前言:
对于Storm的编程模型有必要做一个详细的介绍(配合WC案例来介绍)
1、Storm编程模型
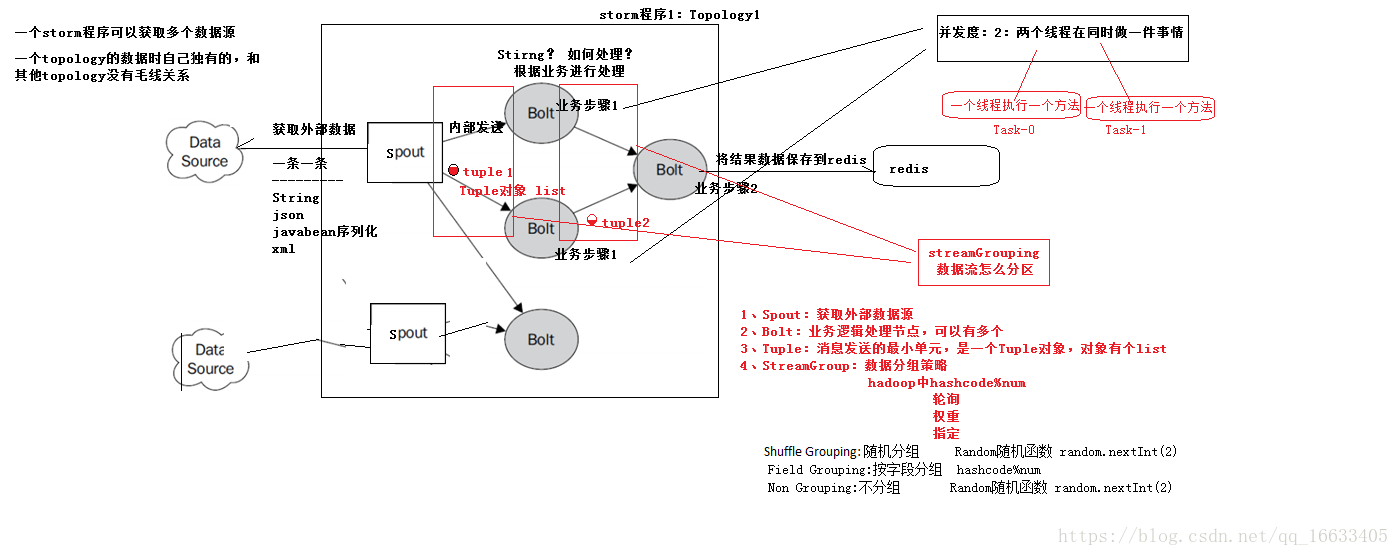
上图中组件的解释:
DataSource:外部数据源
Spout:接受外部数据源的组件,将外部数据源转化成Storm内部的数据,以Tuple为基本的传输单元下发给Bolt
Bolt:接受Spout发送的数据,或上游的bolt的发送的数据。根据业务逻辑进行处理。发送给下一个Bolt或者是存储到某种介质上。介质可以是Redis可以是mysql,或者其他。
Tuple:Storm内部中数据传输的基本单元,里面封装了一个List对象,用来保存数据。
StreamGrouping:数据分组策略
7种:shuffleGrouping(Random函数),Non Grouping(Random函数),FieldGrouping(Hash取模)、Local or ShuffleGrouping 本地或随机,优先本地。
- Shuffle Grouping: 随机分组, 随机派发stream里面的tuple,保证每个bolt接收到的tuple数目大致相同。
- FieldsGrouping:按字段分组,比如按userid来分组,具有同样userid的tuple会被分到相同的Bolts里的一个task,而不同的userid则会被分配到不同的bolts里的task。
- All Grouping:广播发送,对于每一个tuple,所有的bolts都会收到。
- Global Grouping:全局分组,这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。
- Non Grouping:不分组,这stream grouping个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle
