http://xxx.itp.ac.cn/abs/1612.00593
文章大意:
本文主要面向空间点集的分类及语义分割问题,下面的讨论与实现以语义分割为例进行介绍。下面是要解决的问题的示意图:
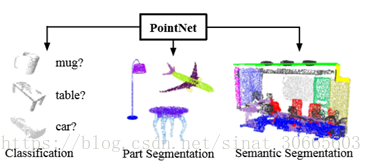
常见的2D语义分割问题一般的数据格式可能是语义边界——如Polygon Annotation(多边形(Polygon)实例分割论文阅读与实现),或如FCN等的pixel级别的数据,也分别对应关于“位置”的分类与关于“类别”的回归。
本文讨论3D语义分割。一个可以想到的问题是维度增高所带来的问题,从数据源的角度要找到一种Annotation使得网络能够消受得起,并能起到较好的估计效果。这两个问题是相应网络结构所要着重解决的。该文章所面向的数据格式是3D点云,相当于采取了类似pixel级别的处理。采取这种手段面向效果,数据的丰富性可以得到保证,但于此同时增大了对相应网络性能的担忧。
给定3D点云数据,这部分数据对应特征可以分成两部分——位置特征、“像素”特征。作者在解释自己提出的方法时与RNN的序列想法(RNN对permutation的依赖,位置permutation的复杂度)做了对比,指出了序列观点建模的不可行性。在这种问题中必须丢掉转而思考点集流形观点(在传统语义分割中有使用CRF的方法来做的——比如U-Net+CRF,可以说在这个数据场景下,可能不能用了)。
沿着这个思路就要将数据集进入模型的“序”消掉,所以出现了类似多实例(甚至在一些大尺度数据集下极度多实例)的抽象问题方式。——Pooling。(Adaptive pooling operators for weakly labeled sound event detection 论文阅读与实验)
面对多实例问题,难以使用RNN结构,或许是很多人考虑Pooling的一个原因。Pooling的两层含义在于聚合性及序的无关性。保证序的无关性的同时如何同时兼顾聚合效果(比如最基础的,解决多实例问题时适当选区特征窗口的窗宽以保证特征提取对于空间结构的有效性)。
从数学的角度,当我们将点集的语义分割作者给出了进行空间语义分割的问题同时也是解决方案的数学表示:

该定理的证明基本上就是通过点集连续函数连续性的(Cauchy)定义,构造关于闭区间的一个点集分割,利用这种分割构造出上述定理中待收敛的函数。数学分析中关于区间分割、寻找子列(基本上就是利用Cauchy列进行派生)的证明方法,基本上是数学分析中比较难的内容。
从上述定理中可以看到作者将使用MaxPoolling的可交换性解决上述问题。下面是PointNet的网络结构图:
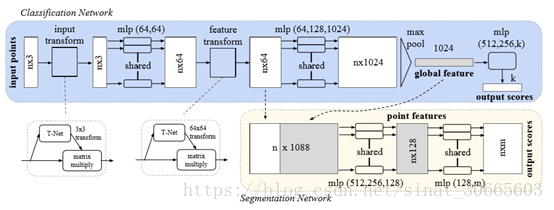
n代表一个点集输入的个数,segmentation中第一层网络完成local feature与global feature的fuse。网络结构简单清晰,图中没有详细展开的T-net为近似正交(通过正交损失逼迫正交)矩阵的生产网络,用于校准网络特征。(这里的MLP层除了最后一层都用Relu及BatchNormalization进行作用,在实测时如果不改激发、去掉BatchNormalization从量纲稳定角度不可取)
最后抽象成一个pixel级别的分类问题。(这个网络的关键点基本上是Pooling)
如果将上述网络结构概括为一个卷积,PointNet的卷积结构相当于固定尺度的(与点集本身的空间结构无关),这样会导致一个问题,比如文本中极度多标签的分类问题——见:http://nyc.lti.cs.cmu.edu/yiming/Publications/jliu-sigir17.pdf 中关于极度多标签分类的讨论,其解决方案是被动地改变卷积核的尺度(动态MaxPooling),这源于难以动态的捕获及调节语义层级的“窗宽”,对应到这个问题,这种位置上的特征实际上是一种“分词”,如果能够找到一种“分词方法”(相当于建立“语义坐标”)对于不同语义关系的token放入不同的卷积核中,或许是另一种解决这个问题的方法。
“坐标”作为特征描述的重要组成部分,在特征相对坐标分布不均匀的情况下,往往十分重要,这时将其相对关系纳入到具体结构显得很重要。
把这个问题投影到PointNet上来,也同时存在这个问题,当特征存在类似的关系时如何找到一种坐标抽象或者“聚合”方案是下面PointNet++解决的问题。
下面先给出网络示意图:
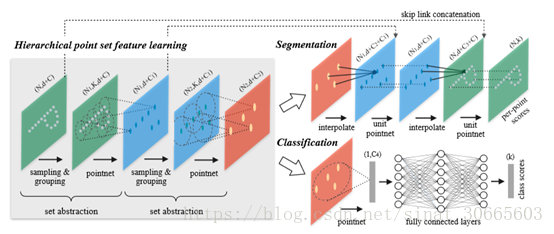
此网络结构的基本思想是在层次特征层对于点集特征进行关于质心的抽象,具体就是初始化若干质心(原文使用最远点进行均匀刻画),根据质心确定的cluster在cluster内使用类似PointNet中得到global feature的结构得到cluster的特征抽象,并迭代进行此过程;此过程又可以看作PointNet中得到的global feature的局部敏感(局部精确)描述(空间离散化)。之后的Segmentation过程相当于先通过上述特征的“插值”(与质心距离成反比)将这部分特征逐步global化,并伴随跳连的局部特征进行特征融合,进行更为精确的特征描述,并迭代进行此过程。
PointNet++在目标上是为了解决PointNet的多尺度Pooling问题,在手段上选取了global feature局部精确“离散化”插值的方式。
对于一些细节先给出部分论文截图及注释:

Sampling Layer选取FPS方式(NP难问题),在自实现(下面的实现)中用Kmeans++的初始点选择算法进行替换。
PointNet Layer基本参照上述PointNet T-net的结构给出,具体参数见实现。
PointNet Layer多尺度特征的融合有下面两种方式。(多个Pooling特征融合)

自实现是(a),可能有些人会说(b)有些像Stack
Segmentation的特征插值使用距离倒数加权:
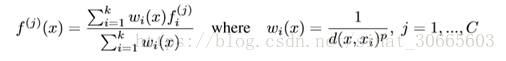
K elements cluster的选取使用KD-Tree,作者与KNN进行了对比,差别不算太大。
下面针对特定数据集给出实现:
数据集地址:http://semantic3d.net/view_dbase.php?chl=1#download
数据集简要说明:
选取的是两种数据集中比较大的那个,数据集的点量确实比较大。这从一方面方便了增强过程(可以直接用抽样代替增强)。同时给单个数据(一个3D点集文件)的数据分割带来一定挑战,实验证明不进行分割、直接抽样,效果不太好;进行分割但分割细密(关于x y各分成10份,生成100个grid),效果也不太好,分别对应多实例窗宽的两种情形,下面的实验是将x y各分成3份进行的。
本文的数据处理使用了https://github.com/daavoo/pyntcloud 要进行安装,不建议用matplotlib (相应原因可以在生成PyntCloud对象调用plot选取backend为matplotlib窥得。)
从网站下取数据集,并进行label与点云特征合并(去掉未标注点)如下:
def join_source_lable_file(source = r"E:\Temp\bildstein_station1_xyz_intensity_rgb\bildstein_station1_xyz_intensity_rgb.txt",
label = r"E:\Temp\sem8_labels_training\bildstein_station1_xyz_intensity_rgb.labels",
sample_rate = 1):
header_str = \
'''ply
format ascii 1.0
element vertex 0
property float x
property float y
property float z
property float intensity
property uchar diffuse_red
property uchar diffuse_green
property uchar diffuse_blue
property uchar label
end_header\n'''
req_file_path = label.split("\\")[-1].replace(".labels", "_{}.ply")
req_file_list = list(map(lambda idx: open(req_file_path.format(idx), "w"), range(sample_rate)))
for i in range(sample_rate):
req_file_list[i].write(header_str)
i = 0
with open(label, "r") as l:
with open(source, "r") as f:
while True:
l_line = l.readline()
if not l_line:
break
if l_line != "0 \n":
idx = i % sample_rate
req_file_list[idx].write("{} {}\n".format(f.readline().strip(), l_line.strip()))
if i % int(1e6) == 0:
print("i {}".format(i))
i += 1
for i in range(sample_rate):
req_file_list[i].close()
print("all write end")
return req_file_path
def join_train_files():
source_target_list = [
{"source": r"E:\Temp\bildstein_station1_xyz_intensity_rgb\bildstein_station1_xyz_intensity_rgb.txt",
"target": r"E:\Temp\sem8_labels_training\bildstein_station1_xyz_intensity_rgb.labels",
"sample_rate": 1,},
{"source": r"E:\Temp\bildstein_station3_xyz_intensity_rgb\bildstein_station3_xyz_intensity_rgb.txt",
"target": r"E:\Temp\sem8_labels_training\bildstein_station3_xyz_intensity_rgb.labels",
"sample_rate": 1,},
{"source": r"E:\Temp\bildstein_station5_xyz_intensity_rgb\bildstein_station5_xyz_intensity_rgb.txt",
"target": r"E:\Temp\sem8_labels_training\bildstein_station5_xyz_intensity_rgb.labels",
"sample_rate": 1,},
{"source": r"E:\Temp\domfountain_station1_xyz_intensity_rgb\domfountain_station1_xyz_intensity_rgb.txt",
