from: https://www.cnblogs.com/skyfsm/p/8453498.html
https://www.cnblogs.com/skyfsm/p/8456968.html
BN是由Google于2015年提出,这是一个深度神经网络训练的技巧,它不仅可以加快了模型的收敛速度,而且更重要的是在一定程度缓解了深层网络中“梯度弥散”的问题,从而使得训练深层网络模型更加容易和稳定。所以目前BN已经成为几乎所有卷积神经网络的标配技巧了。
从字面意思看来Batch Normalization(简称BN)就是对每一批数据进行归一化,确实如此,对于训练中某一个batch的数据{x1,x2,...,xn},注意这个数据是可以输入也可以是网络中间的某一层输出。在BN出现之前,我们的归一化操作一般都在数据输入层,对输入的数据进行求均值以及求方差做归一化,但是BN的出现打破了这一个规定,我们可以在网络中任意一层进行归一化处理,因为我们现在所用的优化方法大多都是min-batch SGD,所以我们的归一化操作就成为Batch Normalization。
我们为什么需要BN?
我们知道网络一旦train起来,那么参数就要发生更新,除了输入层的数据外(因为输入层数据,我们已经人为的为每个样本归一化),后面网络每一层的输入数据分布是一直在发生变化的,因为在训练的时候,前面层训练参数的更新将导致后面层输入数据分布的变化。以网络第二层为例:网络的第二层输入,是由第一层的参数和input计算得到的,而第一层的参数在整个训练过程中一直在变化,因此必然会引起后面每一层输入数据分布的改变。我们把网络中间层在训练过程中,数据分布的改变称之为:“Internal Covariate Shift”。BN的提出,就是要解决在训练过程中,中间层数据分布发生改变的情况。
BN怎么做?

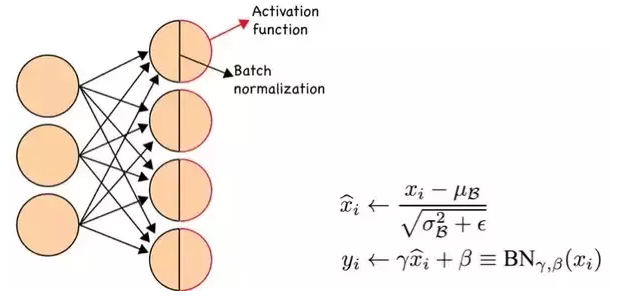
如上图所示,BN步骤主要分为4步:
- 求每一个训练批次数据的均值
- 求每一个训练批次数据的方差
- 使用求得的均值和方差对该批次的训练数据做归一化,获得0-1分布。其中εε是为了避免除数为0时所使用的微小正数。
- 尺度变换和偏移:将xixi乘以γγ调整数值大小,再加上ββ增加偏移后得到yiyi,这里的γγ是尺度因子,ββ是平移因子。这一步是BN的精髓,由于归一化后的xixi基本会被限制在正态分布下,使得网络的表达能力下降。为解决该问题,我们引入两个新的参数:γγ,ββ。 γγ和ββ是在训练时网络自己学习得到的。
BN到底解决了什么?
一个标准的归一化步骤就是减均值除方差,那这种归一化操作有什么作用呢?我们观察下图,
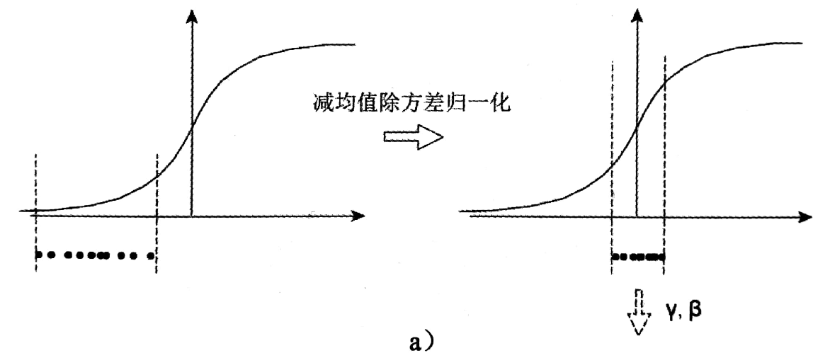

a中左图是没有经过任何处理的输入数据,曲线是sigmoid函数,如果数据在梯度很小的区域,那么学习率就会很慢甚至陷入长时间的停滞。减均值除方差后,数据就被移到中心区域如右图所示,对于大多数激活函数而言,这个区域的梯度都是最大的或者是有梯度的(比如ReLU),这可以看做是一种对抗梯度消失的有效手段。对于一层如此,如果对于每一层数据都那么做的话,数据的分布总是在随着变化敏感的区域,相当于不用考虑数据分布变化了,这样训练起来更有效率。

