学习资源(仅供参考)
- https://study.163.com/course/courseLearn.htm?courseId=1004043006#/learn/video?lessonId=1044711277&courseId=1004043006 网课地址-【企业级】大数据项目实战
- https://blog.csdn.net/u011254180/article/details/80172452
- http://www.raincent.com/content-10-11077-1.html 具体的架构参考
- https://www.cnblogs.com/daiwei1981/p/10033735.html (架构文档)用户点击行为实时分析系统spark
数据源:搜狗实验室https://www.sogou.com/labs/resource/cs.php
第2章:实战前hadoop2.X必修课
hadoop2.x概述
1.什么是hadoop
- 开源的
- 可靠的 (备份机制)
- 可扩展性 (大的集群,机器动态的增加和减少不会影响集群的运行)
- 分布式计算 (集群并行地处理比单机效率高很多。任务并行处理)
2.解决的问题 (核心问题)
- 海量(至少几十G以上吧)数据的存储——hdfs (补充:目前最大的PC内存几G,本地磁盘最大几T,但也需要硬件和系统相匹配,成本太高?)
- 存海量数据(单台机器存储不了的)
- 动态地添加/卸载机器(不会影响整个集群分布式存储)
- 备份机制(保证数据完整性,默认备份3份)
- ->快速自动恢复(自动检测的,不需要人工检测),当数据文件损坏时
- 海量数据分析——mapreduce
- 海量
- 核心理念——分而治之(数据分片到节点并行处理。这个思想就是来自于生活)
- 集群资源的管理和任务调度——yarn (hdoop2.0之后)
- 资源管理(CPU、内存)
- 任务调度
3.特点
- 扩容能力(动态增加/卸载,过程中不会影响数据存储和运算)
- 成本低(普通PC也可以充当集群中的一个节点,不一定需要服务器去做)
