概述
Apache Storm提供了一种基于Topology流计算的概念,Topology等价于hadoop中的mapreduce计算,MapReduce端最终会停止,Topology会一直运行,除非用户执行storm kill指令才会停止该计算。Storm的单个阶段每秒钟可以处理100万条数据/Tuple。
主流流计算框架:Kafka Streaming、Apache Storm、Spark Streaming、Flink DataStream等。
- Kafka Streaming:是一套基于Kafka-Streaming库的一套流计算工具jar包,具有简单容易集成等特点。
- Apache Storm/Jstorm:流处理框架实现对流数据流的处理和状态管理等操作。
- Spark Streaming:构建在Spark批处理之上的流处理框架,微观批处理,因此诟病 延迟较高。
- Flink DataStream/Blink:属于第三代流计算框架,吸取了Spark和Storm设计经验,在实时性和应用性上以及性能都有很大的提升,是目前为止最强的流计算引擎。
Storm-1.2.2之前的版本在和消息队列Kafka整合时会报错:STORM-3046,最好使用高一点的版本
Storm架构原理
Storm核心组件

Nimbus:负责Nimbus的资源分配和任务调度。
Supervisor:负责接收Nimbus分配的任务,启动和关闭属于自己管理的worker进程。通过配置文件设置这个supervisor上的worker数量。
Worker:负责运行具体处理组件逻辑的进程。worker运行的任务类型只有两种,一种是Spout任务,一种是Bolt任务。
Task:worker中每一个spout或者bolt的线程称为一个task,在storm0.8之后,task不在与物理线程对应,不同spout/bolt的task可能会共享一个物理线程,该线程称为executor。
Storm编程
Topology:Storm中运行的实时应用程序(拓扑)。
Spout:在一个topology中获取源数据流的组件。通常情况下spout会从外部数据源中读取数据,并且将数据封装成Tuple,然后转换为topology内部的源数据(将封装Tuple发射|emit到Topology中)。
Bolt:接受数据后执行处理的组件,用户可以在其中执行自己想要的操作。
Tuple:一次消息传递的基本单元,可以理解为一组消息就是一个Tuple。
Stream:数据流,无限制的Tuple序列,以分布式方式并行处理和创建
字符统计案例(入门):
- pom.xml
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>2.0.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-client</artifactId>
<version>2.0.0</version>
<scope>provided</scope>
</dependency>
Spout:
public class WordCountSpout extends BaseRichSpout {
private String[] lines={"this is a demo","hello Storm","ni hao"};
//该类负责将数据发送给下游
private SpoutOutputCollector collector;
public void open(Map<String, Object> conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector=collector;
}
//向下游发送Tuple ,改Tuple的Schemal在declareOutputFields声明
public void nextTuple() {
Utils.sleep(1000);//休息1s钟
String line=lines[new Random().nextInt(lines.length)];
collector.emit(new Values(line));
}
//对emit中的tuple做字段的描述
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
}
LineSplitBolt:
public class LineSplitBolt extends BaseRichBolt {
//该类负责将数据发送给下游
private OutputCollector collector;
public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) {
this.collector=collector;
}
public void execute(Tuple input) {
String line = input.getStringByField("line");
String[] tokens = line.split("\\W+");
for (String token : tokens) {
collector.emit(new Values(token,1));
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word","count"));
}
}
WordCountBolt
public class WordCountBolt extends BaseRichBolt {
//存储状态
private Map<String,Integer> keyValueState;
//该类负责将数据发送给下游
private OutputCollector collector;
public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) {
this.collector=collector;
keyValueState=new HashMap<String, Integer>();
}
public void execute(Tuple input) {
String key = input.getStringByField("word");
int count=0;
if(keyValueState.containsKey(key)){
count=keyValueState.get(key);
}
//更新状态
int currentCount=count+1;
keyValueState.put(key,currentCount);
//将最后结果输出给下游
collector.emit(new Values(key,currentCount));
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("key","result"));
}
}
WordPrintBolt
public class WordPrintBolt extends BaseRichBolt {
public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) {
}
public void execute(Tuple input) {
String word=input.getStringByField("key");
Integer result=input.getIntegerByField("result");
System.out.println(input+"\t"+word+" , "+result);
