关于提升方法的 研究很多,有很多算法被提出。最具代表性的是AdaBoost算法(AdaBoost algorithm)。
提升方法就是从弱学习算法出发,反复学习, 得到一系列弱分类器(又称为基本分类器),然后组合这些弱分类器,构成一个强分类 器。
对提升方法来说,有两个问题需要回答:一是在每一轮如何改变训练数据的权 值或概率分布;二是如何将弱分类器组合成一个强分类器。关于第1个问题,AdaBoost的 做法是,提高那些被前一轮弱分类器错误分类样本的权值,而降低那些被正确分类样本的 权值。这样一来,那些没有得到正确分类的数据,由于其权值的加大而受到后一轮的弱分 类器的更大关注。于是,分类问题被一系列的弱分类器“分而治之”。至于第2个问题,即 弱分类器的组合,AdaBoost采取加权多数表决的方法。具体地,加大分类误差率小的弱分 类器的权值,使其在表决中起较大的作用,减小分类误差率大的弱分类器的权值,使其在 表决中起较小的作用。

算法解释:
输入数据有N个,每个数据对应1个权值参数wi.那么有N个训练数据有N个权值参数i∈1-n。集合记为D。 m指的是第m轮的迭代,m∈1-M。G代表分类器。
第(1)中,先把所有权值参数w设置为相同的。值为1/N。集合为D1.
AdaBoost反复学习基本分类器,在每一轮m=1,2,…,M顺次地执行下列2-4步操 作。
第(2)步,用每一轮的权值分布Dm的训练数据集学习,得到基本分类器,分类器Gm(Xi)对训练数据Xi进行分类。
根据第m轮分类器Gm分类出来的结果G(xi) = {+1,-1}和实际的结果yi.
一般通常我们会得到的损失函数是, ,但这里因为每个Xi都是有权值的,所以真正误差应该记为
,但这里因为每个Xi都是有权值的,所以真正误差应该记为
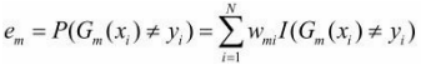
第(3)步,有了误差我们可以计算出当前这个分类器应该给他什么样的权值。
计算其系数为:

这里的对数是自然对数。
这样就得到了该轮的一个模型,

第(4)步,有了模型的系数am,我们可以遍历计算出下一轮m+1轮每个输入数据Xi的权值系数W(m+1,i).


得到下一轮的数据权重集合:
![]()
这样就可以跳到第(2)步进行下一轮循环,一直到M轮。
第(5)步:
最后把这M轮得到的每个弱分类器乘以权重am,线性组合起来得到最终的集成的分类器模型:
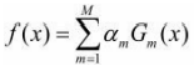
因此最终的分类器为:

案例:
例8.1 给定如表8.1所示训练数据。假设弱分类器由x<v或x>v产生,其阈值v使该分 类器在训练数据集上分类误差率最低。试用AdaBoost算法学习一个强分类器。

解:
(1)初始化权值分布
W1 = 1/10 = 0.1

(2)第一轮,对m=1
1、在权值分布为D1的训练数据上,阈值v取2.5时分类误差率最低,故基本分类器 为:
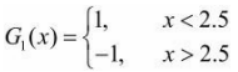
G1(x)在训练数据集上的误差率
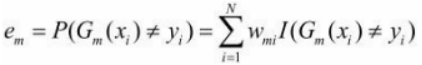
![]()
2、计算G1(x)的系数:

3、更新训练数据Xi的权值分布:

分类器sign[f 1(x)]在训练数据集上有3个误分类点。
(3)对于第二轮m=2:
1、在权值分布为D2的训练数据上,阈值v是8.5时分类误差率最低,基本分类器为

2、G2(x)在训练数据集上的误差率e2=0.2143。
3、计算a2=0.6496。
4、更新训练数据权值分布:

分类器sign[f 2(x)]在训练数据集上有3个误分类点。
(4)对于第三轮m=3:
1、在权值分布为D3的训练数据上,阈值v是5.5时分类误差率最低,基本分类器为

2、G3(x)在训练样本集上的误差率e3=0.1820。
3、计算a3=0.7514。
4、更新训练数据的权值分布:
![]()
于是得到:
![]()
分类器sign[f 3(x)]在训练数据集上误分类点个数为0。
(5)于是最终分类器为:
![]()