- 高效率
- 可靠性 (实时保证数据完整性:备份、自动恢复机制)
4.产生背景
来源于三大论文:
GFS -hdfs
mapreduce
bigtable -hbase
5.应用场景
- 日志分析 (特别是互联网公司,每天产生上百G)
- 推荐系统 (大数据存储->分析->算法……)
- GPS 路况信息推送(大数据收集->……)
- 天气预报
- 医疗
- ……
6.hadoop生态圈
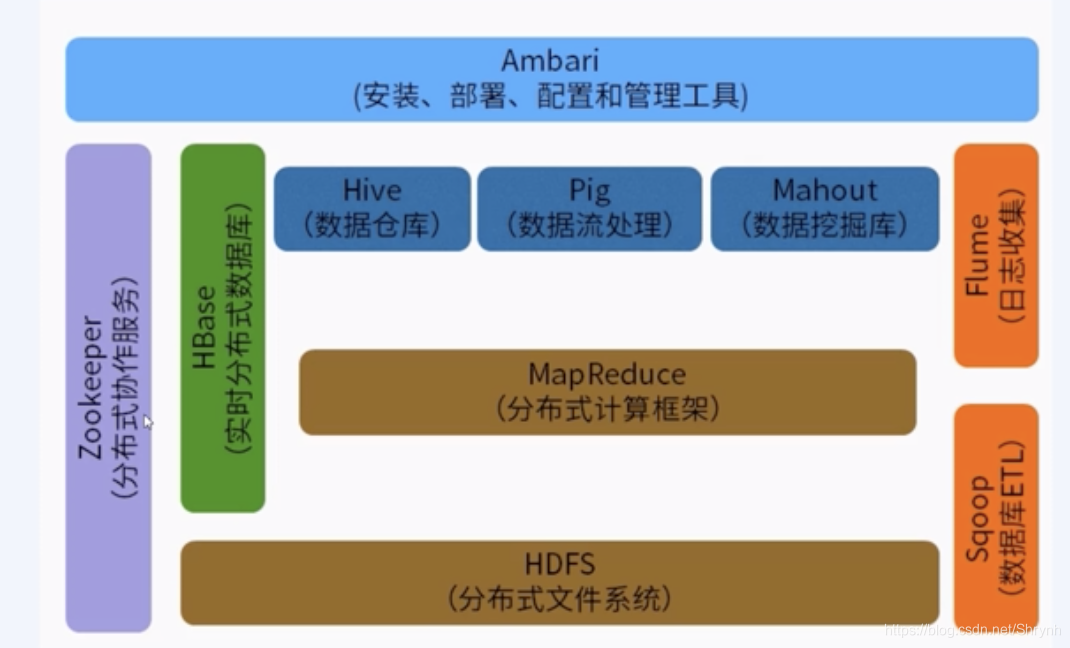
hdfs:数据存储的基石
Zookeeper(分布式协作服务):一般涉及到HA 高可用性时使用
HBase(实时分布式数据库):数据还是存储在hdfs上,只是采用自己的一套查询机制
Hive(数据仓库):数据还是存储在hdfs上,可以使用sql语句进行查询分析
Flume(日志收集):收集日志
Sqoop(数据库ETL):将关系型数据库数据放到hdfs上,或者反向抽取。
MapReduce(分布式计算框架):离线数据计算
7.hadoop的核心内容
查看官网描述
hadoop 4个基础模块:
common包
hdfs
yarn
mapreduce:yarn-based (yarn:大白话可以理解成“大数据的虚拟操作系统”,任务执行需要一个管理cpu、内存等的平台进行支撑)
hdfs分布式文件系统框架原理详解
1.解决的问题
-
海量数据的存储->分布式架构设计
-
分布式特点:集群,多台机器共同协作完成;主从架构设计(联想实际:一个任务设定管理者和开发经理)
1)namenode -主节点- 存储文件的元数据
a.文件的名称
b.文件的位置
c.副本数
d.拥有者、组、权限
e.存储块(一个块默认为256M)
f.各个块在哪些datanode上
……
2)datanode -从节点
- 文件的存储
- 存储文件的元数据
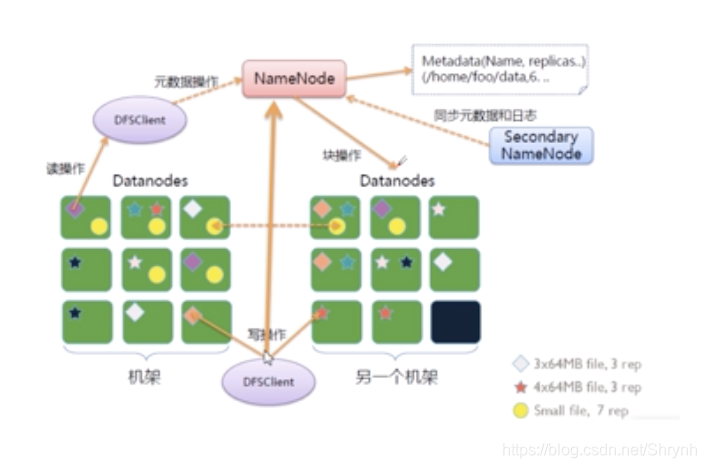
(机架定义:连接在统一台交换机上的服务器统称为一个机架。某个文件的副本尽量保证放在不同的机架上)3)读文件
