dataSource:数据源,生产数据的东西
spout:接收数据源过来的数据,然后将数据往下游发送
bolt:数据的处理逻辑单元。可以有很多个,基本上每个bolt都处理一部分工作,然后将数据继续往下游的bolt发送
storm不会保存数据,也不会生产数据,只是一个数据的搬运工
tuple:元组的概念,可以理解为一个数组,或者一个集合,里面可以封装很多东西,数据从上游往下游发送,都是封装在tuple里面了
topology:spout与bolt组织到一起,形成一个topology
注意,配置文件比较严格,直接拷贝,尽量不要去手写!
===========================================
1、 storm的安装
三台机器运行服务规划
| 运行服务\机器规划 |
Node01 |
Node02 |
Node03 |
| Zookeeper版本 |
3.4.5 |
||
| Zookeeper服务 |
是 |
是 |
是 |
| Storm版本 |
Apache-storm-1.1.1 |
||
| Nimbus服务 |
是(leader) |
是 |
是 |
| Supervisor服务 |
是 |
是 |
是 |
| IP地址规划 |
192.168.52.100 |
192.168.52.110 |
192.168.52.120 |
3.1三台机器安装zookeeper服务
Node01配置文件修改
修改zoo.cfg
dataDir=/export/servers/zookeeper-3.4.9/zkData/data
dataLogDir=/export/servers/zookeeper-3.4.9/zkData/log
autopurge.snapRetainCount=3
autopurge.purgeInterval=1
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
修改myid
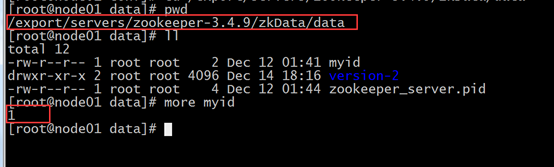
Node02 修改配置文件
修改zoo.cfg
dataDir=/export/servers/zookeeper-3.4.9/zkData/data
dataLogDir=/export/servers/zookeeper-3.4.9/zkData/log
autopurge.snapRetainCount=3
autopurge.purgeInterval=1
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
修改myid
Node03修改配置文件
修改zoo.cfg
dataDir=/export/servers/zookeeper-3.4.9/zkData/data
dataLogDir=/export/servers/zookeeper-3.4.9/zkData/log
autopurge.snapRetainCount=3
autopurge.purgeInterval=1
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
修改myid
三台服务器启动zookeeper服务
bin/zkServer.sh start
三台机器查看zookeeper服务状态
bin/zkServer.sh status
3.2、三台机器安装storm集群
1、上传storm压缩包
2、解压
tar -zxvf apache-storm-1.1.1.tar.gz -C ../servers/
3、修改配置文件
storm.zookeeper.servers:
- "node01"
- "node02"
- "node03"
#
nimbus.seeds: ["node01", "node02", "node03"]
storm.local.dir: "/export/servers/apache-storm-1.1.1/stormdata"
ui.port: 8088 #修改为8089,因为和kafka的8088冲突了
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
4、将storm安装程序分发拷贝到另外两台机器上
scp -r apache-storm-1.1.1/ node02:/export/servers/
scp -r apache-storm-1.1.1/ node03:$PWD
2、 三台机器启动storm服务
Node01 启动相关服务
启动 nimbus进程
nohup bin/storm nimbus >/dev/null 2>&1 &
启动web UI
nohup bin/storm ui >/dev/null 2>&1 &
启动logViewer
nohup bin/storm logviewer >/dev/null 2>&1 &
启动supervisor
nohup bin/storm supervisor >/dev/null 2>&1 &
Node02启动相关服务
nimbus:nohup bin/storm nimbus >/dev/null 2>&1 &
logviewer:nohup bin/storm logviewer >/dev/null 2>&1 &
supervisor:nohup bin/storm supervisor >/dev/null 2>&1 &
node03启动相关服务
nimbus:nohup bin/storm nimbus >/dev/null 2>&1 &
logviewer:nohup bin/storm logviewer >/dev/null 2>&1 &
supervisor:nohup bin/storm supervisor >/dev/null 2>&1 &
4、 storm的UI界面管理
访问地址
http://192.168.52.200:8089/index.html
2. storm的编程模型
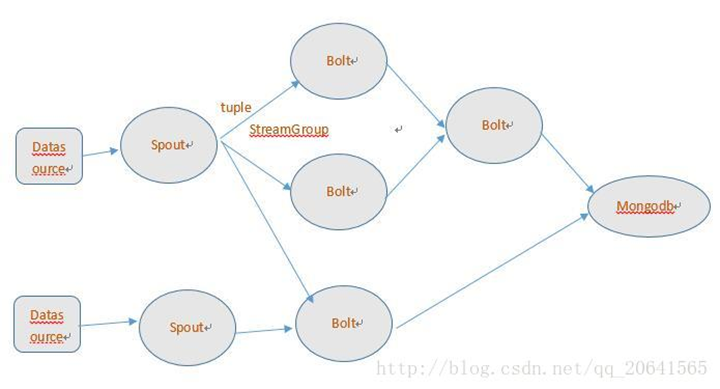
DataSource:外部数据源
Spout:接受外部数据源的组件,将外部数据源转化成Storm内部的数据,以Tuple为基本的传输单元下发给Bolt
Bolt:接受Spout发送的数据,或上游的bolt的发送的数据。根据业务逻辑进行处理。发送给下一个Bolt或者是存储到某种介质上。介质可以是mongodb或mysql,或者其他。
Tuple:Storm内部中数据传输的基本单元,里面封装了一个List对象,用来保存数据。
StreamGrouping:数据分组策略
7种:shuffleGrouping(Random函数),
Non Grouping(Random函数),
FieldGrouping(Hash取模)、
Local or ShuffleGrouping 本地或随机,优先本地。
其中Local or ShuffleGrouping 是如果分组的时候接收bolt的线程和发送者在一个JVM中默认优先选择一个JVM中的bolt就是local,否则和ShuffleGrouping效果一样。