"target": r"E:\Temp\sem8_labels_training\domfountain_station1_xyz_intensity_rgb.labels",
"sample_rate": 1,},
{"source": r"E:\Temp\domfountain_station2_xyz_intensity_rgb\domfountain_station2_xyz_intensity_rgb.txt",
"target": r"E:\Temp\sem8_labels_training\domfountain_station2_xyz_intensity_rgb.labels",
"sample_rate": 1,},
{"source": r"E:\Temp\domfountain_station3_xyz_intensity_rgb\domfountain_station3_xyz_intensity_rgb.txt",
"target": r"E:\Temp\sem8_labels_training\domfountain_station3_xyz_intensity_rgb.labels",
"sample_rate": 1,},
{
"source": r"E:\Temp\sg27_station1_intensity_rgb\sg27_station1_intensity_rgb.txt",
"target": r"E:\Temp\sem8_labels_training\sg27_station1_intensity_rgb.labels",
"sample_rate": 4 * 9,
},
{
"source": r"E:\Temp\sg27_station2_intensity_rgb\sg27_station2_intensity_rgb.txt",
"target": r"E:\Temp\sem8_labels_training\sg27_station2_intensity_rgb.labels",
"sample_rate": 6 * 9,
},
{
"source": r"E:\Temp\sg27_station4_intensity_rgb\sg27_station4_intensity_rgb.txt",
"target": r"E:\Temp\sem8_labels_training\sg27_station4_intensity_rgb.labels",
"sample_rate": 3 * 9,
},
{
"source": r"E:\Temp\sg27_station9_intensity_rgb\sg27_station9_intensity_rgb.txt",
"target": r"E:\Temp\sem8_labels_training\sg27_station9_intensity_rgb.labels",
"sample_rate": 3 * 9,
},
]
req_source_list = []
for inner_dict in source_target_list:
source, target, sample_rate = inner_dict["source"], inner_dict["target"], inner_dict["sample_rate"]
req_source_list.append(join_source_lable_file(source, target, sample_rate))
return req_source_list
def join_valid_files():
source_target_list = [
{
"source": r"E:\Temp\sg27_station5_intensity_rgb\sg27_station5_intensity_rgb.txt",
"target": r"E:\Temp\sem8_labels_training\sg27_station5_intensity_rgb.labels",
"sample_rate": 2 * 9,
},
]
req_source_list = []
for inner_dict in source_target_list:
source, target = inner_dict["source"], inner_dict["target"]
req_source_list.append(join_source_lable_file(source, target))
return req_source_list
if __name__ == "__main__":
join_train_files()
join_valid_files()
pass
采取n = 1024 * 4的设定,直接生成pkl文件待快速抽样调用:(包含数据集导出过程)
(BoundingBoxFilter调用compute方法可能显示poinss对象未初始化,只要构造函数调用extract_info方法即可, valid_xx_part_second进行数据平衡性筛选)
from pyntcloud import PyntCloud
from pyntcloud.filters import BoundingBoxFilter
import numpy as np
import gc
import glob
import pickle
from sklearn.model_selection import train_test_split
from random import choice
# use single stats to produce 3d split stats
def single_stats(file_path = r"C:\Coding\Python\pyntcloud_test\pyntcloud_dataloader\sg27_station1_intensity_rgb.ply"
,grid_num = 10, filter_num = 1024 * 8):
point_file = PyntCloud.from_file(file_path)
xy_array = point_file.points[["x", "y"]].values
x_max, y_max = np.max(xy_array, axis=0)
x_min, y_min = np.min(xy_array, axis=0)
del xy_array
gc.collect()
req_xy_t4_list = []
x_grid = np.linspace(x_min, x_max, grid_num)
y_grid = np.linspace(y_min, y_max, grid_num)
points_num_array = np.zeros(shape=[len(x_grid) - 1, len(y_grid) - 1])
for i in range(len(x_grid) - 1):
for j in range(len(y_grid) - 1):
xmin, xmax = x_grid[i], x_grid[i + 1]
ymin, ymax = y_grid[j], y_grid[j + 1]
compute_mask = BoundingBoxFilter(pyntcloud = point_file,
min_x=xmin, max_x=xmax, min_y=ymin,
max_y=ymax, ).compute()
points_num_array[i][j] = np.sum(compute_mask.astype(np.int32))
if points_num_array[i][j] > filter_num:
req_xy_t4_list.append((xmin, xmax, ymin, ymax))
print("points_num_array :")
print(points_num_array)
return (point_file ,req_xy_t4_list)
def single_df_gen(point_file, req_xy_t4_list, ply_file):
#points_df = PyntCloud.from_file(ply_file).points
points_df = point_file.points
total_X, total_y = points_df[["x", "y", "z", "intensity", "diffuse_red", "diffuse_green", "diffuse_blue"]].values, points_df["label"].values
pkl_path_format = ply_file.replace(".ply", "{}_.pkl")
for idx ,t4 in enumerate(req_xy_t4_list):
x_min, x_max, y_min, y_max = t4
x_part_first, xx_part_first = total_X[np.where(total_X[:, 0] >= x_min)], total_y[np.where(total_X[:, 0] >= x_min)]
x_part_second, xx_part_second = x_part_first[np.where(x_part_first[:, 0] < x_max)], xx_part_first[np.where(x_part_first[:, 0] < x_max)]
y_part_first, yy_part_first = x_part_second[np.where(x_part_second[:, 1] >= y_min)], xx_part_second[np.where(x_part_second[:, 1] >= y_min)],
y_part_second, yy_part_second = y_part_first[np.where(y_part_first[:, 1] < y_max)], yy_part_first[np.where(y_part_first[:, 1] < y_max)]
print(y_part_second.shape, yy_part_second.shape)
with open(pkl_path_format.format(idx), "wb") as f:
pickle.dump((y_part_second, yy_part_second), f)
del total_y, total_X, points_df
gc.collect()
def serlize_pd_df(ply_dir):
ply_file_list = glob.glob(ply_dir + "\\" + "*.ply")
for ply_file in ply_file_list:
point_file ,req_xy_t4_list = single_stats(ply_file)
single_df_gen(point_file, req_xy_t4_list, ply_file)
print("{} pkl end".format(ply_file))
def data_loader(pkl_dir, batch_size = 4, n = 1024 * 8, centered = False):