那么为什么要有第4步,不是仅使用减均值除方差操作就能获得目的效果吗?我们思考一个问题,减均值除方差得到的分布是正态分布,我们能否认为正态分布就是最好或最能体现我们训练样本的特征分布呢?不能,比如数据本身就很不对称,或者激活函数未必是对方差为1的数据最好的效果,比如Sigmoid激活函数,在-1~1之间的梯度变化不大,那么非线性变换的作用就不能很好的体现,换言之就是,减均值除方差操作后可能会削弱网络的性能!针对该情况,在前面三步之后加入第4步完成真正的batch normalization。
BN的本质就是利用优化变一下方差大小和均值位置,使得新的分布更切合数据的真实分布,保证模型的非线性表达能力。BN的极端的情况就是这两个参数等于mini-batch的均值和方差,那么经过batch normalization之后的数据和输入完全一样,当然一般的情况是不同的。
预测时均值和方差怎么求?
在训练时,我们会对同一批的数据的均值和方差进行求解,进而进行归一化操作。但是对于预测时我们的均值和方差怎么求呢?比如我们预测单个样本时,那还怎么求均值和方法呀!其实是这种样子的,对于预测阶段时所使用的均值和方差,其实也是来源于训练集。比如我们在模型训练时我们就记录下每个batch下的均值和方差,待训练完毕后,我们求整个训练样本的均值和方差期望值,作为我们进行预测时进行BN的的均值和方差:

最后测试阶段,BN的使用公式就是:
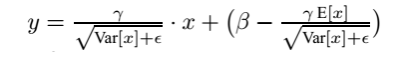
关于BN的使用位置,在CNN中一般应作用与非线性激活函数之前,s型函数s(x)的自变量x是经过BN处理后的结果。因此前向传导的计算公式就应该是:

其实因为偏置参数b经过BN层后其实是没有用的,最后也会被均值归一化,当然BN层后面还有个β参数作为偏置项,所以b这个参数就可以不用了。因此最后把BN层+激活函数层就变成了:

CNN中的BN
注意前面写的都是对于一般情况,对于卷积神经网络有些许不同。因为卷积神经网络的特征是对应到一整张特征响应图上的,所以做BN时也应以响应图为单位而不是按照各个维度。比如在某一层,batch大小为m,响应图大小为w×h,则做BN的数据量为m×w×h。
BN在深层神经网络的作用非常明显:若神经网络训练时遇到收敛速度较慢,或者“梯度爆炸”等无法训练的情况发生时都可以尝试用BN来解决。同时,常规使用情况下同样可以加入BN来加速模型训练,甚至提升模型精度。
在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况。正则化是机器学习中通过显式的控制模型复杂度来避免模型过拟合、确保泛化能力的一种有效方式。如果将模型原始的假设空间比作“天空”,那么天空飞翔的“鸟”就是模型可能收敛到的一个个最优解。在施加了模型正则化后,就好比将原假设空间(“天空”)缩小到一定的空间范围(“笼子”),这样一来,可能得到的最优解能搜索的假设空间也变得相对有限。有限空间自然对应复杂度不太高的模型,也自然对应了有限的模型表达能力。这就是“正则化有效防止模型过拟合的”一种直观解析。

