将不同的分类器组合起来,这种组合方法称为集成方法。使用集成方法时会有多种形式,可以是不同分类器的集成,也可以是数据集不同部分分给不同分类器之后的集成。下面介绍两种数据集不断变化分类器不变的集成方法。
1、bagging:基于数据随机抽样的分类器构建方法
设原数据集M个,从原始数据集中有放回的随机抽取M个新的数据集,由于是有放回的抽取,所以抽取的M个新数据集中可能有重复的数据,将新数据集应用到分类器上。bagging的思想就是抽取多组数据应用到多个分类器上即训练多个分类器,再根据投票原则得到最终分类结果(投票原则指的根据所有分类器的结果进行投票,如假设有10个分类器,对于一个新来的数据,其中7个分类器将其判断为1,3个分类器判断为-1,则该数据的类别就为1)。
2、boosting:bagging是各分类器之间是串行训练的,相互之间无关,而且权重相等;而boosting各分类器之间是并行训练的,它是关注被已有的分类器错分的那些数据来获得新的分类器,并且对每个分类器分配不同的权重,每个权重代表的是该分类器对这一轮分类的成功度。其中最经典最流行的boosting集成方法是AdaBoost(adaptive boosting)
AdaBoost集成算法原理:能否用多个弱分类器来构建一个强分类器,这里的弱意味着分类器的性能比随机猜测要略好。AdaBoost就是基于该思想发展起来的一种最流行的集成算法。训练数据中的每个样本,并赋予一个权重,一开始这些权重初始化成相等值,在分类器上训练出一个弱分类器并计算该分类器的错误率。然后在同一数据集上再次训练弱分类器,在分类器的第二次训练当中,将会重新调整每个样本的权重,其中第一次分对的样本的权重将会降低,而第一次分错的样本的权重将会提高。为了从所有弱分类器中得到最终的分类结果,AdaBoost为每个分类器都分配了一个权重值alpha,这些alpha值是基于每个弱分类器的错误率进行计算的。

![]()
![]()
![]()
![]() 其中
其中![]() 为真实值,
为真实值,![]() 为预测值
为预测值
1、构建单层决策树
#构造简单数据集
import numpy as np
def loadSimData():
dataArr = np.array([[1,2.1],[2,1.1],[1.3,1],[1,1],[2,1]])
classLabels = [1,1,-1,-1,1]
return dataArr,classLabels
#画出正反例
import matplotlib.pyplot as plt
dataArr,classLabels = loadSimData()
plt.scatter(dataArr[2:4,0],dataArr[2:4,1],s=50,c='red',marker='s')
plt.scatter(dataArr[0:2,0],dataArr[0:2,1],s=50,c='green',marker='o')
plt.scatter(dataArr[4,0],dataArr[4,1],s=50,c='green',marker='o')
#dataArr为数据集,dimen为特征维数,threshVal为阈值,threshIneq可以在大于、小于之间切换
def stumpClassify(dataArr,dimen,threshVal,threshIneq):
dataMat = np.mat(dataArr)
retMat = np.mat(np.ones([dataMat.shape[0],1]))#将初始标签都置为1
if threshIneq == 'forward':
retMat[dataMat[:,dimen]<=threshVal] = -1.0#小于等于阈值为-1
else:
retMat[dataMat[:,dimen]>threshVal] = -1.0#大于阈值为-1
return retMat#dataArr微数据集,classLabels为数据标签,D为权重向量
def buildStump(dataArr,classLabels,D):
dataMat = np.mat(dataArr);labelMat = np.mat(classLabels).T#将数组ndarray格式转化为矩阵格式
m,n = dataMat.shape
numSteps = 10.0;bestStump = {};bestClassEstimate = np.mat(np.zeros([m,1]))
minErrRate = np.inf#将最小错误率初始值设为无穷大,以便下面寻找最小错误率
for i in range(n):#在所有维数即所有特征上循环
rangeMin = dataMat[:,i].min();rangeMax = dataMat[:,i].max()