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
Topology
import org.apache.storm.Config;
import org.apache.storm.StormSubmitter;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
public class WordCountTopology {
public static void main(String[] args) throws Exception {
//1.创建TopologyBuilder
TopologyBuilder builder = new TopologyBuilder();
//2.编织流处理逻辑- 重点(Spout、Bolt、连接方式)
builder.setSpout("WordCountSpout",new WordCountSpout(),1);
builder.setBolt("LineSplitBolt",new LineSplitBolt(),3)
.shuffleGrouping("WordCountSpout");//设置 LineSplitBolt 接收上游数据通过 随机
builder.setBolt("WordCountBolt",new WordCountBolt(),3)
.fieldsGrouping("LineSplitBolt",new Fields("word"));
builder.setBolt("WordPrintBolt",new WordPrintBolt(),4)
.fieldsGrouping("WordCountBolt",new Fields("key"));
//3.提交流计算
Config conf= new Config();
conf.setNumWorkers(3); //设置Topology运行所需的Worker资源,JVM个数
conf.setNumAckers(0); //关闭Storm应答,可靠性有关
StormSubmitter.submitTopology("worldcount",conf,builder.createTopology());
}
}
Storm程序并发机制
Workers(JVMs):在一个物理节点上可以运行一个或多个独立JVM进程。一个Topology可以包含一个或多个worker(并行的跑在不同的物理机上),所以worker process就是执行一个topology的子集。注意:一个worker只能对应一个topology。为提高并发效果,Worker的数目至少应该大于machines的数目
Executors(线程):在一个worker JVM进程中运行着多个Java线程。一个Executors线程可以执行一个或多个tasks。只能在代码中配置executor的个数。
Tasks(spout|bolt):Task是具体的处理逻辑对象,每一个Spout和Bolt会被当做很多task在整个集群里执行。stream grouping是定义怎么从一堆task发射tuple到另外一对task。通过TopologyBuilder.setSpout 和TopBuilder.setBolt可以设置并行度,也就是多少个task。默认一个executor中一个task。
Storm消息容错机制
概念:
-
Storm中,可靠的信息处理机制是从spout开始的。
-
提供了可靠信息处理机制的spout需要记录他发射出去的tuple,当下游bolt处理tuple或者子tuple失败是spout能够重新发射。
-
Storm通过调用Spout的nextTuple()发送一个tuple。为了实现可靠的消息处理,首先要给每个发出的tuple带上唯一的ID,并且将ID作为参数传递给SpoutOutputCollector的emit()方法:collector.emit(new Values(“value1”,“value2”),msgId);messageid就是用来标示唯一tuple的,而rootid是随机生成的。
给每个tuple指定ID告诉Storm系统,无论处理成功还是失败,spout都要接受tuple树上所有节点返回的通知。如果处理成功,spout的ack()方法将会对编号是msgId的消息应答确认;如果处理失败或超时,会调用fail()方法。
实现:
Storm系统中有一组叫做“acker”的特殊任务,负责跟踪有向无环图(DAG)中的每个消息。
acker任务保存了spout id 到一对值的映射,第一个值就是spout的任务id,通过这个id,Acker就知道消息处理完成时该通知哪个spout任务。第二个值是一个64bit的数字,我们称之为“ack val”,他是树中所有消息的随机id异或计算结果。
ack val 表示了整棵树的状态,当消息被创建和被应答的时候都会有相同的消息id发送过来做异或。当acker发现一棵树的ack val值为0的时候,就知道这棵树已经被完全处理了。
bolt的可靠消息处理机制包含两个步骤:
a、当发射衍生的tuple,需要锚定读入的tuple
b、当处理消息时,需要应答或报错
可以通过OutputCollector中emit()的一个重载函数锚定或tuple:collector.emit(tuple, new Values(word)); 并且需要调用一次this.collector.ack(tuple)应答。
异或计算处理流程如下图: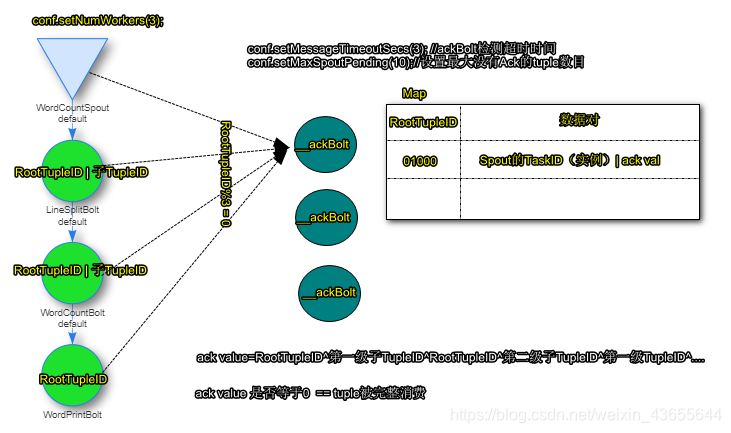
spout端:
- 发射tuple时必须提供msgId
- 覆盖ack和fail方法
public class WordCountSpout extends BaseRichSpout {
private String[] lines={"this is a demo","hello Storm","ni hao"};
private SpoutOutputCollector collector;
public void open(Map<String, Object> conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector=collector;
}
public void nextTuple() {
Utils.sleep(5000);//休息1s钟
int msgId = new Random().nextInt(lines.length);
String line=lines[msgId];
//发送 Tuple 指定 msgId
collector.emit(new Values(line),msgId);
}
//对emit中的tuple做字段的描述
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
//发送成功回调 AckerBolt
@Override
public void ack(Object msgId) {
System.out.println("发送成功:"+msgId);
}
//发送失败回调 AckerBolt
@Override
public void fail(Object msgId) {
String line = lines[(Integer) msgId];
System.out.println("发送失败:"+msgId+"\t"+line);
}
}
bolt端:
- 将当前字tuple锚定到父tuple上,
- 向上游应答当前父tuple的状态 collector.ack(); | collector.fail();