files = list(glob.glob(pkl_dir + "\\" + "*.pkl"))
def valid_xx_part_second(xx_part_second, min_categories = 2, ratio = 0.5):
categories, category_num = np.unique(xx_part_second, return_counts=True)
if len(categories) >= min_categories:
sort_list = sorted(category_num.tolist())
if sort_list[-2] > sort_list[-1] * ratio:
return True
return False
# not yield above max_times
def single_gen(file, max_times = 10):
with open(file, "rb") as f:
x_part_second, xx_part_second = pickle.load(f)
if valid_xx_part_second(xx_part_second):
if centered:
x_part_second[:, 0] = (x_part_second[:, 0] - x_part_second[:, 0].min()) / (x_part_second[:, 0].max() - x_part_second[:, 0].min())
x_part_second[:, 1] = (x_part_second[:, 1] - x_part_second[:, 1].min()) / (x_part_second[:, 1].max() - x_part_second[:, 1].min())
times = int(len(x_part_second) / n)
for i in range(min(times, max_times)):
input_cloud_points, _, targets, _ = train_test_split(x_part_second, xx_part_second, train_size=n, shuffle=True)
yield (input_cloud_points, targets)
batch_input_cloud_points = np.zeros(shape=[batch_size, n, 7], dtype=np.float32)
batch_targets = np.zeros(shape=[batch_size, n], dtype=np.int32)
start_idx = 0
while True:
file = choice(files)
for input_cloud_points, targets in single_gen(file):
batch_input_cloud_points[start_idx] = input_cloud_points
batch_targets[start_idx] = targets
start_idx += 1
if start_idx == batch_size:
# random sample points yield without shuffle
yield (batch_input_cloud_points, batch_targets - 1)
batch_input_cloud_points = np.zeros(shape=[batch_size, n, 7], dtype=np.float32)
batch_targets = np.zeros(shape=[batch_size, n], dtype=np.int32)
start_idx = 0
train_dir = r"C:\Coding\Python\train_split_dir"
valid_dir = r"C:\Coding\Python\valid_split_dir"
if __name__ == "__main__":
serlize_pd_df(train_dir)
serlize_pd_df(valid_dir)
pass
下面先给出模型构建部分,由于多次使用MLP故用sonnet进行简单MLP构建与调用。
为了在MLP中间层嵌入Batchnormalization,把二者融合如下:
import tensorflow as tf
def batch_normal_with_relu(inputs, name = None):
with tf.variable_scope("batch_normal_with_relu_{}".format(name)):
fc_mean, fc_var = tf.nn.moments(
inputs,
axes=[0],
)
out_size = int(inputs.get_shape()[-1])
scale = tf.Variable(tf.ones([out_size]))
shift = tf.Variable(tf.zeros([out_size]))
epsilon = 0.001
outputs = tf.nn.relu(tf.nn.batch_normalization(inputs, fc_mean, fc_var, shift, scale, epsilon))
return outputs
if __name__ == "__main__":
pass
这样就可以如下得到PointNet结构:
import tensorflow as tf
from sonnet.python.modules.nets import mlp
from sonnet.python.modules import basic
from model.model_utils import batch_normal_with_relu
from functools import partial
from sklearn.metrics import f1_score
from data_preprocess.sample_dataset_generator import train_dir, valid_dir, data_loader
import keras.backend as K
sess = tf.Session()
K.set_session(sess)
class PointNet(object):
def __init__(self, n = 100, m = 20, batch_size = 4, reg_val = 0.001):
# n indicate points num, m indicate segmentation label num
self.input_cloud_points = tf.placeholder(tf.float32, [None, n, 7])
# max target val m - 1
self.target = tf.placeholder(tf.int32, [None, n])
self.n = n
self.m = m
self.batch_size = batch_size
self.reg_val = reg_val
self.model_construct()
self.opt_construct()
def T_net_layer(self, input, name = None):
matrix_dim = int(input.get_shape()[-1])
assert matrix_dim in [7, 64]
batch_normalization_1 = partial(batch_normal_with_relu, name = "t_net_mlp_layer_first")
t_net_mlp_layer_first = mlp.MLP([64, 128, 1024], name = "t_net_mlp_{}_first".format(name),
activation=batch_normalization_1)
t_net_mlp_output_first = basic.BatchApply(t_net_mlp_layer_first)(input)
max_pool_output = tf.reshape(tf.layers.max_pooling1d(inputs=t_net_mlp_output_first, pool_size=self.n, strides=1,
name="t_net_maxpool_f"), [-1, 1024])
batch_normalization_2 = partial(batch_normal_with_relu, name = "t_net_mlp_layer_second")
t_net_mlp_layer_second = mlp.MLP([512, 256, matrix_dim * matrix_dim], name = "t_net_mlp_{}_second".format(name),
activation=batch_normalization_2)
t_net_mlp_output_second = t_net_mlp_layer_second(max_pool_output)
# matrix various with single input sample
batch_output_matrix = tf.reshape(t_net_mlp_output_second, [-1, matrix_dim, matrix_dim])
def mul_input_matrix(fuse_input):
return tf.matmul(tf.reshape(fuse_input[:-1 * matrix_dim * matrix_dim], [1, matrix_dim]), tf.reshape(fuse_input[-1 * matrix_dim * matrix_dim:], [matrix_dim, matrix_dim]))
transformed_input = tf.map_fn(mul_input_matrix, tf.concat([tf.reshape(input, [-1, matrix_dim]), tf.tile(tf.reshape(batch_output_matrix, [-1, matrix_dim * matrix_dim])[:self.batch_size, ...], [self.n, 1])], axis=-1))
transformed_input_reshape = tf.reshape(transformed_input, [-1, self.n, matrix_dim])
return transformed_input_reshape, batch_output_matrix
def compute_orthogonal_loss(self, batch_transform_matrix):
def produce_inner_prod_m(matrix):
return tf.matmul(tf.transpose(matrix, [1, 0]), matrix)
# batch_transform_matrix [batch, matrix_dim, matrix_dim]
matrix_dim = int(batch_transform_matrix.get_shape()[-1])