stepSize = (rangeMax - rangeMin)/numSteps
for j in range(-1,int(numSteps+1)):#在当前维数即当前特征上遍历所有阈值
for inequal in ['forward','reverse']:#在大于小于之间切换,即大于阈值为正例还是负例之间切换
threshVal = rangeMin + float(j)*stepSize
predictClass = stumpClassify(dataArr,i,threshVal,inequal)
#构建一个列向量errArr,如果predictClass中的值不等于labelMat中的值,那么errArr相应中的值为1,相等置为0
errArr = np.mat(np.ones([m,1]))
errArr[predictClass==labelMat] = 0
weightError = D.T*errArr#相当于计算分类错误率
# print("split:dim %d,thresh:%.2f,inequal:%s,weightError:%.2f"%(i,threshVal,inequal,weightError))
if weightError<minErrRate:
minErrRate = weightError
bestClassEstimate = predictClass.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['inequal'] = inequal
return bestStump,minErrRate,bestClassEstimate
D = np.mat(np.ones([5,1])/5)
buildStump(dataArr,classLabels,D)

2.基于单层决策树的Adaboost训练过程
#其中Iter为迭代次数
def adaBoostTrain(dataArr,classLabels,Iter):
weakClassify = []#创建一个弱分类器列表,用于存放弱分类器
m = dataArr.shape[0]#样本数量
D = np.mat(np.ones([m,1])/m)#初始化样本权重向量
aggClassEsti = np.mat(np.zeros([m,1]))#记录每个数据点的估计累计值
for i in range(Iter):
bestStump,minErrRate,bestClassEstimate = buildStump(dataArr,classLabels,D)
#print("D:",D.T)
alpha = 0.5*np.log((1-minErrRate)/max(minErrRate,np.exp(-16)))#分配该弱分类器的权重alpha
alpha = float(alpha)#上面得到的alpha为一个矩阵形式
bestStump['alpha'] = alpha
weakClassify.append(bestStump)#存储弱分类器
#print("estimate:",bestClassEstimate.T)
#为下一次迭代做准备,重新分配样本权重向量,上一次分对的样本权重将会减小,分错的样本权重将会增大
expon = np.multiply(-alpha*np.mat(classLabels).T,bestClassEstimate)
D = np.multiply(D,np.exp(expon))
D = D/D.sum()
aggClassEsti += alpha*bestClassEstimate#记录每个数据点的估计累计值
# print("aggClassEsti",aggClassEsti.T)
retMat = np.mat(np.zeros([m,1]))
retMat[np.sign(aggClassEsti)!=np.mat(classLabels).T] = 1#为了得到二分类结果需要用到硬极限函数
errRate = retMat.sum()/m#错误率
print("total errRate:",errRate)
if errRate == 0:break
return weakClassify,aggClassEsti
weakClassify,aggClassEsti = adaBoostTrain(dataArr,classLabels,40)
3.测试算法:基于AdaBoost的分类
def adaboostClassify(data,weakClassify):
m = data.shape[0]
aggClassEst = np.mat(np.zeros([m,1]))
for i in range(len(weakClassify)):