BasicBolt|BaseBasicBolt
许多Bolt遵循读取输入元组的共同模式(锚定、ack出错fail),基于它发出元组,然后在执行方法结束时执行元组。因此Storm给我们提供了一套规范,如果用户使用Ack机制,在编写Bolt的时候只需要实现BasicBolt接口或者继承BaseBasicBolt类即可。
public class WordCountBolt extends BaseBasicBolt {
//存储状态
private Map<String,Integer> keyValueState;
@Override
public void prepare(Map<String, Object> topoConf, TopologyContext context) {
keyValueState=new HashMap<String, Integer>();
}
public void execute(Tuple input, BasicOutputCollector collector) {
String key = input.getStringByField("word");
int count=0;
if(keyValueState.containsKey(key)){
count=keyValueState.get(key);
}
//更新状态
int currentCount=count+1;
keyValueState.put(key,currentCount);
//将最后结果输出给下游
collector.emit(new Values(key,currentCount));
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("key","result"));
}
}
关闭ack机制
- 设置NumAcker数目为0
- Spout端不提供msgID
- Bolt不使用锚定
好处:提升Storm处理性能,减少延迟
Storm状态管理
Storm提供了一种Bolt存储和查询自己操作状态的状态管理机制,目前Storm提供了一个默认的实现,该实现基于内存实现。此外还提供了基于Redis/Memcached和Hbase等的实现。提供了StateFulBolt | BaseStatefulBolt 用于实现Bolt的状态管理。
代码如下:
public class WordCountBolt extends BaseStatefulBolt<KeyValueState<String,Integer>> {
private KeyValueState<String,Integer> state;
private OutputCollector collector;
public void initState(KeyValueState<String,Integer> state) {
this.state=state;
}
@Override
public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) {
this.collector=collector;
}
public void execute(Tuple input) {
String key = input.getStringByField("word");
Integer count=input.getIntegerByField("count");
Integer historyCount = state.get(key, 0);
Integer currentCount=historyCount+count;
//更新状态
state.put(key,currentCount);
//必须锚定当前的input
collector.emit(input,new Values(key,currentCount));
collector.ack(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("key","result"));
}
}
含有State的bolt的Topology必须开启Ack机制
集成Redis实现状态持久化
- 引入maven依赖
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-redis</artifactId>
<version>2.0.0</version>
</dependency>
- 安装Redis
[root@CentOSA ~]# yum install -y gcc-c++
[root@CentOSA ~]# tar -zxf redis-3.2.9.tar.gz
[root@CentOSA ~]# cd redis-3.2.9
[root@CentOSA redis-3.2.9]# vi redis.conf
bind CentOSA
protected-mode no
daemonize yes
[root@CentOSA redis-3.2.9]# ./src/redis-server redis.conf
[root@CentOSA redis-3.2.9]# ps -aux | grep redis-server
出现如下信息表示安装成功
Warning: bad syntax, perhaps a bogus '-'? See /usr/share/doc/procps-3.2.8/FAQ
root 41601 0.1 0.5 135648 5676 ? Ssl 14:45 0:00 ./src/redis-server CentOSA:6379
root 41609 0.0 0.0 103260 888 pts/1 S+ 14:45 0:00 grep redis-server
- 配置topology,添加配置信息
//配置Redis
conf.put(Config.TOPOLOGY_STATE_PROVIDER,"org.apache.storm.redis.state.RedisKeyValueStateProvider");
Map<String,Object> stateConfig = new HashMap<String,Object>();
Map<String,Object> redisConfig = new HashMap<String,Object>();
redisConfig.put("host","CentOS-Redis");//配置redis服务器主机IP
redisConfig.put("port",6379);//redis端口号
stateConfig.put("jedisPoolConfig",redisConfig);
ObjectMapper objectMapper = new ObjectMapper();
conf.put(Config.TOPOLOGY_STATE_PROVIDER_CONFIG,objectMapper.writeValueAsString(stateConfig));
集成Hbase实现持久化
- 导入依赖
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-hbase</artifactId>
<version>2.0.0</version>
</dependency>
- 安装Hbase(略)
- 配置topology,添加配置信息
config.put(Config.TOPOLOGY_STATE_PROVIDER,"org.apache.storm.hbase.state.HBaseKeyValueStateProvider");
