简介
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。为了更好演示集群分布,本文没有使用一台电脑上构建多个虚拟机的方法来模拟集群,而是使用三台虚拟机来搭建一个小型分布式集群环境安装。本文记录如何搭建并配置Hadoop分布式集群环境。
环境
- Linux系统:三台装有CentOS 7的虚拟机
- JDK版本:jdk-8u144-linux-x64.tar.gz
- Hadoop版本:hadoop-2.7.3.tar.gz
- 辅助工具:Xshell 5 ,WinSCP
集群机器
本文是在一台服务器上创建三台虚拟机来搭建一个小型分布式集群环境安装。一台CentOS主机系统作master,一台CentOS主机系统做slave01,一台CentOS主机系统做slave02。三台主机机器处于同一局域网下。
IP在不同局域网环境下有可能不同,可以用ip a 命令查看当前主机的IP
ip a
即可获得当前主机的IP在局域网的地址,如下图:
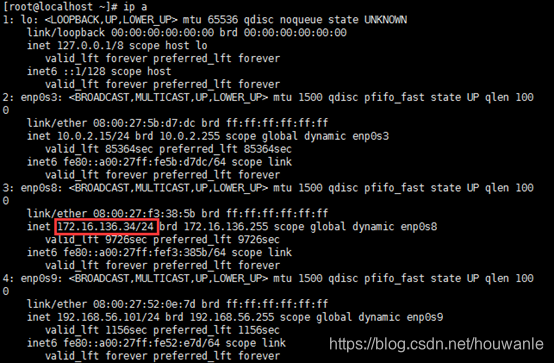
三台机器的名称和IP如下:
| 主机名称 | ip地址 |
|---|---|
| master | 172.16.136.34 |
| slave01 | 172.16.136.32 |
| slave02 | 172.16.136.28 |
三台电脑主机的用户名均为root。
三台机器可以ping双方的ip来测试三台电脑的连通性。
在master节点主机上的Shell中运行如下命令,测试能否连接到slave01节点主机。
ping 172.16.136.32
如果出现如下图,说明连接成功:

为了更好的在Shell中区分三台主机,修改其显示的主机名,执行如下命令:
vi /etc/hostname
| i | 进入插入操作 |
|---|---|
| Esc | 退出插入操作 |
| :wq | 保存并退出 |
| :q | 直接退出 |
| :!q | 强制退出 |
在master节点的/etc/hostname添加如下配置:

在slave01的/etc/hostname添加如下配置:

在slave02的/etc/hostname添加如下配置:

重启三台电脑,重启后在终端Shell中才会看到机器名的变化,如下图:
修改三台机器的/etc/hosts文件,添加同样的配置:
vi /etc/hosts
配置如下:
| ip地址 | 主机名 |
|---|---|
| 127.0.0.1 | localhost |
| 172.16.136.34 | master |
| 172.16.136.32 | slave01 |
| 172.16.136.28 | slave02 |
配置ssh无密码登录本机和访问集群机器
三台主机电脑分别运行如下命令,测试能否连接到本地localhost
ssh localhost
登录成功会显示如下结果:

如果不能登录本地,请运行如下命令,安装openssh-server,并生成ssh公钥。
ssh-keygen -t rsa -P ""
cd .ssh
cat id_rsa.pub >> authorized_keys
在保证了三台主机电脑都能连接到本地localhost后,还需要让master主机免密码登录slave01和slave02主机。在master执行如下命令,将master的id_rsa.pub传送给两台slave主机。
scp ~/.ssh/id_rsa.pub root@slave01:/root/
scp ~/.ssh/id_rsa.pub root@slave02:/root/
在slave01,slave02主机上分别运行ls命令:
ls
可以看到slave01、slave02主机分别接收到id_rsa.pub文件:


接着在slave01、slave02主机上将master的公钥加入各自的节点上,在slave01和slave02执行如下命令:
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
rm ~/id_rsa.pub
如果master主机和slave01、slave02主机的用户名一样,那么在master主机上直接执行如下测试命令,即可让master主机免密码登录slave01、slave02主机。
ssh slave01
如果master主机和slave01主机的用户名不一样,还需要在master修改~/.ssh/config文件,如果没有此文件,自己创建文件。
Host master
user Ruanrc
Host slave01
user hadoop
然后master主机再执行免密码登录:
ssh slave01
登陆成功后会出现如下图所示:

JDK和Hadoop安装配置
分别在master主机和slave01、slave02主机上安装JDK和Hadoop,并加入环境变量。
安装JDK
分别在master主机和slave01,slave02主机上执行安装JDK的操作。
在/usr/目录下创建java目录:
mkdir /usr/java
cd /usr/java
将提前下载好的JDK压缩包用WinSCP上传到/usr/java下并解压:
tar -zxvf jdk-8u144-linux-x64.tar.gz
设置环境变量:
cd ~
vi /etc/bashrc
在bashrc中添加如下内容:
#set java environment
JAVA_HOME=/usr/java/jdk1.8.0_144
JRE_HOME=/usr/java/jdk1.8.0_144/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
让刚才修改的内容生效:
source /etc/bashrc
验证JDK
java -version

然后分别在其他节点上重复以上JDK安装步骤。
安装hadoop
先在master主机上做安装Hadoop,暂时不需要在slave01,slave02主机上安装Hadoop.稍后会把master配置好的Hadoop发送给slave01,slave02。
在master主机执行如下操作:
将提前下载好的hadoop安装包用WinSCP软件上传到root文件夹下,然后解压到/usr/local文件夹下:
tar -zxvf /root/hadoop-2.7.3.tar.gz -C /usr/local/
将文件夹名字改为hadoop:
cd /usr/local
mv ./hadoop-2.7.3/ ./hadoop
编辑bashrc文件:
vi /etc/bashrc
添加如下内容:
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
接着让环境变量生效:
source /etc/bashrc
Hadoop集群配置
修改master主机修改Hadoop如下配置文件,这些配置文件都位于/usr/local/hadoop/etc/hadoop目录下。
修改slaves,这里把DataNode的主机名写入该文件,每行一个。这里让master节点主机仅作为NameNode使用。
slave01
slave02
- core-site.xml 添加:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
- hdfs-site.xml 添加:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hdfs/name</value>
<description> </description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hdfs/data</value>
<description> </description>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
- mapred-site.xml 文件(复制mapred-site.xml.template,再修改文件名为mapred-site.xml)添加
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- yarn-site.xml 添加:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>
启动hadoop集群
在master主机上执行如下命令:
cd /usr/local/hadoop
bin/hdfs namenode -format
sbin/start-all.sh
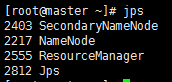
运行后,在master,slave01,slave02运行jps命令,查看:
master运行jps后,如下图:
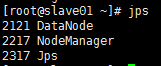
slave01、slave02运行jps,如下图:
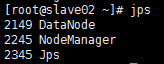
至此hadoop集群已经搭建好了。
注意:日后,启动hadoop之前先在master窗口输入start-all.sh,然后再输入jps看看hadoop是不是启动了。