版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/cuixing001/article/details/80920259
adaboost是机器学习中经典的分类算法,也是面试中常被问到典型算法。由于该算法原理的文章铺天盖地,在此博客不具体陈述,若有需要请点这里查看详细过程。
本文侧重代码的精简和迭代过程的理解,数据来源以上博客,即对10个二维坐标数据点进行学习分类。
clc,clear;close all;
%% 训练样本数据
x=[1 5;2 2;3 1;4 6;6 8;6 5;7 9;8 7;9 8;10 2]; %样本数据点,对应编号为1,2,...10
y=[1 1 -1 -1 1 -1 1 1 -1 -1]'; %对应的样本类别,用1和-1表示
n = length(y);
%% 绘制样本分布图
figure;hold on;grid on;
plot(x(y==1,1),x(y==1,2),'b+','LineWidth',3,'MarkerSize',12);
plot(x(y==-1,1),x(y==-1,2),'ro','LineWidth',3,'MarkerSize',12);
legend('y=1','y=-1','location','northwest');title('原始数据分布')
%% adaboost核心算法
m = 50;
Y = zeros(n,n);yy= zeros(size(y));w= ones(n,1)/n;
X0= linspace(0,11,n);[X(:,:,1),X(:,:,2)] = meshgrid(X0);
for j = 1:m
wy = w.*y; d = ceil(2*rand);[xs,xi]=sort(x(:,d));
el = cumsum(wy(xi)); eu = cumsum(wy(xi(end:-1:1)));