client->namenode(元数据)
client->datanode (通过流的方式,就近原则从服务器拿数据)4)写数据
client->namenode(申请,开辟空间)
client->datanode(写数据)
->namenode(更新元数据) -
mapreduce架构设计和原理详解
离线计算框架
核心思想——分而治之
现实案例并行计算流程:
1)分割(如在hdfs以块存储)
2)分割文件(数据文件,程序包)分发到每台机器上
3)每台机器数据计算
4)获取每台机器的计算结果
5)合并每台机器的计算结果
6)生成数据分析结果

1.将数据分为两个阶段,Map和Reduce
- map阶段并行处理输入数据
- reduce阶段对map结果进行汇总
2.shuffle连接map和reduce两个阶段
- map shuffle
- reduce shuffle
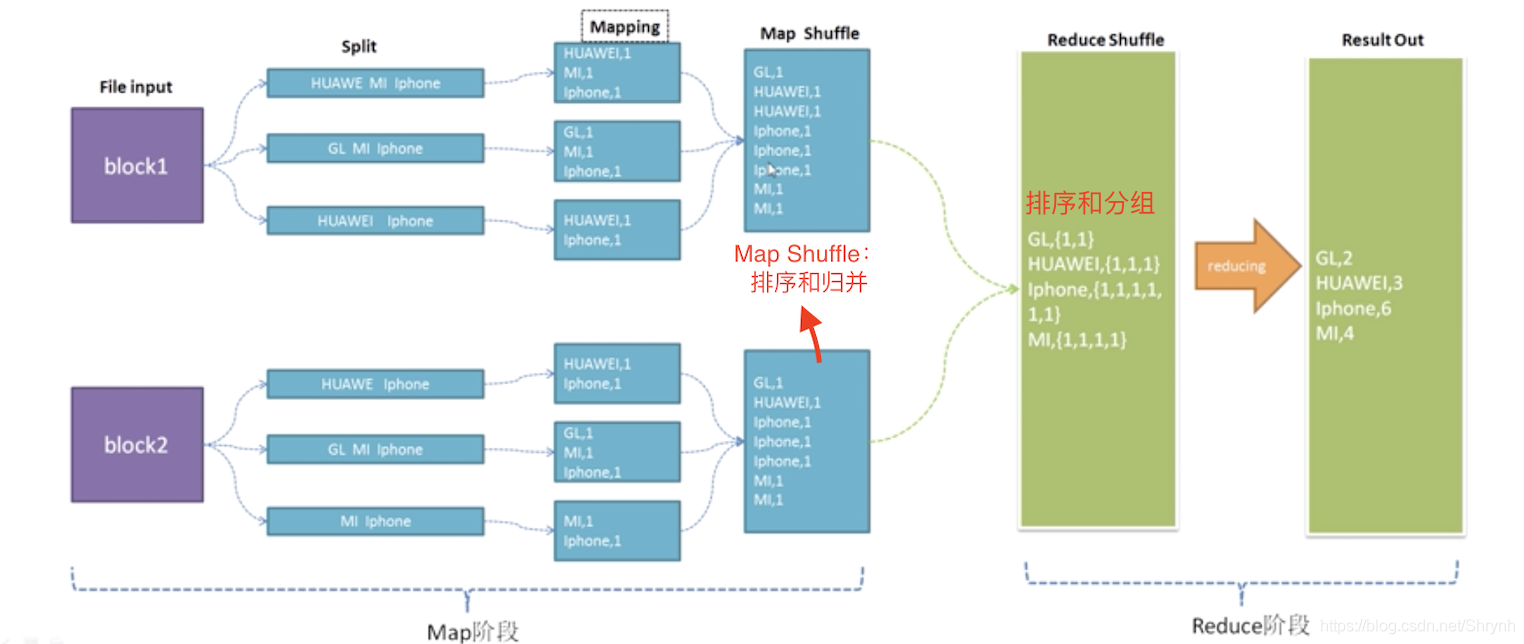
(下图建议自己多画一下,了解细节)
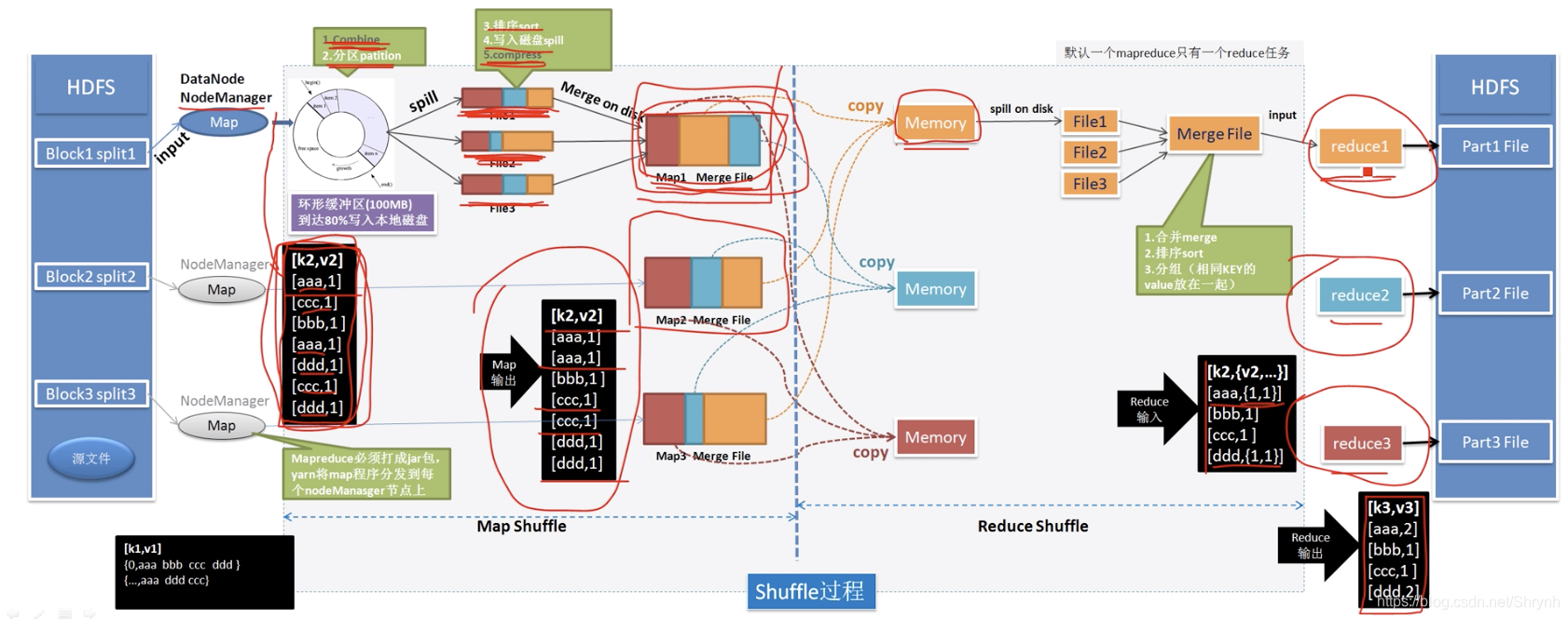
备注:
1.一般DataNode服务和NodeManager服务是在同一个节点服务器,节省远程IO操作。
2.环形缓冲区:map输出存放的地方。超出会spill到本地磁盘。在缓冲区中就做好combine(可选,优化项)、分区(即给key建立对应reduce任务的索引)了。
3.combine、compress是mapreduce进行优化的两个指标,初期可不做。
4.combiner设置之后后面必须要有reduce阶段,否则,它是不起作用的。(建议在分区之前就设置combiner,小合并下数据)
3.仅适合离线批处理
- 具有很好的容错性和扩展性
- 适合加单的批处理任务
4.缺点明显
- 启动开销大,过多使用磁盘导致效率低下等
YARN资源管理架构原理详解
yarn ——集群资源的管理与任务调度的分布式框架
1.分布式框架:主从框架
2.yarn的功能
1)功能一:集群资源的管理