left_hand = batch_transform_matrix[:self.batch_size, ...]
left_hand = tf.map_fn(produce_inner_prod_m, left_hand)
right_hand = tf.tile(tf.expand_dims(tf.eye(num_rows=matrix_dim), 0), [self.batch_size, 1, 1])
return tf.nn.l2_loss(left_hand - right_hand)
def model_construct(self):
transformed_input, self.batch_transform_matrix_first = self.T_net_layer(self.input_cloud_points, name="T_net_0")
batch_normalization_3 = partial(batch_normal_with_relu, name = "mlp_layer_first")
mlp_layer_first = mlp.MLP([64, 64], name = "mlp_layer_first", activation=batch_normalization_3)
mlp_layer_first_output = basic.BatchApply(mlp_layer_first)(transformed_input)
# [batch, n, 64]
transformed_feature, self.batch_transform_matrix_second = self.T_net_layer(mlp_layer_first_output, name="T_net_1")
batch_normalization_4 = partial(batch_normal_with_relu, name = "mlp_layer_second")
mlp_layer_second = mlp.MLP([64, 128, 1024], name = "mlp_layer_second", activation=batch_normalization_4)
mlp_layer_second_output = basic.BatchApply(mlp_layer_second)(transformed_feature)
# [batch, 1, 1024]
max_pool_output = tf.reshape(tf.layers.max_pooling1d(inputs=mlp_layer_second_output, pool_size=self.n, strides=1,
name="t_net_maxpool_s"), [-1, 1, 1024])
concat_feature = tf.concat([transformed_feature, tf.tile(max_pool_output, [1, self.n, 1])], axis=-1)
batch_normalization_5 = partial(batch_normal_with_relu, name = "mlp_layer_third")
mlp_layer_third = mlp.MLP([512, 256, 128], name = "mlp_layer_third", activation=batch_normalization_5)
self.point_features = basic.BatchApply(mlp_layer_third)(concat_feature)
batch_normalization_6 = partial(batch_normal_with_relu, name = "mlp_layer_fourth")
mlp_layer_fourth = mlp.MLP([128, self.m], name = "mlp_layer_fourth", activation=batch_normalization_6)
self.output_scores = basic.BatchApply(mlp_layer_fourth)(self.point_features)
def opt_construct(self):
self.first_orthogonal_loss = self.compute_orthogonal_loss(self.batch_transform_matrix_first)
self.second_orthogonal_loss = self.compute_orthogonal_loss(self.batch_transform_matrix_second)
labels = tf.one_hot(self.target, depth=self.m)
logits = self.output_scores
self.logits = logits
self.segmentation_loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels = labels,
logits = logits))
self.total_loss = self.segmentation_loss + self.reg_val * (self.first_orthogonal_loss + self.second_orthogonal_loss)
self.prediction = tf.argmax(tf.nn.softmax(logits, axis=-1), axis=-1)
self.accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.cast(self.prediction, tf.int32), self.target), tf.float32))
self.train_op = tf.train.AdamOptimizer(0.001).minimize(self.total_loss)
@staticmethod
def train(input_sess):
import os
import numpy as np
from uuid import uuid1
from copy import deepcopy
header_str = \
'''ply
format ascii 1.0
element vertex 0
property float x
property float y
property float z
property float intensity
property uchar diffuse_red
property uchar diffuse_green
property uchar diffuse_blue
property uchar pred_labels
property uchar true_labels
end_header\n'''
def centered_xy(cloud_points):
input_cloud_points = deepcopy(cloud_points)
input_cloud_points_list = [ele for ele in input_cloud_points]
def process_single(x_part_second):
x_part_second[:, 0] = (x_part_second[:, 0] - x_part_second[:, 0].min()) / (x_part_second[:, 0].max() - x_part_second[:, 0].min())
x_part_second[:, 1] = (x_part_second[:, 1] - x_part_second[:, 1].min()) / (x_part_second[:, 1].max() - x_part_second[:, 1].min())
return x_part_second
return np.asarray(list(map(process_single, input_cloud_points_list)), np.float32)
def serlize_points_and_label(input_cloud_points, pred_labels, true_labels, epoch):
if not os.path.exists(r"C:\Coding\Python\conclusion_{}".format(epoch)):
os.mkdir(r"C:\Coding\Python\conclusion_{}".format(epoch))
input_cloud_points, pred_labels, true_labels = input_cloud_points[0], pred_labels[0], true_labels[0]
concat_ndarray = np.concatenate([input_cloud_points, pred_labels.reshape([len(pred_labels), 1]), true_labels.reshape([len(true_labels), 1])],
axis=-1)
tail_str = "\n".join([" ".join(str(inner_ele) for inner_ele in line_array) for line_array in concat_ndarray])
full_str = header_str + tail_str
with open(r"C:\Coding\Python\conclusion_{}\{}.ply".format(epoch ,uuid1()), "w") as f:
f.write(full_str)
batch_size = 4
n = 1024 * 8
m = 8
train_gen = data_loader(train_dir, batch_size=batch_size)
valid_gen = data_loader(valid_dir, batch_size=batch_size)
model_ext = PointNet(batch_size=batch_size, n = n, m = m)
step = 0
save_epoch = 3
saver = tf.train.Saver()
with input_sess as sess:
if os.path.exists(r"C:\Coding\Python\PointNet\pm_{}.meta".format(save_epoch)):
saver.restore(sess ,r"C:\Coding\Python\PointNet\pm_{}".format(save_epoch))
print("load exist")
else:
sess.run(tf.global_variables_initializer())
print("init_new")
while True:
step += 1
train_data = train_gen.__next__()
if step % 100 == 0:
print("train data consume end !")
