"CapProNet: Deep Feature Learning via Orthogonal Projections onto Capsule Subspaces" 阅读笔记
原文链接: https://arxiv.org/abs/1805.07621v2
这篇论文利用了之前hinton大佬提出的capsule替换神经元的( 一个capsule可以简单的理解为一个向量 )概念,提出了一种利用capsule subspace来进行分类的网络结构,称为CapProNet。
接下来博主帮大家一点一点解析这篇论文的思想。
capsule简介
capsule是hinton大佬从大脑结构受到启发而提出的一种可以替换深度学习网络神经元的向量,目的是解决CNN的一些固有问题,比如CNN提取的特征都是经过多次池化,可能会丢失较多的空间信息等。
想要大致了解capsule以及capsulenet的原始架构可以看下图:
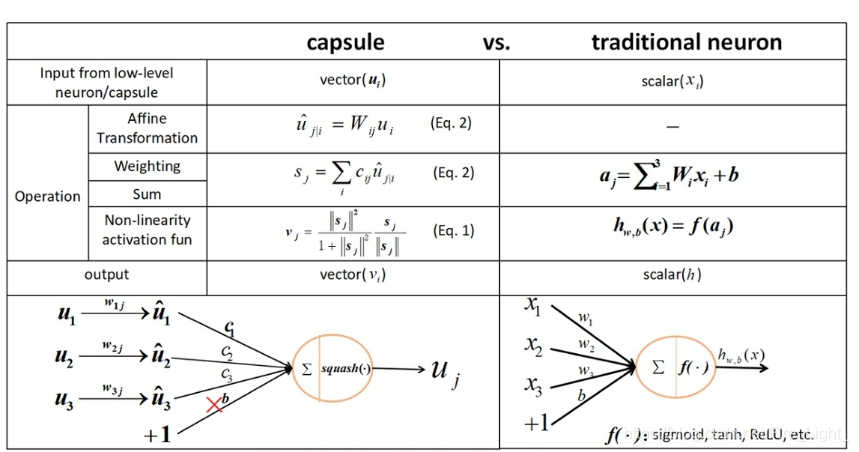
想要深入了解可以阅读原文:“Dynamic Routing Between Capsules”
其实,本文和上述的capsule之间的连接结构没有很大关系,而是借用了capsule的概念用来作为CNN的分类器,即将每个类别使用一个capsule subspace来表达,CNN学习到的特征向量会被正交投影到所有的subspace中,样本会被分类为投影之后向量的长度(模长)最大的那个类别。这样比起原来通过全连接层后进行Softmax分类,可以更充分的利用特征向量的信息。
capsule subspace
这里的capsule subspace指由一组capsule张成的线性空间,即假设 是多个capsule组成的矩阵,则capsule subspace
正交投影
假设原特征向量为x,通过一个投影矩阵P ,可以投影到子空间
中,且P满足
,则P为正交投影。
关于P的求解简单推导推荐看博客https://www.cnblogs.com/mfrbuaa/p/5319365.html ,里面写了低维的情况,高维其实类似。也就是说投影的结果是有闭式解的,假设投影后为
,则:
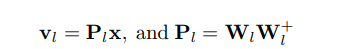
这里的
表示广义逆矩阵,当W的列向量相互独立时,
为:
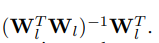
由于我们只关心
的长度,因此可以得到公式:
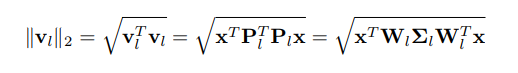
网络损失函数
最终样本属于每个类别的概率可以用Softmax来得到,因此网络采用Softmax交叉熵损失
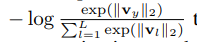
有了上述的算法,网络可以End to End的训练了。其中计算量比较大的地方在矩阵求逆,但是文中也依据一些快速求逆方法提出了一些近似算法用来加速这一过程,所有实用应该还是没有问题的。
实验结果
下表是在CIFAR10,CIFAR100,SVHN下的一个对比实验,在这些数据集上都能有一定的提高:

下表是在ImageNet验证集上的实验,同样也能提高网络的表现,这说明这一算法在分类任务上应该有一定的普适性。

可视化实验
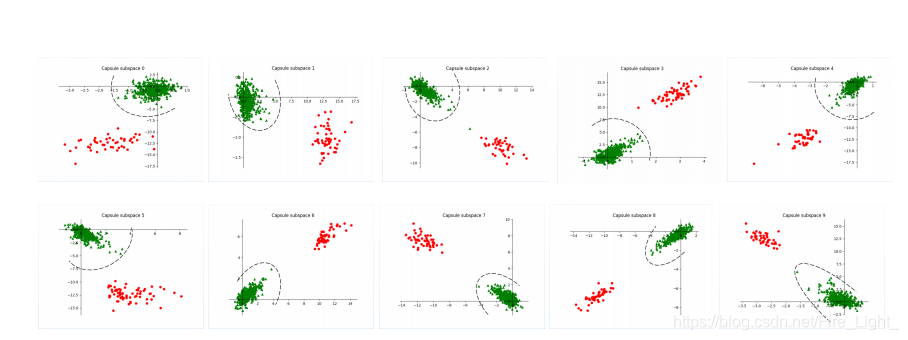
这个可视化实验是在CIFAR10上使用2D子空间,并且将一些样本投影到各个不同类别的子空间后画出的图。
图中一个坐标轴表示一个类别,红点为属于这个类别的样本,绿点为不属于这个类别的样本。
从图中可以看到,经过训练后的CapProNet可以有效的使得某类样本投影到该类子空间后获得更大的模值。