client进行提交,jobclient配置ResourceManager,ResourceManager分配资源及集群节点,然后开始调度,监控任务,为job-client提供任务状态和诊断信息
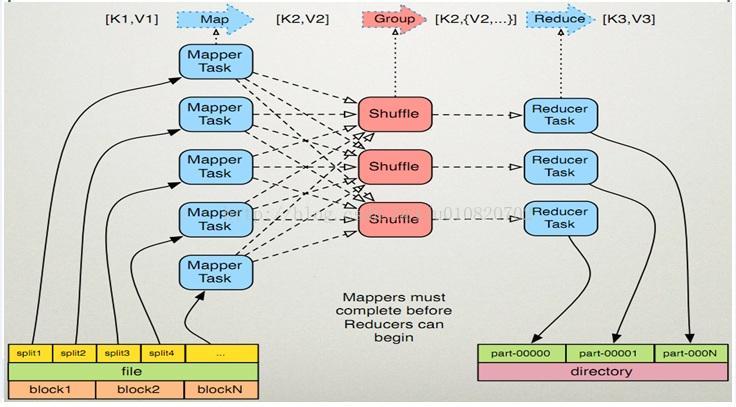
MR作业流,图片来源于互联网
输入,输出:
| MR作业基于<key,value>对展开作业,框架以一组<key,value>作为输入,一组<key,value>作为输出,期间数据类型可以发生变化.
| 分布式作业中,MR要求key,value必须是可序列化的需要实现Writable接口,此外key必须实现WritableComparable接口用于MR框架进行以key为依据的排序操作
| 一个MR作业的输入/输入看起来是如下的一种演变:
(input) <k1, v1> -> map -><k2, v2> -> combine -> <k2, v2> -> reduce -> <k3,v3> (output)
MR接口
| Mapper接口用于将作业的输入映射到key/value集合,Mapper 操作输入key/value集合生成中间key/values记录,一个给定的输入可能对应0个或者多个输出key/values对,Mapper接口定义如下
public class Mapper<KEYIN, VALUEIN,KEYOUT, VALUEOUT> {
…
public voidrun(Context context) throws IOException, InterruptedException {
}
}
| Shuffle,对Maplper阶段的输出数据进行Shuffle操作,期间伴随数据的排序操作.
| Sort,MR框架默认使用keys对Reduce的输入数据进行分组,Mapper操作处理的是Reduce阶段输出按key分组后的数据.
| Secondary Sort,可通过实现Comparator接口通过Job.setSortComparatorClass(Class) 来自定义key的比较规则来实现key的排序,可通过 Job.setGroupingComparatorClass(Class)来指定key分组的规则,
| Reduce 接口用户合并多个Mapper操作的中间结果,一个MR作业中可允许多个Reduce并发处理. Reduce通常涉及三个阶段,shuffle,sort,reduce,Reduce接口如下
public classReducer<KEYIN,VALUEIN,KEYOUT,VALUEOUT>{
…
protected void reduce(KEYIN key, Iterable<VALUEIN> values,Context context
) throws IOException,InterruptedException {
}
}
| Reducer NONE, MR框架允许一个MR作业只有Mapper操作而没有Reduce操作,这样Mapper的输出将直接输出到对应的文件系统,且在输出到文件系统前不会发生排序操作.
| Partitioner, Partitioner 对Mapper操作的中间结果按key进行划分,分区数和Reduce数量一致, Partitioner控制着中间结果的key会被分配到多个Reduce中的哪一个进行Reduce操作.
| Counter, MR提供的计数组件,用于统计MR状态.
附件:
| 一个默认的MR程序,补全了默认的加载项:,该例是完整的可直接运行
public class T {
publicstatic void main(String[] args) throws Exception {
Configurationconf = new Configuration();
Jobjob = Job.getInstance(conf, "TEST");
//默认的输入配置
{
/*
* key:LongWriteable ;value:Text
*/
job.setInputFormatClass(TextInputFormat.class);
}
//Mapper默认配置
{
job.setMapperClass(Mapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
}
//默认的Map路由算法
{
/*对每条记录进行Hash操作决定该记录应该属于哪个分区,每个分区对应一个Reduce任务 ==>分区数等于作业Reduce的个数*/
job.setPartitionerClass(HashPartitioner.class);
}
//Reduce默认配置
{
/*Reduce之前数据被使用key值进行过排序操作*/
job.setReducerClass(Reducer.class);
job.setNumReduceTasks(1);
}
//默认的输出配置
{
/*将键/值转换成字符串并使用制表符分开,然后一条一条的进行输出*/
job.setOutputFormatClass(TextOutputFormat.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(Text.class);
}
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
if(!job.waitForCompletion(true))
return;
}
}
| WorldCout 实现,该例是完整的
public class WordCount {
publicstatic void main(String[] args) throws Exception {
Configurationconf = new Configuration();
Jobjob = Job.getInstance(conf, "WordCount");
job.setInputFormatClass(CombineTextInputFormat.class);
job.setJarByClass(cn.com.xiaofen.A.WordCount.class);
job.setMapperClass(WordMaper.class);
job.setReducerClass(WordReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
CombineTextInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
if(!job.waitForCompletion(true))
return;
}
}
class WordMaper extendsMapper<LongWritable, Text, Text, IntWritable> {
publicvoid map(LongWritable ikey, Text ivalue, Context context) throws IOException,InterruptedException {
Textword = null;
finalIntWritable one = new IntWritable(1);
StringTokenizerst = new StringTokenizer(ivalue.toString());
while(st.hasMoreTokens()) {
word= new Text(st.nextToken());
context.write(word,one);
}
}
}
class WordReduce extends Reducer<Text,IntWritable, Text, IntWritable> {
@Override
protectedvoid reduce(Text key, Iterable<IntWritable> values, Context context)
throwsIOException, InterruptedException {
intsum = 0;
for(IntWritable intw : values) {
sum+= intw.get();
}
context.write(key,new IntWritable(sum));
}
}
| 一个稍复杂的示例,TOPN实现
public class CarTopN {
publicstatic final String TOPN = "TOPN";
publicstatic void main(String[] args) throws Exception {
Pathinput = new Path(args[0]);
Pathoutput = new Path(args[1]);
IntegerN = Integer.parseInt(args[2]);
Configurationconf = new Configuration();