Map<String,Object> hbaseConfig = new HashMap<String,Object>();
hbaseConfig.put("hbase.zookeeper.quorum", "CentOS-hbase");//Hbase zookeeper连接参数
config.put("hbase.conf",hbaseConfig);
ObjectMapper objectMapper = new ObjectMapper();
Map<String,Object> stateConfig = new HashMap<String,Object>();
stateConfig.put("hbaseConfigKey","hbase.conf");
stateConfig.put("tableName","demo1:wordcountstate");
stateConfig.put("columnfamily","cf");
config.put(Config.TOPOLOGY_STATE_PROVIDER_CONFIG,objectMapper.writeValueAsString(stateConfig));
Kafka Storm集成(kafka作为storm数据来源)
- 所需依赖
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka-client</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.2.0</version>
</dependency>
- 构建Kafkaspout
public class KafkaTopologyDemo {
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
String boostrapServers="CentOSA:9092,CentOSB:9092,CentOSC:9092";
String topic="topic01";
KafkaSpout<String, String> kafkaSpout = buildKafkaSpout(boostrapServers,topic);
//默认输出的Tuple格式 new Fields(new String[]{"topic", "partition", "offset", "key", "value"});
builder.setSpout("KafkaSpout",kafkaSpout,3);
builder.setBolt("KafkaPrintBlot",new KafkaPrintBlot(),1)
.shuffleGrouping("KafkaSpout");
Config conf = new Config();
conf.setNumWorkers(3);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("kafkaspout",conf,builder.createTopology());
}
public static KafkaSpout<String, String> buildKafkaSpout(String boostrapServers,String topic){
KafkaSpoutConfig<String,String> kafkaspoutConfig=KafkaSpoutConfig.builder(boostrapServers,topic)
.setProp(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer")
.setProp(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer")
.setProp(ConsumerConfig.GROUP_ID_CONFIG,"g1")
.setEmitNullTuples(false)
.setFirstPollOffsetStrategy(FirstPollOffsetStrategy.LATEST)
.setProcessingGuarantee(KafkaSpoutConfig.ProcessingGuarantee.AT_LEAST_ONCE)
.setMaxUncommittedOffsets(10)//一旦分区积压有10个未提交offset,Spout停止poll数据,解决Storm背压问题
.setRecordTranslator(new MyRecordTranslator<String, String>())
.build();
return new KafkaSpout<String, String>(kafkaspoutConfig);
}
}
MyRecordTranslator
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.storm.kafka.spout.DefaultRecordTranslator;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import java.util.List;
public class MyRecordTranslator<K, V> extends DefaultRecordTranslator<K, V> {
@Override
public List<Object> apply(ConsumerRecord<K, V> record) {
return new Values(new Object[]{record.topic(),record.partition(),record.offset(),record.key(),record.value(),record.timestamp()});
}
@Override
public Fields getFieldsFor(String stream) {
return new Fields("topic","partition","offset","key","value","timestamp");
}
}
Kafka Hbase Redis 整合(从Kafka获取数据,Redis存储状态,Hbase存储最终输出)
- 所需依赖
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>2.0.0</version>
<scope>provide</scope>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-client</artifactId>
<version>2.0.0</version>
<scope>provide</scope>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-redis</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-hbase</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka-client</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.2.0</version>
</dependency>
- WordCounrTopology
public class WodCountTopology {