grouping是一样的效果, 有一点不同的是storm会把这个bolt放到这个bolt的订阅者同一个线程里面去执行。 - Direct Grouping: 直接分组,这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的task的id(OutputCollector.emit方法也会返回task的id)。
- Local or shuffle grouping:如果目标bolt有一个或者多个task在同一个工作进程中,tuple将会被随机发生给这些tasks。否则,和普通的Shuffle Grouping行为一致。
FieldGrouping和shuffleGrouping 运行过程分析:
FieldsGroup:你会发现相同的数据被分到相同的线程中。
95 word:am
95 word:am
95 word:am
95 word:am
95 word:am
91 word:love
91 word:love
91 word:love
91 word:love
91 word:love
95 word:am
89 word:i
89 word:hanmeimei
89 word:i
89 word:hanmeimei
89 word:i
93 word:lilei
93 word:lilei
93 word:lilei
93 word:lilei
-----------------------------------
shuffleGroup:你会发现相同的数据被分到不同的线程中(数字代表线程id)
95 word:hanmeimei
89 word:love
95 word:hanmeimei
89 word:am
95 word:am
89 word:love
89 word:love
89 word:hanmeimei
89 word:am
95 word:love
95 word:hanmeimei
89 word:i
95 word:am
95 word:i
95 word:hanmeimei
95 word:i
95 word:hanmeimei
89 word:am
95 word:love
89 word:love
95 word:love2、对应的的WordCount案例
2.1、功能说明
设计一个topology,来实现对文档里面的单词出现的频率进行统计。
