基本步骤流程 :
- 计算给定数据的原始熵
- 划分数据集
- 选择最好的特征划分数据集
- 构建树的结构
- 使用决策树执行分类
- 决策树的存储和调用
- 绘制树形图
决策树:是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶子节点代表一种类别。
- 优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以知道哪些特征重要哪些不太重要
- 缺点:可能会产生过度匹配问题

划分数据的原则是:将无序的数据变得更加有序。那么怎么衡量一堆数据的混乱程度呢,信息论之父克劳德.香农提出了熵,也叫作香农熵。计算公式为,当为确定事件时,即概率为0或1时,熵都为0,说明此时数据是有序的,类别是确定的。
信息增益 = 原始熵 - 划分后数据熵,信息增益越大,说明划分后数据熵越小,即划分后数据更有序, 说明这个特征越好越重要,越能够分类。
克劳德.香农被公认为是二十世纪最聪明的人之一,贝尔实验室和MIT有很多人将香农和爱因斯坦相提并论,而其他人则认为这种对比是不公平的——对香农是不公平的。熵这个词其实是冯.诺依曼建议使用的,他建议的理由是因为大家从来没听过这个词,不知道它是什么意思。
下面以海洋生物数据为例,实现决策树从原理到算法的实现:
海洋生物数据
| 不浮出水面是否可以生存 | 是否有脚蹼 | 是否属于鱼类 | |
| 1 | 是 | 是 | 是 |
| 2 | 是 | 是 | 是 |
| 3 | 是 | 否 | 否 |
| 4 | 否 | 是 | 否 |
| 5 | 否 | 是 | 否 |
1.计算给定数据的原始熵
import numpy as np
import math
from math import log
def shannonEntropy(dataSet):
num = len(dataSet)
classCount = {}
for a in dataSet:
label = a[-1]#最后一列为类别标签
classCount[label] = classCount.get(label,0)+1
shangnon = 0.0
for key in classCount:
prob = float(classCount[key])/num
shangnon += -prob*log(prob,2)#香农熵计算公式
return shangnon
dataSet = [[1,1,'yes'],
[1,1,'yes'],
[1,0,'no'],
[0,1,'no'],
[0,1,'no']]
shangnon = shannonEntropy(dataSet)
shangnon
运行结果:0.9709505944546686
2.划分数据集
def splitDataSet(dataSet,feature_index,feature_value):
subDataSet = []
for b in dataSet:
if b[feature_index]==feature_value:
temp = b[:feature_index]#注意这里不能直接用del删除而应该用切片,用del原数据集会改变
temp.extend(b[feature_index+1:])
subDataSet.append(temp)
return subDataSet
splitDataSet(dataSet,0,1)#以第一个特征划分,如果数据集中样本第一个特征为1,则去掉第一个特征,保留其它特征和类别标签
运行结果:[[1, 'yes'], [1, 'yes'], [0, 'no']]3.选择最好的特征划分数据集(即选择根节点)
def selectRootNode(dataSet):
baseEntropy = shannonEntropy(dataSet)#计算原始香农熵
numFeatures = len(dataSet[0])-1#特征个数
maxInfoGain = 0.0;bestFeature = 0
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqVals = set(featList)
newEntropy = 0.0
for j in uniqVals:
subDataSet = splitDataSet(dataSet,i,j)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * shannonEntropy(subDataSet)
infoGain = baseEntropy - newEntropy#信息增益
if(infoGain>maxInfoGain):
maxInfoGain = infoGain
bestFeature = i
return bestFeature
selectRootNode(dataSet)
运行结果:04.构建树的结构
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
bestFeat = selectRootNode(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del labels[bestFeat]
featValues = [example[bestFeat] for example in dataSet]
uniqValues = set(featValues)
for i in uniqValues:
subLabels = labels[:]
