机器学习的学习过程基于概率和统计学,学习到的知识能用于其它数据的一个基本假设是独立同分布(IID),因此把数据变成同分布是很有必要的。
A.权重归一化: WN
不归一化特征,而是归一化权重。
B.特征归一化: BN、LN、IN、GN、SN
归一化操作
BN、LN、IN、GN这一系列方法的作用可以表示为:
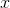
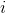
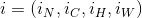
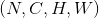
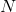
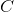
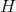
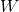
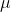
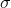
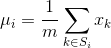
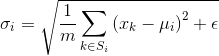

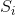
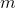
实现区别
四种特征归一化实现方法的区别在于
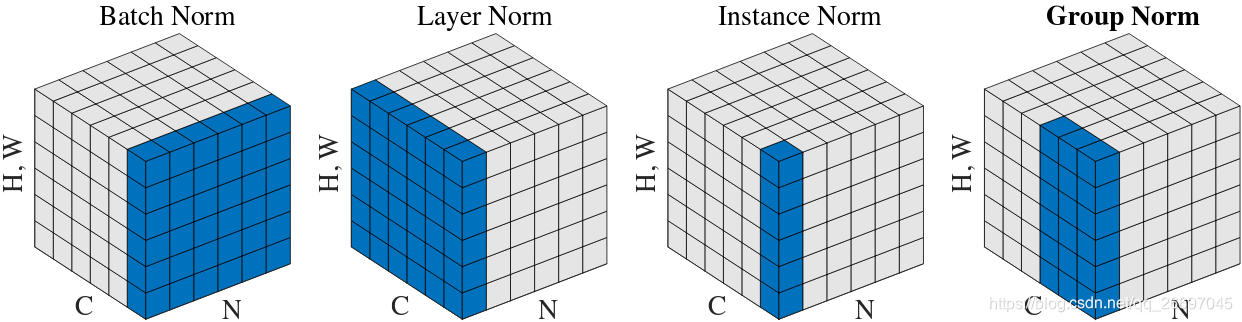
- BN中
:
坐标相同的像素在一块归一化。
- LN中
:
坐标相同的像素在一块归一化。
- IN中
:
- GN中
:
组,组内的像素在一块归一化。组数
是一个预定义的超参数。
是每组的通道数。
代表向下取整。图1最右的图中
,
,
在
中取值时
的值为
,
同理,因此把
坐标相同的像素分为2(
)组,每组的通道数是3(
)。
如公式(1),BN、LN、IN学习各通道的线性变换以补偿表征能力的可能损失: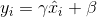
作用区别
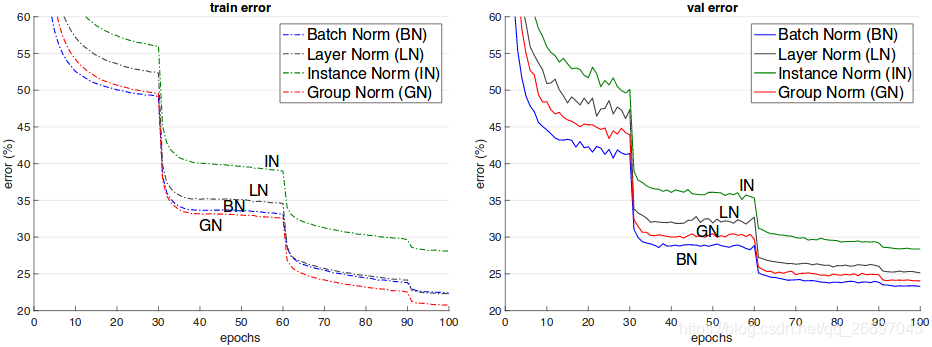
BN
BN是唯一依赖batch size的归一化方法,在batch size较小时误差急剧增大。由于内存限制,检测、分割、视频识别这类任务的batch size一般都较小,所以BN就不合适。
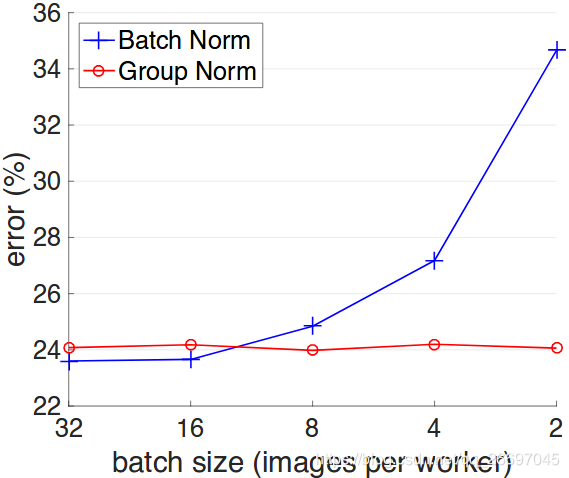
GN
GN是LN和IN的复合,性能优于LN和IN。如图2,GN对batch size不敏感,因此可以用于batch size较小的情况。
SN
虽然LN、IN对batch size不敏感,但其归一化能力较弱,当batch size较大时不如BN。因此SN组合LN、IN、BN,让网络学习权重参数以自动选择归一化方法:batch size越小,SN中BN的权重系数越小,IN和LN的权重系数越大;batch size越大,SN中BN的权重系数越大,IN和LN的权重系数越小。