L2正则化
在深度学习中,用的比较多的正则化技术是L2正则化,其形式是在原先的损失函数后边再加多一项:12λθ2i12λθi2,那加上L2正则项的损失函数就可以表示为:L(θ)=L(θ)+λ∑niθ2iL(θ)=L(θ)+λ∑inθi2,其中θθ就是网络层的待学习的参数,λλ则控制正则项的大小,较大的取值将较大程度约束模型复杂度,反之亦然。
L2约束通常对稀疏的有尖峰的权重向量施加大的惩罚,而偏好于均匀的参数。这样的效果是鼓励神经单元利用上层的所有输入,而不是部分输入。所以L2正则项加入之后,权重的绝对值大小就会整体倾向于减少,尤其不会出现特别大的值(比如噪声),即网络偏向于学习比较小的权重。所以L2正则化在深度学习中还有个名字叫做“权重衰减”(weight decay),也有一种理解这种衰减是对权值的一种惩罚,所以有些书里把L2正则化的这一项叫做惩罚项(penalty)。
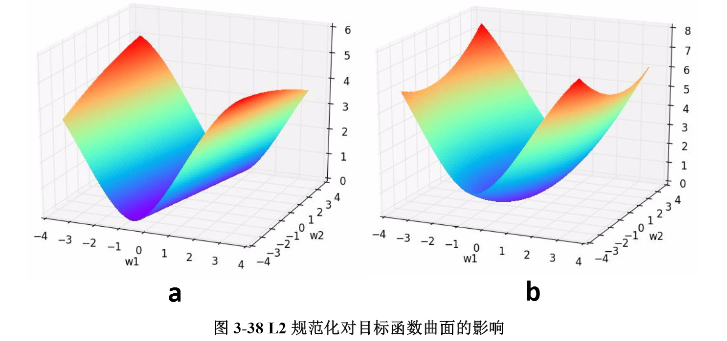
我们通过一个例子形象理解一下L2正则化的作用,考虑一个只有两个参数w1w1和w2w2的模型,其损失函数曲面如下图所示。从a可以看出,最小值所在是一条线,整个曲面看起来就像是一个山脊。那么这样的山脊曲面就会对应无数个参数组合,单纯使用梯度下降法难以得到确定解。但是这样的目标函数若加上一项0.1×(w21+w22)0.1×(w12+w22),则曲面就会变成b图的曲面,最小值所在的位置就会从一条山岭变成一个山谷了,此时我们搜索该目标函数的最小值就比先前容易了,所以L2正则化在机器学习中也叫做“岭回归”(ridge regression)。
L1正则化
L1正则化的形式是:λ|θi|λ|θi|,与目标函数结合后的形式就是:L(θ)=L(θ)+λ∑ni|θi|L(θ)=L(θ)+λ∑in|θi|。需注意,L1 正则化除了和L2正则化一样可以约束数量级外,L1正则化还能起到使参数更加稀疏的作用,稀疏化的结果使优化后的参数一部分为0,另一部分为非零实值。非零实值的那部分参数可起到选择重要参数或特征维度的作用,同时可起到去除噪声的效果。此外,L1正则化和L2正则化可以联合使用:λ1|θi|+12λ2θ2iλ1|θi|+12λ2θi2。这种形式也被称为“Elastic网络正则化”。
正则化对偏导的影响
对于L2正则化:C=C0+λ2n∑iω2iC=C0+λ2n∑iωi2,相比于未加正则化之前,权重的偏导多了一项λnωλnω,偏置的偏导没变化,那么在梯度下降时ωω的更新变为:
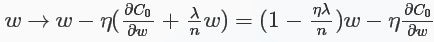
可以看出ωω的系数使得权重下降加速,因此L2正则也称weight decay(caffe中损失层的weight_decay参数与此有关)。对于随机梯度下降(对一个mini-batch中的所有x的偏导求平均):

对于L1正则化:C=C0+λn∑i|ωi|C=C0+λn∑i|ωi|,梯度下降的更新为:
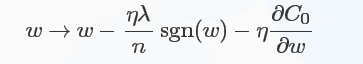
符号函数在ωω大于0时为1,小于0时为-1,在ω=0ω=0时|ω||ω|没有导数,因此可令sgn(0)=0,在0处不使用L1正则化。
L1相比于L2,有所不同:
- L1减少的是一个常量,L2减少的是权重的固定比例
- 孰快孰慢取决于权重本身的大小,权重刚大时可能L2快,较小时L1快
- L1使权重稀疏,L2使权重平滑,一句话总结就是:L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0
实践中L2正则化通常优于L1正则化。