saver.save(sess, r"C:\Coding\Python\PointNet\pm_{}".format(save_epoch))
save_epoch += 1
step = 0
input_cloud_points, targets = train_data
_, train_loss, train_acc, train_pred, train_logits = sess.run([model_ext.train_op, model_ext.total_loss, model_ext.accuracy, model_ext.prediction,
model_ext.logits],
feed_dict={
model_ext.input_cloud_points: centered_xy(input_cloud_points),
model_ext.target: targets
})
if step % 1 == 0:
train_targets = targets.reshape([-1])
train_pred = train_pred.reshape([-1])
valid_data = valid_gen.__next__()
input_cloud_points, targets = valid_data
valid_loss, valid_acc, valid_pred = sess.run([model_ext.total_loss, model_ext.accuracy, model_ext.prediction],
feed_dict={
model_ext.input_cloud_points: centered_xy(input_cloud_points),
model_ext.target: targets
})
serlize_points_and_label(input_cloud_points, valid_pred * 32, targets * 32, save_epoch)
valid_targets = targets.reshape([-1])
valid_pred = valid_pred.reshape([-1])
print("epoch : {} step : {} train_loss : {:.2f} train_acc : {:.2f} valid_loss : {:.2f} valid_acc : {:.2f} train_f1 : {:.2f} valid_f1 : {:.2f}".format(save_epoch, step, train_loss, train_acc, valid_loss, valid_acc,
f1_score(train_targets, train_pred, average="macro"), f1_score(valid_targets, valid_pred, average="macro")))
if __name__ == "__main__":
PointNet.train(sess)
这里没有用到keras,感兴趣的同学可以用AutoPooling的keras替换MaxPooling试一试看看效果。
下面给出PointNet++所需要的scipy函数
import random
import numpy as np
from scipy.spatial import KDTree
from functools import reduce
from sklearn.cluster.k_means_ import _init_centroids
def distance(p0, p1):
p0, p1 = map(np.array, [p0, p1])
return ((p0 - p1) ** 2).mean()
# input points and output solution_set are all list type
def incremental_farthest_search(points, k):
#start_time = time()
points = points.tolist()
remaining_points = points[:]
solution_set = []
solution_set.append(remaining_points.pop( \
random.randint(0, len(remaining_points) - 1)))
for _ in range(k-1):
distances = [distance(p, solution_set[0]) for p in remaining_points]
for i, p in enumerate(remaining_points):
for j, s in enumerate(solution_set):
distances[i] = min(distances[i], distance(p, s))
solution_set.append(remaining_points.pop(distances.index(max(distances))))
#print("incremental_farthest_search time_consume: {}".format(time() - start_time))
return np.array(solution_set, dtype=np.float32)
def incremental_farthest_search_with_kmeans_pp_centroids(points, k):
#start_time = time()
solution_set = _init_centroids(points, k, init="k-means++")
#print("incremental_farthest_search time_consume: {}".format(time() - start_time))
return np.array(solution_set, dtype=np.float32)
def ball_tree_query_with_corr(points, centroid_points, K = 3):
kdTree = KDTree(points)