classEst = stumpClassify(data,weakClassify[i]['dim'],weakClassify[i]['thresh'],weakClassify[i]['inequal'])
aggClassEst += weakClassify[i]['alpha']*classEst
#print(aggClassEst)
return np.sign(aggClassEst)
adaboostClassify(np.array([[0,0]]),weakClassify)
>>matrix([[-1.]])4.在一个难数据集上应用Adaboost
#这里将在马疝病数据集上应用AdaBoost分类器,前面曾经用过逻辑回归预测患有疝病的马是否能够存活,
#这里想知道利用多个单层决策树和Adaboost能不能预测得更准
#1.自适应加载数据
def loadDataSet(filename):
numFeat = len(open(filename).readline().split('\t'))#自动检测出特征数,假定最后一个为类别标签
dataList = [];labelList = []
fr = open(filename)
for line in fr.readlines():
lineArr = []
curLine = line.split('\t')
for i in range(numFeat-1):
lineArr.append(float(curLine[i]))
dataList.append(lineArr)
labelList.append(float(curLine[-1]))
return dataList,labelList
trainData,trainLabel = loadDataSet('horseColicTraining2.txt')
dataArr2 = np.array(trainData)
weakClassify,aggClassEsti = adaBoostTrain(dataArr2,labelList,Iter = 10)
>>total errRate: 0.2842809364548495
>>total errRate: 0.2842809364548495
>>total errRate: 0.24749163879598662
>>total errRate: 0.24749163879598662
>>total errRate: 0.25418060200668896
>>total errRate: 0.2408026755852843
>>total errRate: 0.2408026755852843
>>total errRate: 0.22073578595317725
>>total errRate: 0.24749163879598662
>>total errRate: 0.23076923076923078#在测试集上测试
testData,testLabel = loadDataSet('horseColicTest2.txt')
testArr = np.array(testData)
predictLabel = adaboostClassify(testArr,weakClassify)
m = testArr.shape[0]
errNum = np.mat(np.zeros([m,1]))
errNum[predictLabel!=np.mat(testLabel).T] = 1
print('the rate of error is %.2f'%(errNum.sum()/m))
>>the rate of error is 0.245、模型性能评估
5.1 混淆矩阵:
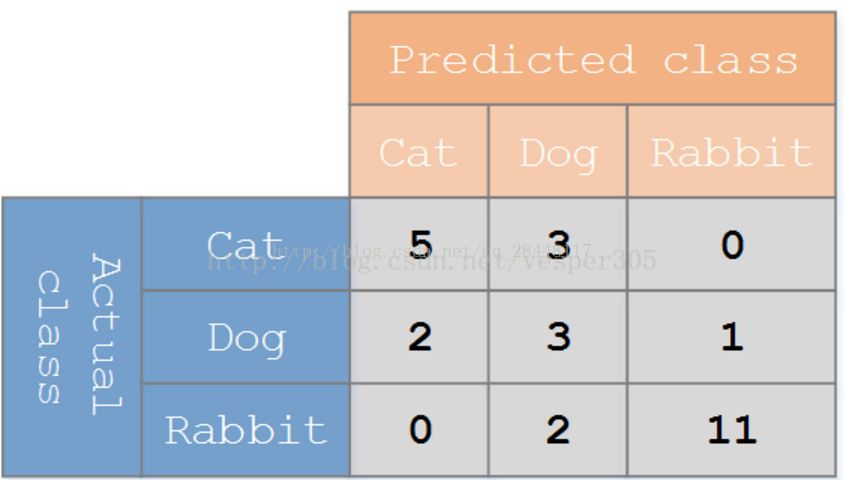
利用混淆矩阵就可以更好地理解分类中的错误了,如上表共有8只猫,五只预测对了,3只预测成了构;狗共有6只,3只预测对了,2只预测成了猫,1只预测成了兔子;兔子共有13只,11只预测对了,2只预测成立狗。如果矩阵中的非对角元素均为0,就会得到一个完美的分类器。
5.2、正确率、召回率及ROC曲线
正确率 = TP/(TP+FP):指的是预测为正例样本中的真正正例的比例
召回率 = TP/(TP+FN):指的是预测为正例的真实正例占所有真实正例的比例
ROC:ROC曲线横轴为假阳率(假阳率=FP/(FP+TN)),纵轴为真阳率(真阳率=TP/(TP+FN))。ROC曲线给出的是当阈值变化时假阳率和真阳率的变化情况。在理想的情况下,最佳的分类器应该尽可能地处于左上角,这就意味着分类器的假阳率很低的同时获得了很高的真阳率。对不同ROC曲线进行比较的一个指标是曲线下的面积(Area Unser the curve,AUC)。AUC给出的是分类器的平均性能值,一个完美分类器的AUC为1。