整个topology分为三个部分:
- RandomSentenceSpout:数据源,在已知的英文句子中,随机发送一条句子出去。
- SplitSentenceBolt:负责将单行文本记录(句子)切分成单词
- WordCountBolt:负责对单词的频率进行累加
执行wc时,通过Spout来读取数据,然后通过Bolt来切分数据(如map阶段)再通过另一个Bolt和上一个Bolt相连来进一步做单词的统计(通过hashmap来实现)
2.2、项目主要流程

首先new TopologyBuilder->setSpout(spot的id,new spot的实现类,并发度)->setBolt(Bolt的id,new Bolt的实现类,并发度)<可设置多个Bolt>->new Config->config设置worker的数量。
2.3、RandomSentenceSpout的实现及生命周期
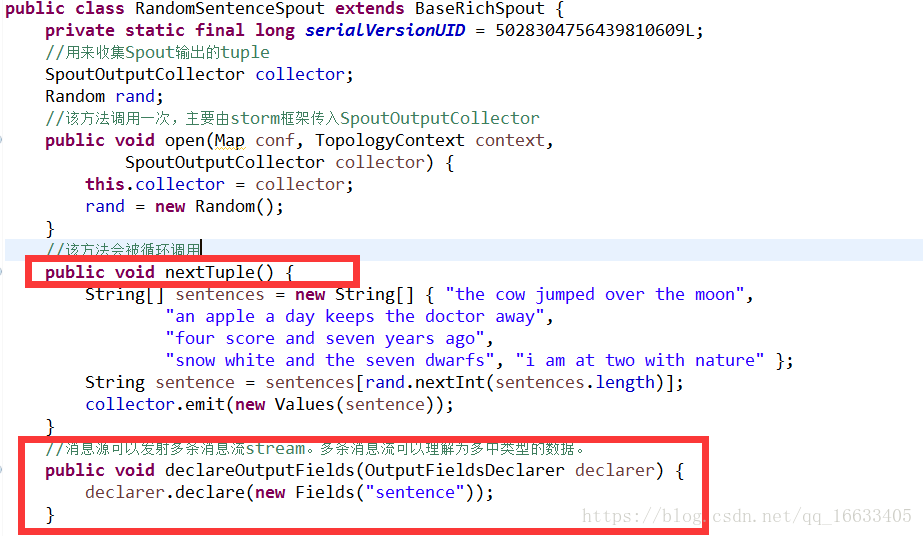
Spout的生命周期:open(初始化)->nextTuple(框架一直调用)->declareOutputFields(该方法用于声明自己发射出去的数据的类型(自定义或者可以理解为标识自己发射出去的数据))
2.4、SplitSentenceBolt的实现及生命周期
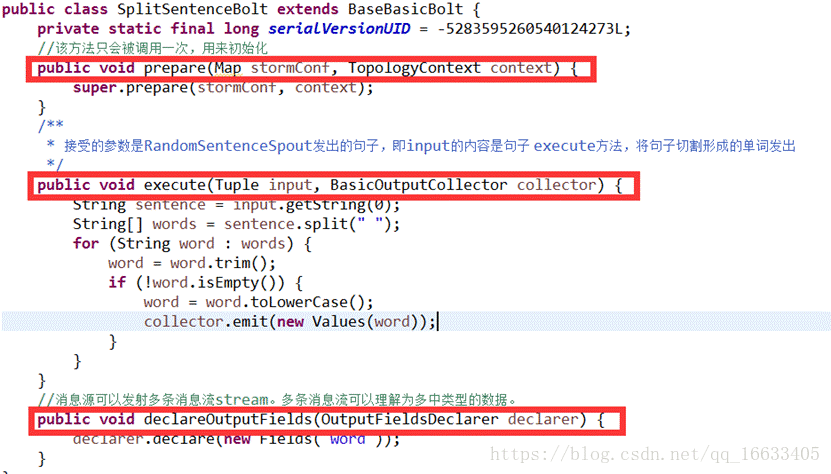
Bolt的生命周期:prepare(初始化)->execute(对传过来的tuple进行处理)->declareOutoutFields(声明输出的数据类型若输出数据类型为多个则声明多个如下图所示(自定义))
2.5、WordCountBolt的实现及生命周期
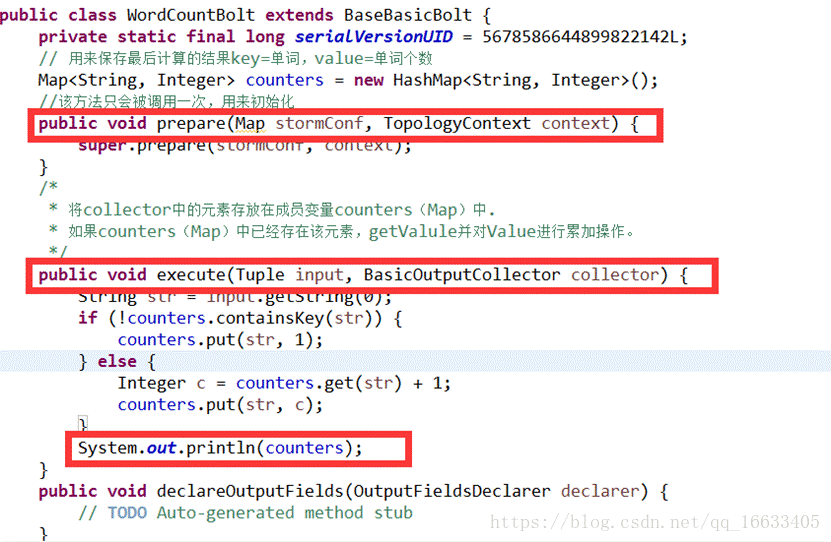
代码执行图:
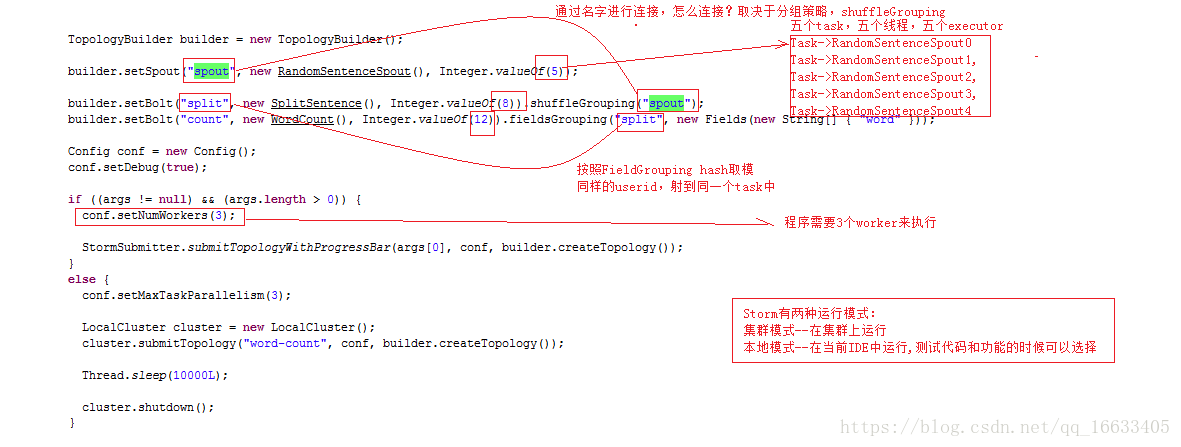
总结:
这篇文章最主要的目的还是让读者能够对Storm的编程模型有个初步的认识;至少你得能够看懂简单的WC案例,知道里面各个参数的含义,以及整个程序的执行流程。