# return shape [len(centroid_points), K] the element constructed by indices.
#mean_distance = (np.sum((points[1:, ...] - points[:-1,...]) ** 2, axis=-1) ** 0.5).mean()
#return kdTree.query(centroid_points, k = K, distance_upper_bound=mean_distance * 10)
return kdTree.query(centroid_points, k = K, eps=0.0, distance_upper_bound=np.inf)
def prepare_process_before_PointNet_with_feature(points, features, centroid_points, K):
#start_time = time()
d = 3
# common not add zeros for Degree of freedom decrease and not contain information
# features [batch, c]
# point_coordinates [batch, 2] ball_tree_query_output [len(centroid_points), K]
# centroid_points [len(centroid_points), 2]
#temp_start = time()
ball_tree_query_corr, ball_tree_query_indexes = ball_tree_query_with_corr(points, centroid_points, K)
#print(ball_tree_query_corr.shape, ball_tree_query_indexes.shape)
#print("prepare_process_before_PointNet_with_feature ball_tree time_consume: {}".format(time() - temp_start))
flatten_indices = np.reshape(ball_tree_query_indexes, [-1]).tolist()
flatten_coordinate_array = np.asarray(reduce(lambda a, b : a + b, map(lambda index: points[int(index): int(index) + 1].tolist(), flatten_indices)))
# [len(centroid_points), K, d]
inner_points_coordinates = flatten_coordinate_array.reshape([-1 ,K, d])
#inner_points_coordinates = flatten_coordinate_array.reshape([len(centroid_points) ,-1, d])
# [len(centroid_points), K - 1, d]
normalized_points = inner_points_coordinates[:,1:,:] - inner_points_coordinates[:, 0:1, :]
# [len(centroid_points), K - 1, C]
req_features = features[ball_tree_query_indexes[:, 1:]]
#print("prepare_process_before_PointNet_with_feature time_consume: {}".format(time() - start_time))
# [len(centroid_points), K - 1, d + C]
return np.asarray(np.concatenate([normalized_points, req_features], axis=-1), dtype=np.float32)
def segmentation_precedure(points, features, centroid_points, K):
#start_time = time()
d = 3
#temp_start = time()
ball_tree_query_corr, ball_tree_query_indexes = ball_tree_query_with_corr(points, centroid_points, K)
#print("segmentation_precedure ball_tree time_consume: {}".format(time() - temp_start))
flatten_indices = np.reshape(ball_tree_query_indexes, [-1]).tolist()
flatten_coordinate_array = np.asarray(reduce(lambda a, b : a + b, map(lambda index: list(points[int(index): int(index) + 1]), flatten_indices)))
# [len(centroid_points), K, d]
inner_points_coordinates = flatten_coordinate_array.reshape([-1 ,K, d])
#inner_points_coordinates = flatten_coordinate_array.reshape([len(centroid_points) ,-1, d])
# [len(centroid_points), K]
distance_array = 1 / (np.sum((inner_points_coordinates - centroid_points[:, np.newaxis]) ** 2, axis=-1) + np.finfo(np.float32).eps)
# [len(centroid_points), K, C]
req_features = features[ball_tree_query_indexes]
weighted_features = req_features * distance_array[..., np.newaxis]
# [len(centroid_points), C]
weighted_features = np.sum(weighted_features / np.sum(weighted_features, axis=1)[:, np.newaxis], axis=1)
#print("segmentation_precedure time_consume: {}".format(time() - start_time))
return weighted_features
if __name__ == "__main__":
pass
使用tf.py_func就可以如下得到PointNet++的网络结构(真正考虑性能的相应实现是要用C++重写这部分Operation的)
import tensorflow as tf
from sonnet.python.modules.nets import mlp
from sonnet.python.modules import basic
from model.model_utils import batch_normal_with_relu
from functools import partial
from sklearn.metrics import f1_score
from model.model_utils_final_py import incremental_farthest_search, prepare_process_before_PointNet_with_feature, segmentation_precedure, \
incremental_farthest_search_with_kmeans_pp_centroids
from data_preprocess.sample_dataset_generator import train_dir, valid_dir, data_loader
import keras.backend as K
sess = tf.Session()
K.set_session(sess)
class PointNet_pp(object):
def __init__(self, n = 1024 * 8, m = 8, batch_size = 4,
N1 = 512 * 2, N2 = 256 * 2, K = 8, d = 3, C = 4, C1 = 16, C2 = 32, C3 = 64,
use_kpp_init = True):
# n indicate points num, m indicate segmentation label num
self.input_cloud_points = tf.placeholder(tf.float32, [None, n, d + C])
# max target val m - 1
self.target = tf.placeholder(tf.int32, [None, n])
self.n = n
self.m = m
self.batch_size = batch_size
self.N1 = N1
self.N2 = N2
self.K = K
self.d = d
self.C = C
self.C1 = C1
self.C2 = C2
self.C3 = C3
self.m = m
self.use_kpp_init = use_kpp_init
self.Hierarchical_point_set_feature_learning_layer()
self.Segmentation_layer()
self.opt_construct()
def sampling_grouping_layer(self, Ni, inputs):
# Ni in {N1, N2}
# inputs [batch, N, d + c]
def single_sampling_grouping_procedure(input):
d_plus_c = int(input.get_shape()[-1])
# [Ni, d] [Ni, c]
single_corrdinate_part, single_feature = input[..., :self.d], input[..., self.d:]
if self.use_kpp_init:
incremental_farthest_search_op = tf.py_func(incremental_farthest_search_with_kmeans_pp_centroids, [single_corrdinate_part, Ni], tf.float32,
name="incremental_farthest_search_op")
else:
incremental_farthest_search_op = tf.py_func(incremental_farthest_search, [single_corrdinate_part, Ni], tf.float32,
name="incremental_farthest_search_op")
# this part not processed
# [Ni, 1, d]
centroid_corrdinates = tf.reshape(incremental_farthest_search_op, [Ni, 1, self.d])
# [Ni, 1, d + c]
centroid_corrdinates_with_zeros = tf.concat([centroid_corrdinates, tf.zeros([Ni, 1, d_plus_c - self.d])],axis=-1)
# this part had centered
# [Ni, K - 1, d + c]
prepare_process_before_PointNet_op = tf.py_func(prepare_process_before_PointNet_with_feature, [single_corrdinate_part, single_feature, incremental_farthest_search_op, self.K], tf.float32,
name="prepare_process_before_PointNet_op")
########## 32 * 5 * 4
prepare_process_before_PointNet_op = tf.reshape(prepare_process_before_PointNet_op, [Ni, self.K - 1, d_plus_c])
# [Ni, K, d + c]
return tf.concat([centroid_corrdinates_with_zeros, prepare_process_before_PointNet_op], axis=1)
# [batch, Ni, K, d + c]
sampling_grouping_conclusion = tf.map_fn(single_sampling_grouping_procedure, inputs, dtype=tf.float32)
# [batch, Ni, 1, d + c] [batch, Ni, K - 1, d + c]
center_part, centerd_part = sampling_grouping_conclusion[:,:, 0:1, :], sampling_grouping_conclusion[:,:, 1:, :]
# [batch, Ni, d] drop feature dims (which filled by zeros)
center_part = tf.reshape(tf.squeeze(center_part[..., :self.d], axis=[2]), [-1, Ni, self.d])
return center_part, centerd_part
def fuse_corrdinate(self, corrdinate_inputs, pointNet_outputs):
# corrdinate_inputs [batch, Ni, d] pointNet_outputs [batch, Ni, Ci]
# [batch, Ni, d + Ci]
return tf.concat([corrdinate_inputs, pointNet_outputs], axis=-1)
def map_mini_pointNet_slice(self, inputs, slice_list = [3, 5, 7]):
assert slice_list[-1] == self.K - 1
return list(map(lambda slice_idx: inputs[:, :, :slice_idx, :], slice_list))
# implementation of mini_pointNet will reference to T_net_layer in PointNet
def mini_pointNet(self, inputs, Ni ,Ci, name = None):