//define the N
conf.setInt(CarTopN.TOPN,N);
Jobjob = Job.getInstance(conf, "CAR_Top10_BY_TGSID");
job.setJarByClass(cn.com.zjf.MR_04.CarTopN.class);
job.setInputFormatClass(CombineTextInputFormat.class);
job.setMapperClass(CarTopNMapper.class);
//not use
//job.setCombinerClass(Top10Combine.class);
job.setReducerClass(CarTopNReduce.class);
job.setNumReduceTasks(1);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setPartitionerClass(ITGSParition.class);
FileSystemfs = FileSystem.get(conf);
//预处理文件 .只读取写完毕的文件 .writed结尾 .只读取文件大小大于0的文件
{
FileStatuschilds[] = fs.globStatus(input, new PathFilter() {
publicboolean accept(Path path) {
if(path.toString().endsWith(".writed")) {
returntrue;
}
returnfalse;
}
});
Pathtemp = null;
for(FileStatus file : childs) {
temp= new Path(file.getPath().toString().replaceAll(".writed",""));
if(fs.listStatus(temp)[0].getLen() > 0) {
FileInputFormat.addInputPath(job,temp);
}
}
}
CombineTextInputFormat.setMaxInputSplitSize(job,67108864);
//强制清理输出目录
if(fs.exists(output)) {
fs.delete(output,true);
}
FileOutputFormat.setOutputPath(job,output);
if(!job.waitForCompletion(true))
return;
}
}
class ITGSParition extendsPartitioner<Text, Text> {
@Override
publicint getPartition(Text key, Text value, int numPartitions) {
return(Math.abs(key.hashCode())) % numPartitions;
}
}
class CarTopNMapper extendsMapper<LongWritable, Text, Text, IntWritable> {
@Override
protectedvoid map(LongWritable key, Text value, Mapper<LongWritable, Text, Text,IntWritable>.Context context)
throwsIOException, InterruptedException {
Stringtemp = value.toString();
if(temp.length() > 13) {
temp= temp.substring(12);
String[]items = temp.split(",");
if(items.length > 10) {
//CarPlate As Key
try{
Stringtgsid = items[14].substring(6);
Integer.parseInt(tgsid);
context.write(newText(tgsid), new IntWritable(1));
}catch (Exception e) {
e.printStackTrace();
}
}
}
}
}
class CarTopNCombine extendsReducer<Text, IntWritable, Text, IntWritable> {
//有序Map 始终存储TOPN,不存储多余的数据
privatefinal TreeMap<Integer, String> tm = new TreeMap<Integer, String>();
privateint N;
@Override
protectedvoid setup(Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throwsIOException, InterruptedException {
Configurationconf = context.getConfiguration();
N= conf.getInt(CarTopN.TOPN, 10);
}
@Override
protectedvoid reduce(Text key, Iterable<IntWritable> values,
Reducer<Text,IntWritable, Text, IntWritable>.Context context) throws IOException,InterruptedException {
Integerweight = 0;
for(IntWritable iw : values) {
weight+= iw.get();
}
tm.put(weight,key.toString());
//保证只有TOPN
if(tm.size() > N) {
tm.remove(tm.firstKey());
}
}
@Override
protectedvoid cleanup(Reducer<Text, IntWritable, Text, IntWritable>.Contextcontext)
throwsIOException, InterruptedException {
//将最终的数据进行发射输出给下一阶段
for(Integer key : tm.keySet()) {
context.write(newText("byonet:" + tm.get(key)), new IntWritable(key));
}
}
}
// Top10核心计算方法
// 尽量避免在Java集合中存储Hadoop数据类型,可能会出现奇怪的问题
class CarTopNReduce extendsReducer<Text, IntWritable, Text, IntWritable> {
privatefinal TreeMap<Integer, String> tm = new TreeMap<Integer, String>();
privateint N;
@Override
protectedvoid setup(Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throwsIOException, InterruptedException {
Configurationconf = context.getConfiguration();
N= conf.getInt(CarTopN.TOPN, 10);
}
@Override
protectedvoid reduce(Text key, Iterable<IntWritable> values,
Reducer<Text,IntWritable, Text, IntWritable>.Context arg2) throws IOException,InterruptedException {
Integerweight = 0;
for(IntWritable iw : values) {
weight+= iw.get();
}
tm.put(weight,key.toString());
if(tm.size() > N) {
tm.remove(tm.firstKey());
}
}
@Override
protectedvoid cleanup(Reducer<Text, IntWritable, Text, IntWritable>.Contextcontext)
throwsIOException, InterruptedException {
for(Integer key : tm.keySet()) {
context.write(newText("byonet:" + tm.get(key)), new IntWritable(key));
}
}
}