e = eu(end-1:-1:1)-el(1:end-1);
[em,ei] = max(abs(e)); c = mean(xs(ei:ei+1)); s = sign(e(ei));
yh = sign(s*(x(:,d)-c)); R = w'*(1-yh.*y)/2;
t = log((1-R)/R)/2;yy = yy +yh*t; w = exp(-yy.*y);w = w/sum(w);
Y = Y+sign(s*(X(:,:,d)-c))*t;
end
%% 分类结果
figure;hold on;
colormap([1,0.7,1;0.7,1,1]);contourf(X0,X0,sign(Y));
plot(x(y==1,1),x((y==1),2),'bo','LineWidth',3,'MarkerSize',12);
plot(x(y==-1,1),x(y==-1,2),'rx','LineWidth',3,'MarkerSize',12);
title('剪枝分类器的组合')
原始10个点类型分布图如图1所示:
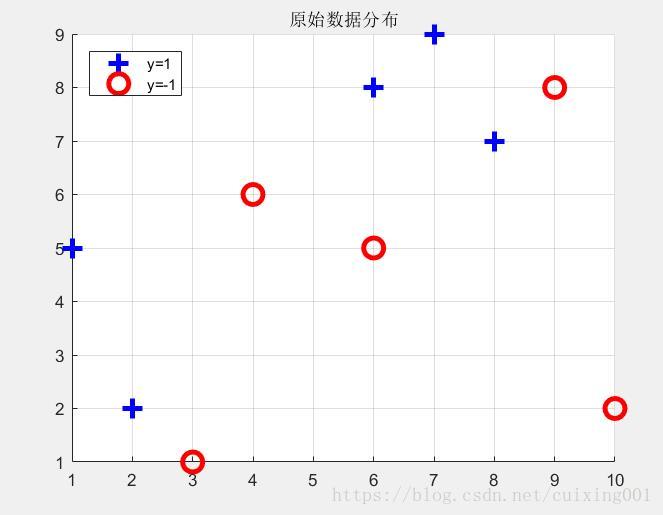
图1 原始数据分布
改写上面代码m=1,即一次迭代,剪枝分类区域如图2所示。
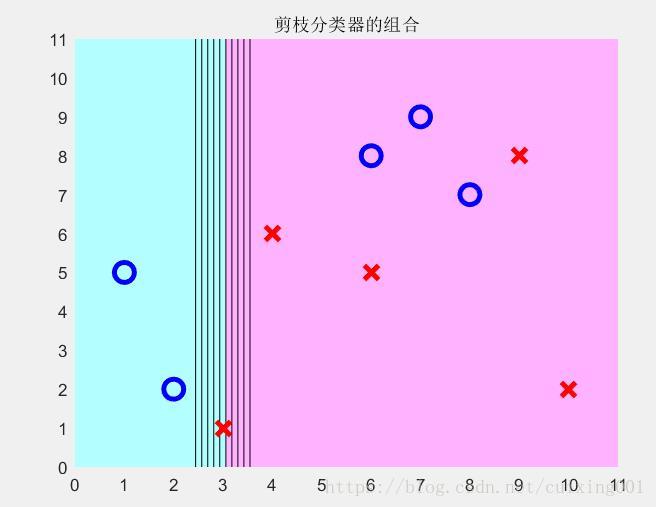
图2 m=1情况
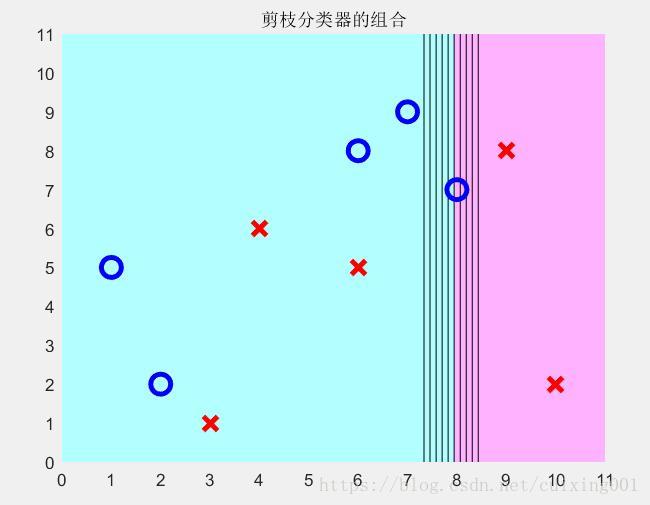
图3 m=2情况
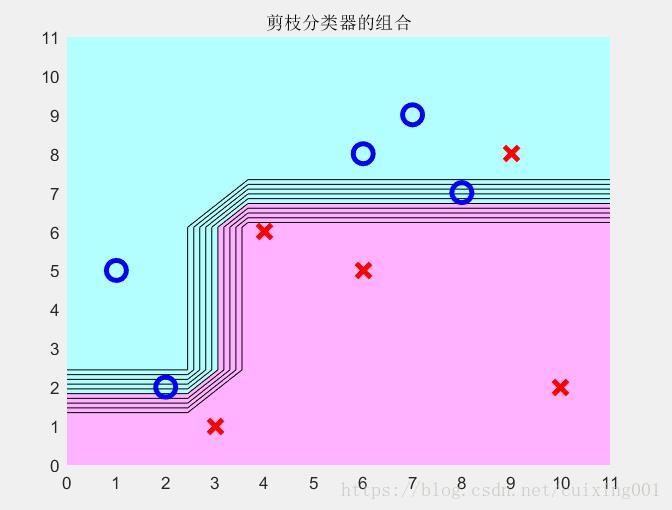
图4 m=3情况
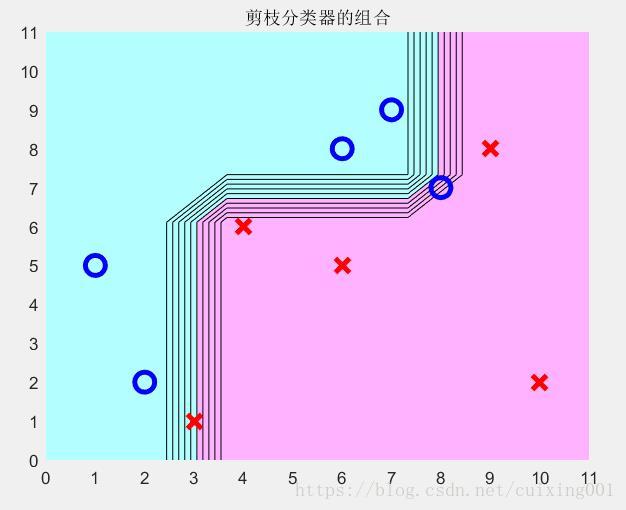
图5 m=50情况
注意,由于算法程序有一定的随机性,m比较小时每次剪枝分类器区域略有不同,当m比较大时候,区域稳定分割。图5是m=50的结果图,图中比较明显的看到数据被分类分布的情况。