# inputs [batch, N1, K - 1, d + c] N1 indicate clusters num, K single cluster elements num,
# d dim, c feature num, rigorously, K may not have full elements so will indexed by mask.
# we use lookup to retrieve feature, so use 0 to replace mask in the first time.
# the input of single K cluster must be centered, so the network can transform it without
# difference.
# the output of this layer may be [batch, N1, C1] and use centroid coordinate to expand it to
# [batch, N1, d + C1]
d_plus_c = int(inputs.get_shape()[-1])
# [batch * N1, K - 1, d + c]
K_1 = int(inputs.get_shape()[-2])
reshape_inputs = tf.reshape(inputs, [-1, K_1, d_plus_c])
batch_normalization_1 = partial(batch_normal_with_relu, name = "t_net_mlp_layer_first")
t_net_mlp_layer_first = mlp.MLP([64, 128, 1024], name = "t_net_mlp_{}_first".format(name),
activation=batch_normalization_1)
t_net_mlp_output_first = basic.BatchApply(t_net_mlp_layer_first)(reshape_inputs)
pool_size = int(t_net_mlp_output_first.get_shape()[1])
max_pool_output = tf.reshape(tf.layers.max_pooling1d(inputs=t_net_mlp_output_first, pool_size=pool_size, strides=1,
name="t_net_maxpool"), [-1, 1024])
batch_normalization_2 = partial(batch_normal_with_relu, name = "t_net_mlp_layer_second")
t_net_mlp_layer_second = mlp.MLP([512, 256, Ci], name = "t_net_mlp_{}_second".format(name),
activation=batch_normalization_2)
t_net_mlp_output_second = t_net_mlp_layer_second(max_pool_output)
output = tf.reshape(t_net_mlp_output_second, [-1, Ni, Ci])
return output
def Hierarchical_point_set_feature_learning_layer(self):
# in the first step only use one scale, in the future add mult-scale fuse procedure.
self.center_part_zero = self.input_cloud_points[...,:self.d]
self.mini_pointNet_zero_output = self.input_cloud_points[...,self.d:]
self.fuse_corrdinate_zero = self.input_cloud_points
with tf.variable_scope("sampling_grouping_layer_first"):
self.center_part_first, centerd_part_first = self.sampling_grouping_layer(self.N1, self.input_cloud_points)
centerd_part_first_list = self.map_mini_pointNet_slice(centerd_part_first)
centerd_part_first_feature = []
for i in range(len(centerd_part_first_list)):
with tf.variable_scope("centered_part_first_feature_{}".format(i)):
centerd_part_first_feature.append(self.mini_pointNet(centerd_part_first_list[i], self.N1, self.C1, name="mini_pointNet_first")[:,:self.N1,:self.C1])
self.mini_pointNet_first_output = tf.concat(centerd_part_first_feature, axis=-1)
self.fuse_corrdinate_first = self.fuse_corrdinate(self.center_part_first[:,:self.N1,:self.d], self.mini_pointNet_first_output)
with tf.variable_scope("sampling_grouping_layer_second"):
self.center_part_second, centerd_part_second = self.sampling_grouping_layer(self.N2, self.fuse_corrdinate_first)
centerd_part_second_list = self.map_mini_pointNet_slice(centerd_part_second)
centerd_part_second_feature = []
for i in range(len(centerd_part_second_list)):
with tf.variable_scope("centered_part_second_feature_{}".format(i)):
centerd_part_second_feature.append(self.mini_pointNet(centerd_part_second_list[i], self.N2, self.C2, name="mini_pointNet_first")[:,:self.N1,:self.C1])
self.mini_pointNet_second_output = tf.concat(centerd_part_second_feature, axis=-1)
self.fuse_corrdinate_second = self.fuse_corrdinate(self.center_part_second[:,:self.N2,:self.d], self.mini_pointNet_second_output)
def Segmentation_layer(self):
with tf.variable_scope("interpolate_layer_first"):
# [batch, N1, C2]
interpolate_feature_first = self.interpolate_layer(self.fuse_corrdinate_second, self.center_part_first)
# [batch, N1, C1 + C2]
before_input_pointNet_first = tf.concat([interpolate_feature_first, self.mini_pointNet_first_output], axis=-1)
# [batch, N1, 1, C1 + C2]
before_input_pointNet_first = tf.expand_dims(before_input_pointNet_first, 2)
# [batch, N1, C3]
self.mini_pointNet_third = self.mini_pointNet(before_input_pointNet_first, self.N1, self.C3, name="mini_pointNet_third")
# [batch, N1, d + C3]
self.fuse_corrdinate_third = self.fuse_corrdinate(self.center_part_first[:,:self.N1,:self.d], self.mini_pointNet_third)
with tf.variable_scope("interpolate_layer_second"):
# [batch, N, C3]
interpolate_feature_second = self.interpolate_layer(self.fuse_corrdinate_third, self.center_part_zero)
# [batch, N, C + C3]
before_input_pointNet_second = tf.concat([interpolate_feature_second, self.mini_pointNet_zero_output], axis=-1)
# [batch, N, 1, C + C3]
before_input_pointNet_second = tf.expand_dims(before_input_pointNet_second, 2)
# [batch, N, m]
self.mini_pointNet_fourth = self.mini_pointNet(before_input_pointNet_second, self.n, self.m, name="mini_pointNet_fourth")
def interpolate_layer(self, inputs, output_corrdinates):
# use self.center_part_* to indicate points for interplote
# inputs [batch, Ni, d + Ci] output_corrdinates [batch, Nj, d]
Ni = int(inputs.get_shape()[1])
Nj = int(output_corrdinates.get_shape()[1])
d_plus_ci = int(inputs.get_shape()[-1])
fuse_features = tf.concat([tf.reshape(inputs, [-1, Ni * d_plus_ci]),
tf.reshape(output_corrdinates, [-1, Nj * self.d])],
axis=-1)
def single_interpolate_procedure(input):
# [Ni, d + c] [Nj, d]
inputs_part, output_part = tf.reshape(input[ :Ni * d_plus_ci], [Ni, d_plus_ci]), tf.reshape(input[ Ni * d_plus_ci:], [Nj, self.d])
# [Ni, d] [Ni, c]
points, features = inputs_part[..., :self.d], inputs_part[..., self.d:]
centroid_points = output_part
segmentation_precedure_op = tf.py_func(segmentation_precedure, [points, features, centroid_points, self.K], tf.float32,
name="segmentation_precedure_op")
# [Nj, c]
# c2 * N1 : 32 * 32
segmentation_precedure_op = tf.reshape(segmentation_precedure_op, [Nj, d_plus_ci - self.d])
return segmentation_precedure_op