public static void main(String[] args) throws Exception {
TopologyBuilder builder=new TopologyBuilder();
Config conf = new Config();
//Redis 状态管理
conf.put(Config.TOPOLOGY_STATE_PROVIDER,"org.apache.storm.redis.state.RedisKeyValueStateProvider");
Map<String,Object> stateConfig=new HashMap<String,Object>();
Map<String,Object> redisConfig=new HashMap<String,Object>();
redisConfig.put("host","CentOSA");
redisConfig.put("port",6379);
stateConfig.put("jedisPoolConfig",redisConfig);
ObjectMapper objectMapper=new ObjectMapper();
System.out.println(objectMapper.writeValueAsString(stateConfig));
conf.put(Config.TOPOLOGY_STATE_PROVIDER_CONFIG,objectMapper.writeValueAsString(stateConfig));
//配置Hbase连接参数
Map<String, Object> hbaseConfig = new HashMap<String, Object>();
hbaseConfig.put("hbase.zookeeper.quorum", "CentOSA");
conf.put("hbase.conf", hbaseConfig);
//构建KafkaSpout
KafkaSpout<String, String> kafkaSpout = KafkaSpoutUtils.buildKafkaSpout("CentOSA:9092,CentOSB:9092,CentOSC:9092", "topic01");
builder.setSpout("KafkaSpout",kafkaSpout,3);
builder.setBolt("LineSplitBolt",new LineSplitBolt(),3)
.shuffleGrouping("KafkaSpout");
builder.setBolt("WordCountBolt",new WordCountBolt(),3)
.fieldsGrouping("LineSplitBolt",new Fields("word"));
SimpleHBaseMapper mapper = new SimpleHBaseMapper()
.withRowKeyField("key")
.withColumnFields(new Fields("key"))
.withCounterFields(new Fields("result"))//要求改field的值必须是数值类型
.withColumnFamily("cf1");
HBaseBolt haseBolt = new HBaseBolt("baizhi:t_words", mapper)
.withConfigKey("hbase.conf");
builder.setBolt("HBaseBolt",haseBolt,3)
.fieldsGrouping("WordCountBolt",new Fields("key"));
StormSubmitter.submitTopology("wordcount1",conf,builder.createTopology());
}
}
- LineSplitBolt
public class LineSplitBolt extends BaseBasicBolt {
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word","count"));
}
public void execute(Tuple input, BasicOutputCollector collector) {
String line = input.getStringByField("value");
String[] tokens = line.split("\\W+");
for (String token : tokens) {
//锚定当前Tuple
collector.emit(new Values(token,1));
}
}
}
- WordVountBolt
public class WordCountBolt extends BaseStatefulBolt<KeyValueState<String,Integer>> {
private KeyValueState<String,Integer> state;
private OutputCollector collector;
public void initState(KeyValueState<String,Integer> state) {
this.state=state;
}
@Override
public void prepare(Map<String, Object> topoConf, TopologyContext context, OutputCollector collector) {
this.collector=collector;
}
public void execute(Tuple input) {
String key = input.getStringByField("word");
Integer count=input.getIntegerByField("count");
Integer historyCount = state.get(key, 0);
Integer currentCount=historyCount+count;
//更新状态
state.put(key,currentCount);
//必须锚定当前的input
collector.emit(input,new Values(key,currentCount));
collector.ack(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("key","result"));
}
}
- maven远程下载
[root@CentOS ~]# storm jar storm-lowlevel-1.0-SNAPSHOT.jar com.baizhi.demo09.WodCountTopology --artifacts 'org.apache.storm:storm-redis:2.0.0,org.apache.storm:storm-hbase:2.0.0,org.apache.storm:storm-kafka-client:2.0.0,org.apache.kafka:kafka-clients:2.2.0' --artifactRepositories 'local^http://192.168.111.1:8081/nexus/content/groups/public/'
- 在项目中添加插件
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>