myTree[bestFeatLabel][i] = createTree(splitDataSet(dataSet,bestFeat,i),subLabels)
return myTree
labels = ['no surface','flippers']
myTree = createTree(dataSet,labels)
myTree
运行结果:{'no surface': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}5.使用决策树执行分类
def classifier(myTree,featLabels,testVec):
firstFeat = list(myTree.keys())[0]
secondDict = myTree[firstFeat]
featIndex = featLabels.index(firstFeat)
for key in secondDict.keys():
if testVec[featIndex] == key:
if type(secondDict[key]).__name__ == 'dict':
classLabel = classifier(secondDict[key],featLabels,testVec)
else:classLabel = secondDict[key]
return classLabel
featLabels = ['no surface','flippers']
testVec = [1,0]
classifier(myTree,featLabels,testVec)
运行结果:'no'6.决策树 的存储和调用
构造决策树是很耗时的任务,而用创建好的决策树来处理分类问题,则可以很快完成。因此,为了节约时间,将构造好的决策树保存起来,下次用的时候直接导进来调用就好了
#使用pickle模块将树结构保存成文件
def storeTree(myTree,filename):
import pickle
fw = open(filename,'wb')#以二进制形式写
pickle.dump(myTree,fw)
fw.close()
# 使用pickle模块导入树结构文件
def grabTree(filename):
import pickle
fr = open(filename,'rb')#以二进制形式读
return pickle.load(fr)
storeTree(myTree,'myTree.txt')
grabTree('myTree.txt')
运行结果:{'no surface': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}7.绘制树形图
7.1画sklearn包中自带的iris数据集的树形图
from sklearn.datasets import load_iris
from sklearn import tree
clf = tree.DecisionTreeClassifier()
iris = load_iris()
clf = clf.fit(iris.data, iris.target)安装Graphviz
#下载网站:http://www.graphviz.org/Download
#添加环境变量在系统环境变量path中将Graphviz的bin的目录路径添加上
#如果我们安装了Python模块pydotplus,我们可以直接在Python中生成PDF文件(或任何其他支持的文件类型)
#安装pydotplus在Anaconda Prompt中输入:conda install -c conda-forge pydotplus
#将树形图生成PDF文件
import pydotplus
dot_data = tree.export_graphviz(clf, out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("iris.pdf")
#通过Ipython生成渲染的树形图
from IPython.display import Image
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())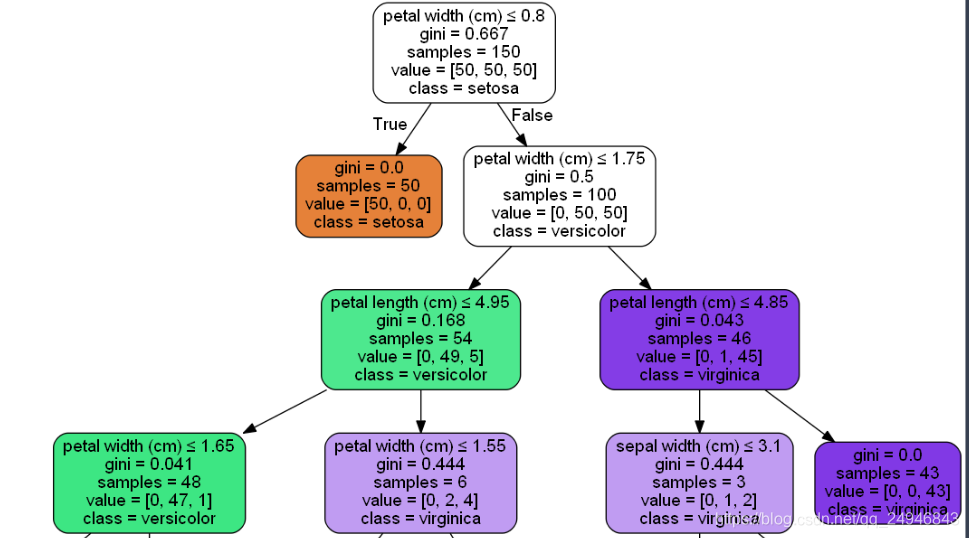
7.2.绘制海洋生物数据的树形图
#由上面例子画海洋生物数据树形图
from sklearn import tree
clf = tree.DecisionTreeClassifier()
data = np.array([[1,1],[1,1],[1,0],[0,1],[0,1]])
target =np.array(['yes','yes','no','no','no'])
clf = clf.fit(data,target)
import pydotplus
dot_data = tree.export_graphviz(clf, out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("fish.pdf")
#仿照iris画海洋生物数据的渲染树形图
from IPython.display import Image
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=['no face','flipper'],
class_names = ['no','yes'],
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())