# [batch, Nj, c]
interpolate_feature = tf.map_fn(single_interpolate_procedure, fuse_features, dtype=tf.float32)
return interpolate_feature
def opt_construct(self):
labels = tf.one_hot(self.target, depth=self.m)
logits = self.mini_pointNet_fourth
self.logits = logits
self.segmentation_loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels = labels,
logits = logits))
self.total_loss = self.segmentation_loss
self.prediction = tf.argmax(tf.nn.softmax(logits, axis=-1), axis=-1)
self.accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.cast(self.prediction, tf.int32), self.target), tf.float32))
self.train_op = tf.train.AdamOptimizer(0.001).minimize(self.total_loss)
@staticmethod
def train(input_sess):
import os
import numpy as np
from uuid import uuid1
from copy import deepcopy
header_str = \
'''ply
format ascii 1.0
element vertex 0
property float x
property float y
property float z
property float intensity
property uchar diffuse_red
property uchar diffuse_green
property uchar diffuse_blue
property uchar pred_labels
property uchar true_labels
end_header\n'''
def centered_xy(cloud_points):
input_cloud_points = deepcopy(cloud_points)
input_cloud_points_list = [ele for ele in input_cloud_points]
def process_single(x_part_second):
x_part_second[:, 0] = (x_part_second[:, 0] - x_part_second[:, 0].min()) / (x_part_second[:, 0].max() - x_part_second[:, 0].min())
x_part_second[:, 1] = (x_part_second[:, 1] - x_part_second[:, 1].min()) / (x_part_second[:, 1].max() - x_part_second[:, 1].min())
return x_part_second
return np.asarray(list(map(process_single, input_cloud_points_list)), np.float32)
def serlize_points_and_label(input_cloud_points, pred_labels, true_labels, epoch):
if not os.path.exists(r"C:\Coding\Python\conclusion_p_{}".format(epoch)):
os.mkdir(r"C:\Coding\Python\conclusion_p_{}".format(epoch))
input_cloud_points, pred_labels, true_labels = input_cloud_points[0], pred_labels[0], true_labels[0]
concat_ndarray = np.concatenate([input_cloud_points, pred_labels.reshape([len(pred_labels), 1]), true_labels.reshape([len(true_labels), 1])],
axis=-1)
tail_str = "\n".join([" ".join(str(inner_ele) for inner_ele in line_array) for line_array in concat_ndarray])
full_str = header_str + tail_str
with open(r"C:\Coding\Python\conclusion_p_{}\{}.ply".format(epoch ,uuid1()), "w") as f:
f.write(full_str)
batch_size = 4
n = 1024 * 8
m = 8
train_gen = data_loader(train_dir, batch_size=batch_size)
valid_gen = data_loader(valid_dir, batch_size=batch_size)
model_ext = PointNet_pp(batch_size=batch_size, n = n, m = m)
step = 0
save_epoch = 3
saver = tf.train.Saver()
with input_sess as sess:
if os.path.exists(r"C:\Coding\Python\PointNet\pmm_{}.meta".format(save_epoch)):
saver.restore(sess ,r"C:\Coding\Python\PointNet\pmm_{}".format(save_epoch))
print("load exist")
else:
sess.run(tf.global_variables_initializer())
print("init_new")
while True:
step += 1
train_data = train_gen.__next__()
if step % 100 == 0:
print("train data consume end !")
saver.save(sess, r"C:\Coding\Python\PointNet\pmm_{}".format(save_epoch))
save_epoch += 1
step = 0
input_cloud_points, targets = train_data
_, train_loss, train_acc, train_pred, train_logits = sess.run([model_ext.train_op, model_ext.total_loss, model_ext.accuracy, model_ext.prediction,
model_ext.logits],
feed_dict={
model_ext.input_cloud_points: centered_xy(input_cloud_points),
model_ext.target: targets
})
if step % 1 == 0:
train_targets = targets.reshape([-1])
train_pred = train_pred.reshape([-1])
valid_data = valid_gen.__next__()
input_cloud_points, targets = valid_data
valid_loss, valid_acc, valid_pred = sess.run([model_ext.total_loss, model_ext.accuracy, model_ext.prediction],
feed_dict={
model_ext.input_cloud_points: centered_xy(input_cloud_points),
model_ext.target: targets
})
serlize_points_and_label(input_cloud_points, valid_pred * 32, targets * 32, save_epoch)
valid_targets = targets.reshape([-1])
valid_pred = valid_pred.reshape([-1])
print("epoch : {} step : {} train_loss : {:.2f} train_acc : {:.2f} valid_loss : {:.2f} valid_acc : {:.2f} train_f1 : {:.2f} valid_f1 : {:.2f}".format(save_epoch, step, train_loss, train_acc, valid_loss, valid_acc,
f1_score(train_targets, train_pred, average="macro"), f1_score(valid_targets, valid_pred, average="macro")))
if __name__ == "__main__":
PointNet_pp.train(sess)
对valid集效果进行如下聚合:
from pyntcloud import PyntCloud
import glob
def join_ply():
def process_values(concat_ndarray):
return "\n".join([" ".join(str(inner_ele) for inner_ele in line_array) for line_array in concat_ndarray])
header_str = \
'''ply
format ascii 1.0
element vertex 0
property float x
property float y
property float z
property float intensity
property uchar diffuse_red
property uchar diffuse_green
property uchar diffuse_blue
property uchar pred_labels
property uchar true_labels
end_header\n'''
all_files = glob.glob(r"C:\Coding\Python\conclusion_pointNet_PP" + "\\" + "*")
tail_str = "\n".join(map(lambda file: process_values(PyntCloud.from_file(file).points.values), all_files))
full_str = header_str + tail_str
with open("pointNet_PP.ply", "w") as f:
f.write(full_str)
if __name__ == "__main__":
join_ply()
下面就可以在Jupyter中进行可视化如下:(在Jupyter中运行代码,借助js)
先给一张整个valid集的图片:

from pyntcloud import PyntCloud
pointNet_cloud = PyntCloud.from_file(r"C:\Coding\Python\PointNet\pyntcloud_dataloader\pointNet.ply")
pointNet_cloud.plot(use_as_color="true_labels",cmap="cool")

pointNet_cloud.plot(use_as_color="pred_labels",cmap="cool")

pointNet_PP_cloud = PyntCloud.from_file(r"C:\Coding\Python\PointNet\pyntcloud_dataloader\pointNet_PP.ply")
pointNet_PP_cloud.plot(use_as_color="pred_labels",cmap="cool")

可见二者在一些细节上的差异。