- 主节点 ——RM ——ResourceManager (整个集群资源的管理)
- 从节点 ——ND ——NodeManager (每一个节点管理服务器)
yarn架构图
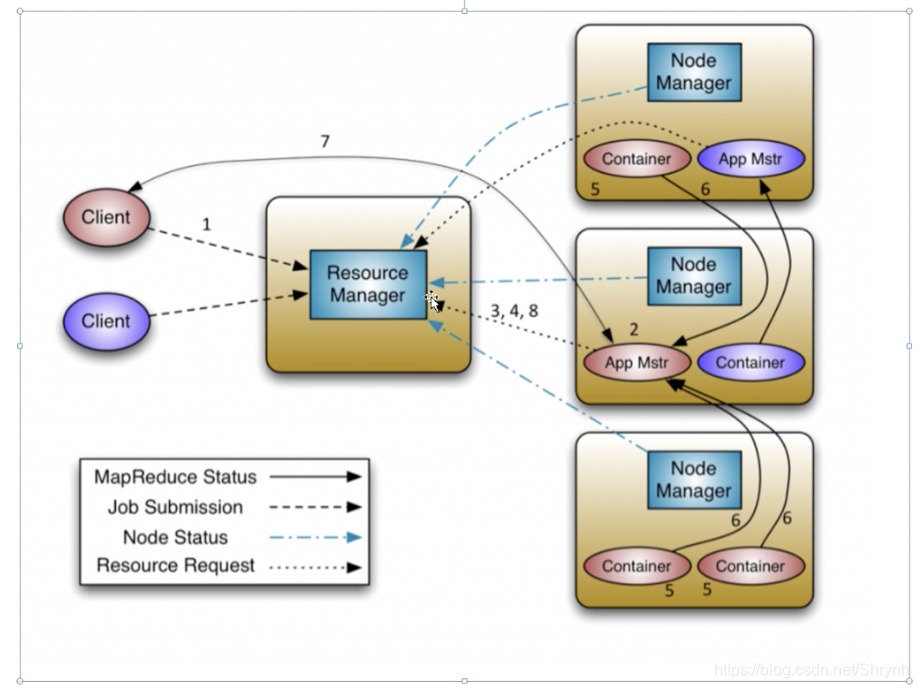
「完整过程」
client提交一个应用之后,给到RM,RM为应用程序在某个节点服务器上生成一个App Mstr(Application Master,类比一个项目经理),运行这个应用的管理程序。App Mstr 根据任务情况向RM请求资源分配(RM会给每个任务分配一个Container,保证互不干扰),分配好之后,所分配的Container还要时刻与App Mstr保持心跳通信,由App Mstr进行监控和管理。运行完之后,app Mstr向RM报告,从而释放资源。
然后,整个集群的情况由每一个NodeManager定期向RM报告该节点的情况。
2)功能二:任务调度
- yarn上运行多个应用程序
- 对应用程序的资源如何进行分配
- yarn如何任务调度
ResouceManager:
- 处理客户端请求
- 启动/监控Application Master
- 监控NodeManager
- 资源分配与调度
NodeManager:
- 单个节点管理
- 处理来自Resouce Manager的命令 (比如为RM生成的App Mstr分配运行空间)
- 处理来自ApplicationMaster的命令(比如帮App Mastr启动每一个Container里的任务)
ApplicationMaster:
- 申请资源(根据任务情况向RM请求资源分配)
- 监控、管理NodeManager上的任务运行情况
Container:
- 对资源抽象和封装,目的是为了让每一个应用程序对应的任务完整执行,任务间互不影响,任务不能相互交叉使用和共享。
—————————————————————————————————————
说明:
此系列文章为网课学习时所记录的笔记,希望给同为小白的学习者贡献一点帮助吧,如有理解错误之处,还请大佬指出。学习不就是不断纠错不断成长的过程嘛~