版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_32297447/article/details/79831449
环境准备 :
JDK1.8
Hadoop2.7.5(Hadoop集群是伪分布式)
maven 3.5.2
protocolBuffer 2.5.0
snappy1.1.1
注意:如果你的Hadoop编译成功的话,可以支持zlib、snappy、lz4、bzip2、openssl5种本地压缩
1、编译步骤:
下载源代码
安装依赖软件或库
编译打包
2、安装软件
安装JDK1.7+并配置环境变量,前面博客中有,自行查看
安装各种库(root用户下)
# yum -y install svn ncurses-devel gcc*
# yum -y install lzo-devel zlib-devel autoconf automake libtool cmake openssl-devel
如果安装完上述工具后,还是缺少可以使用如下命令来检测安装
# yum -y groupinstall “Development Tools”
3、protobuf(hadoop用户下)
下载
:hadoop使用protocol buffer进行通信,需要下载和安装 protobuf-2.5.0.tar.gz
解压编译安装:
https://pan.baidu.com/s/1pJlZubT
安装
使用tar -zxf protobuf-2.5.0.tar.gz命令解压后得到是 protobuf的源码,
$ cd protobuf 进入目录
假如你希望编译成功后输出的目录 为
/home/hadoop
/hadoop_work/protobuf/ 则输入如下两条命令:
$
./configure --prefix=
/home/hadoop
/hadoop_work/protobuf/
$
make && make install
编译成功后将export PATH=
/home/hadoop
/hadoop_work/protobuf/bin:$PATH加入到环境变量中,
$ source ~/.bashrc
最后输入 protoc --version命令,如显示 libprotoc 2.5.0 则安装成功
如果在编译安装的时候报如下错误
libtool: install: error: cannot install `libaprutil-1.la’ to a directory
原因:可能是以前安装用过./configure,导致安装文件已经不太“干净”
解决方法:
(1).执行命令make clean
(2).删除刚刚编译安装的目录protobuf,重新解压安装编译即可
4、snappy(hadoop用户下)
下载
:
Snappy是一个压缩/解压缩库
安装:
使用
# tar -zxvf snappy-1.1.1.tar.gz
命令解压后得到是
snappy-1.1.1
的源码
# cd snappy-1.1.1
进入目录
编译
# ./config ure
编译
# make && make install
检查snappy是否安装完成
# ll /usr/local/lib/ | grep snappy

注意:编译时要在root用户下(#代表的是root用户)
5、hadoop编译
5.1配置maven
解压、重命名、配置环境变量
#maven
export MAVEN_HOME=/home/hadoop/app/maven
export PATH=$PATH:$MAVEN_HOME/bin
$ source ~/.bashrc
$ mvn -v 检查是否配置成功
配置settings.xml的两个地方
jar库
<localRepository>/home/hadoop/app/maven_jars</localRepository>
镜像代理
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
5.2编译Hadoop
hadoop 编译前将hadoop本地库加入到环境变量
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"
从官网下载hadoop的源码包,解压
$ tar -zxvf hadoop-2.7.5-src.tar.gz
$ mv hadoop-2.7.5-src.tar.gz hadoop_src $ cd hadoop-src/
输入如下命令开始编译,编译过程较长,耐心等待
$ mvn package -DskipTests -Pdist,native -Dtar -Drequire.snappy -e -X
如果看到BUILD SUCCESS,且没有异常信息,说明hadoop已经编译成功
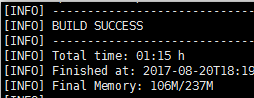
编译完成后可以看到hadoop的压缩包
$ cd /home/hadoop/makes/hadoop_src/hadoop-dist/target

把hadoop jar 包 拷贝到app目录下
cp hadoop-2.7.5.tar.gz /home/hadoop/app/
解压编译好的hadoop压缩包,替换掉里面的core&&hdfs配置文件即可
启动输入如下命令
$ hdfs namenode -format #只在第一次启动时执行,status 为0格式化成功
$ start-dfs.sh
$ start-yarn.sh
$ mr-jobhistory-daemon.sh start historyserver

检查hadoop的本地库
$ hadoop checknative

到hadoop2.7.5源码的解压目录下,输入下面命令:
mvn package -Pdist,native -DskipTests -Dtar
或者这个
mvn package -Pdist,native,docs,src -DskipTests -Dtar
前面只编译本地代码,后者编译本地代码和文档,因此前者速度较快。
接下来就是漫长的等待,等出现这个就说明编译成功