1. 简介
实时的流式 处理框架 storm 进程长期运行在内存,在内存中作运算
基本名词:
1. topolgy : DAG有向无环图的实现,包含了应用程序的逻辑,是对storm实时计算的封装,计算拓扑,即,由一系列通过数据流相互关联的Spout、Bolt所组成的拓扑结构,启动后会不停的计算,除非手动终止
2. spout :消息流的源头,Topology的消息生产者。
3. bolt:数据流处理组件,相当于每个数据处理节点,每个任务分发到若干个bolt 中进行计算
4. tuple:Stream 最小的数据组成单元。
5. Stream :数据流 spout > bolt > bolt >.. 形成的数据传输
6. Stream grouping : 数据传输分发策略, (
shuffle grouping--随机分组
Fields grouping--按照字段分组
all grouping--广播发送
global grouping--全局分组
none grouping--部分组
direct grouping--指向型分组
local or shuffle grouping--本地或者随机
custom grouping 自定义 )
《 ******************大家可以想象为流水线工作,每个bolt 做单一的任务职责,******************************* 》
7.Nimbus: Storm集群主节点,负责资源分配和任务调度。我们提交任务和截止任务都是在Nimbus上操作的。一个Storm集群只有一个Nimbus节点。 主要功能和yarn 中的resourceManager 一样
8. Supervisor: 接受nimbus 分配的任务,管理自己的worker进程,当前supervisor上worker数量由配置文件设定, 默认为4个
9. Worker : 运行具体处理运算组件的进程(每个Worker对应执行一个Topology的子集),worker 任务有两种,即spout,bolt 。一般默认负责执行一个task 任务,也可以有多个;
10. Reliability :可靠性,Storm保证每个Tuple都会被处理。
11. zookeeper: 略
Hadoop
Storm
主节点
ResourceManager
Nimbus
从节点
NodeManager
Supervisor
应用程序
Job
Topology
工作进程
Child
Worker
计算模型
Map/Reduce
Spout/Bolt
1. 单机安装:
环境:jdk, python 2.6+
安装包:官网下载, 获取看其他文章获取本人公开网盘,自己寻找/
准备:jdk py strom

1. 安装jdk ram -ivh jdk-7u67-linux-x64.rpm
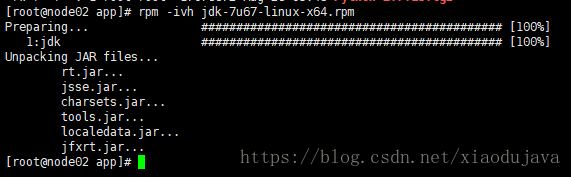
默认安装到 usr 下的java 中
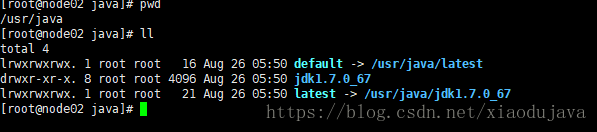
配置环境变量:
vim /etc/profile

推出保存 运行 source /etc/profile

2. 配置 python 环境
查看 python 版本 《大写的V》

如果没有 需要配置 py 安装
(没有python 环境的需要安装****************************1. 更新 yum 库
yum groupinstall Development tools 下载更新所有的 安装配置 环境

2. 预编译 进入到py 包内

3. 编译 并安装
make && make install ************************ ******)
4. 解压 storm 包
5.查看命令的方式
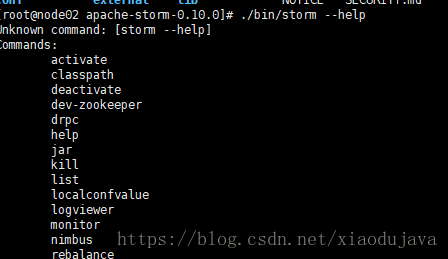
6. 启动 zookeeper <storm 自带一个zookeeper>
mkdir logs 在 storm 中创建一个logs 目录存放日志
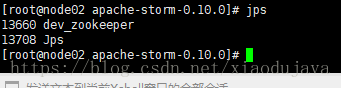
执行命令:./bin/storm dev-zookeeper >> ./logs/zk.out 2>&1 &

jps 查看到 dev_zookeeper 进程
启动主节点:
./bin/storm nimbus >> ./logs/nimbus.out 2>&1 &

启动 UI
./bin/storm ui >> ./logs/ui.out 2>&1 &

启动:supervisor

启动 :日志

《******以上命令也可以写成脚本运行******》
启动完成
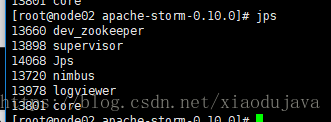
就可以运行 你的 jar 了

注意 jdk 版本 是否一致